int:表示数字,1,2,3
bool:布尔值,分为 True,False,用于用户进行判断
str:字符串,存储少量数据,用于操作
list:列表,用于储存大量数据,可以是数字、字符串、列表、元祖
元祖:也叫只读列表,只能对数据进行读取
dict:字典,存储成对的数据,可以根据索引读取数据
集合:
基础数据类型方法
int:
bit_length():当十进制用二进制表示时,最少使用的位数
v=11
print(v.bit_length())
结果如下:

字符串的索引和切片
a=‘abcdefghijklmnopkrstuvwxyz‘ print(a[0]) print(a[1]) print(a

这是字符串的索引
字符型串的切片:通过索引[首:尾:步长]截取其中的某一段字符,形成新的字符串(顾头不顾腚)
print(a[0:4]) print(a[0::2]) print(a[::]) print(a[::-2])
运行结果如图

字符串方法:
1、capitalize 首字母大写
s=‘alexwusir‘ s1=s.capitalize() print(s1)
运行结果:

2、upper、lower 将英文全部大写、全部小写
s2=s.upper() print(s2) s3=s.lower() print(s3)
运行结果:

3、swapcase 大小写反转
s=‘alexWUSRItaiBAI‘ s4=s.swapcase() print(s4)
运行结果:

4、title 每个隔开(特殊字符或数字)的单词首字母大写
s=‘alex wusir jinxing‘ s1=‘aaa*bbb*ccc‘ s3=‘ccc2ddd?ggg9$hhhh‘ print(s.title()) print(s1.title()) print(s3.title())
运行结果:

5、center 居中,用需要的字符填充指定的长度
s = ‘aalexwusri‘ s1=s.center(20, ) print(s1) s2=s.center(20,‘~‘ ) print(s2) s3=s.center(20, ‘/‘) print(s3)
运行结果:

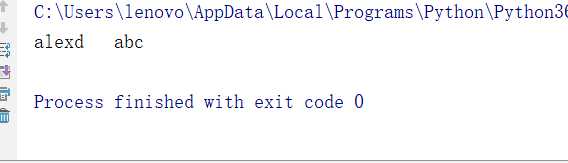
6、expandtabs:逢8位用空格补充剩下的内容
s=‘alexd\\tabc‘ s1=s.expandtabs() print(s1)
运行结果:
公共方法:
1、len()输出数量或者长度
s=‘alexd\\tabc‘ print(len(s))

2、startswith、endswith 判断是不是以某个元素开始、结束
s=‘alexd\\tabc‘
print(s.startswith(‘alex‘))
print(s.endswith(‘abc‘))
print(s.startswith(‘bbb‘))
运行结果:

3、find 通过元素找到该元素的索引,找不到索引返回-1,两个或两个以上的元素返回第一个元素的索引。
index(索引的意思):通过元素找索引,找不到会报错,两个或者两个以上返回第一个元素的索引 s.index(‘a’)
a=‘alex,wyx,wusir‘ print(a.find(‘wyx‘)) print(a.index(‘e‘)
运行结果:

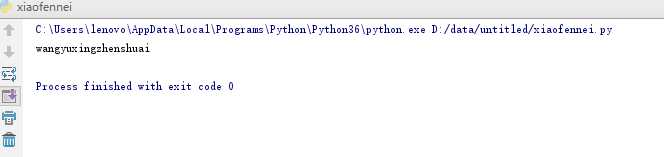
4、s.strip(*%):去除指定的符号(默认情况下去除字符串前后的空格,见到空格就删除),见到就删除。
a=‘* ,wangyuxingzhenshuai%%$‘
print(a.strip(‘%*$ ,‘))
5、count:统计指定元素个数
a=‘* ,wangyuxingzhenshuai%%$‘ a1=a.count(‘wa‘) print(a1)

6、split:将字符串以指定要求(括号中的元素)分割成列表
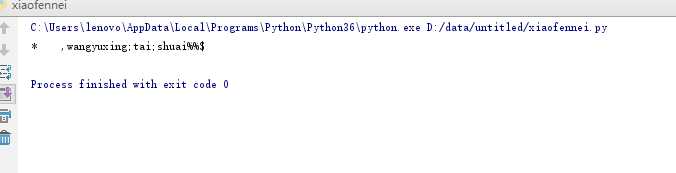
a=‘* ,wangyuxing;zhen;shuai%%$‘ a1=a.split(‘;‘) print(a1)

7、replace:替换,将括号中的内容替换原来指定的内容
a=‘* ,wangyuxing;zhen;shuai%%$‘ a1=a.replace(‘zhen‘,‘tai‘) print(a1)