非聚集索引和聚集索引
Posted 罗夏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了非聚集索引和聚集索引相关的知识,希望对你有一定的参考价值。
一.非聚集索引(MyISAM的索引方式):
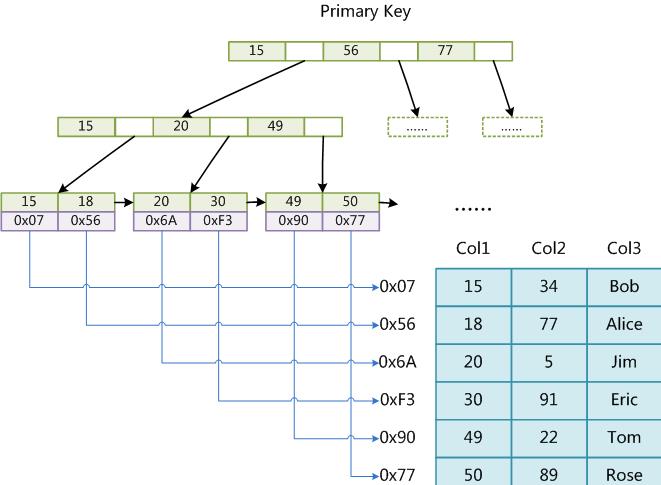
使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址.主键索引图:
辅助索引图:
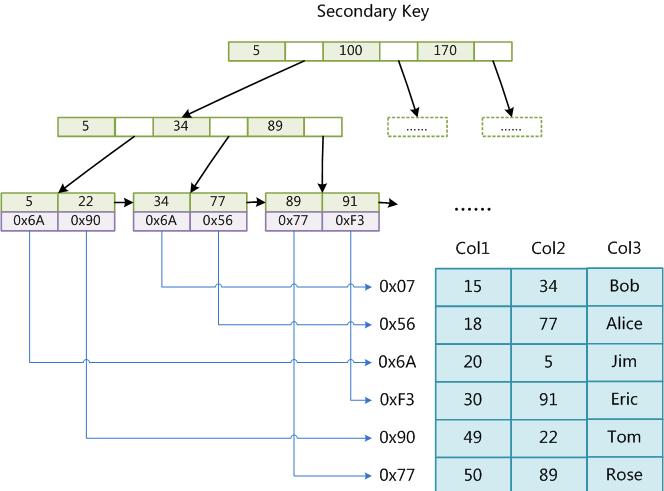
主键索引和辅助索引没有本质上的区别,data域都保存的是数据行的地址.
二.聚集索引(InnoDB的索引方式):
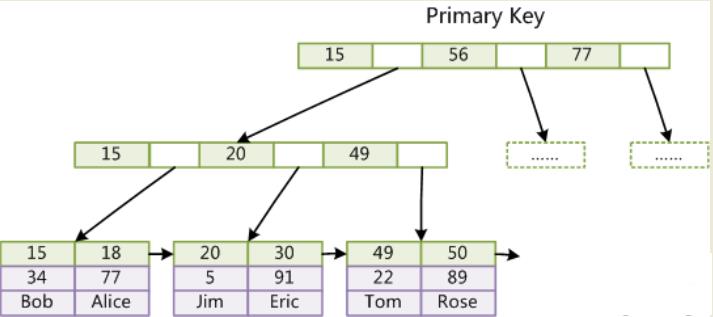
InnoDB的数据文件本身就是索引文件。在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
主键索引图:
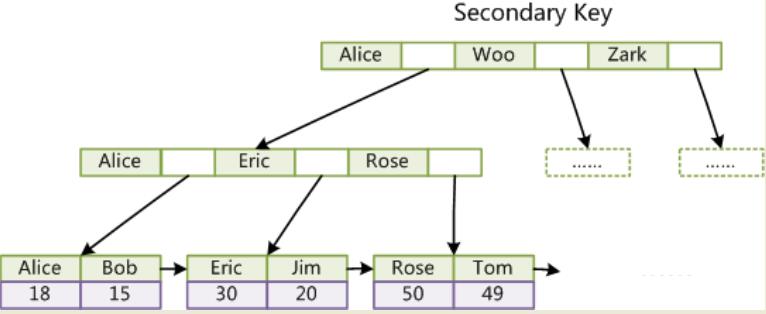
辅助索引:
InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域.
ps:
1.如果innodb表没有主键索引,innodb会自动找一个类似于此的唯一非空列,如果找不到,会增加一个隐藏列来做主索引.
2.Innodb中的每张表都会有一个聚集索引,而聚集索引又是以物理磁盘顺序来存储的,自增主键会把数据自动向后插入,避免了插入过程中的聚集索引排序问题。
其实到这儿,应该能明确一点,无论是MyISAM还是InnoDB,mysql都试图能建立起一种快速的数据查找方式.mysql利用B+Tree来解决这个问题.MyISAM只有索引文件是B+Tree方式来组织数据,数据文件并不是;所以对于MyISAM只将索引放入内存缓存;InnoDB因为数据文件本就是B+Tree方式组织,所以InnoDB是可以将索引和数据文件都放入内存;这就是为什么key_buffer_size对myisam至关重要;而innodb_buffer_size对innodb至关重要的原因.两者在解决数据快速访问的方式上是相同的.
三.覆盖索引
覆盖索引指的是数据的读取不必经过数据行,而是直接从索引中读取.对mysql,是效率最好的读取方式.
对于覆盖索引而言,myisam和innodb有截然不同的表现(非聚集索引和聚集索引)
建立表:
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`time` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`)
) ENGINE=MyISAM;
插入数据:
insert into test(time) values(1); insert into test(time) values(2);
我们来查询一条数据,看看mysql解释器表现:
mysql> explain select id from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+
注意Extra列,没有出现using index;也就是没有使用覆盖索引;这很好理解,因为非聚集索引,该查询先查询了time索引(或key cache),找到对应记录的地址,然后去数据行找数据了;mysql每次查询只能用到一个索引.
如果是以下语句,就用到了覆盖索引:
mysql> explain select time from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where; Using index | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
用到了time索引,只要求返回time列,不必去数据行找数据;直接从索引中找到数据返回;
现在我们将该表转为innodb,看看innodb的表现:
mysql> explain select id from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where; Using index | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
用到了覆盖索引.
mysql> explain select time from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where; Using index | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
以上是关于非聚集索引和聚集索引的主要内容,如果未能解决你的问题,请参考以下文章