ICLR 2018 大会的论文评审已经于 11 月 27 日截止。在明年 1 月 5 日之前,人们将对目前提交的论文进行讨论。根据评审得分,我们整理了排名前五的论文。目前,斯坦福大学探究神经网络对抗样本的论文 Certifiable Distributional Robustness with Principled Adversarial Training 名列第一。
今年的 ICLR 大会接收到了 981 篇有效论文。截至 12 月 1 日,有 979 篇论文至少经过了一次打分。近日,大会官方给出了论文双盲评审的评分结果。统计数据显示,平均分为 5.24,中位数为 5.33(满分 10 分)。
论文评分前一百名结果:http://search.iclr2018.smerity.com/
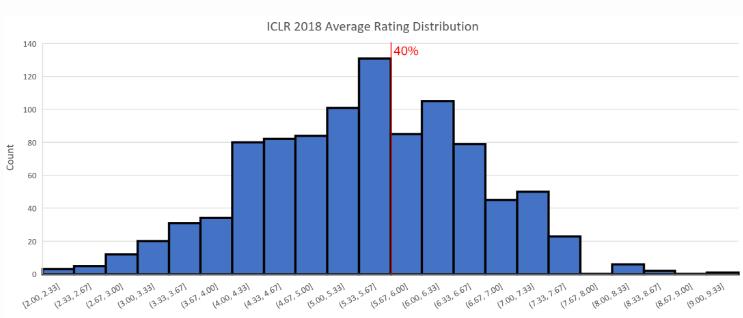
根据 Andrej Karpathy 的介绍,在今年 4 月的 ICLR 2017 大会上,提交论文的数量为 491 篇,而被接受的情况为:15 篇 oral(3%),183 篇 poster(37.3%)。所以上图中我们给出了 40% 的接收线作为参考。
分数分布
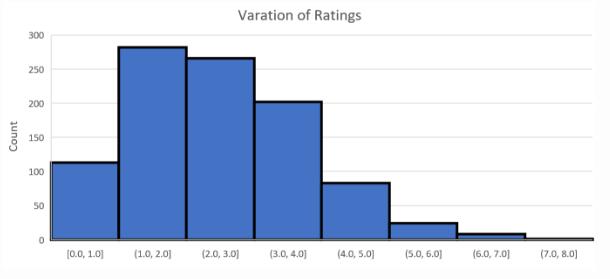
下图显示了相同论文得到评分的最大差值。我们观察到,对于大多数(约 87%)论文来说,最大差值小于 3。
论文得分 Top 10
在双盲评审打分过后,我们得到了十篇得分最高的论文。其中部分论文已在其他平台提交,因此我们可以得知其作者与研究机构了。
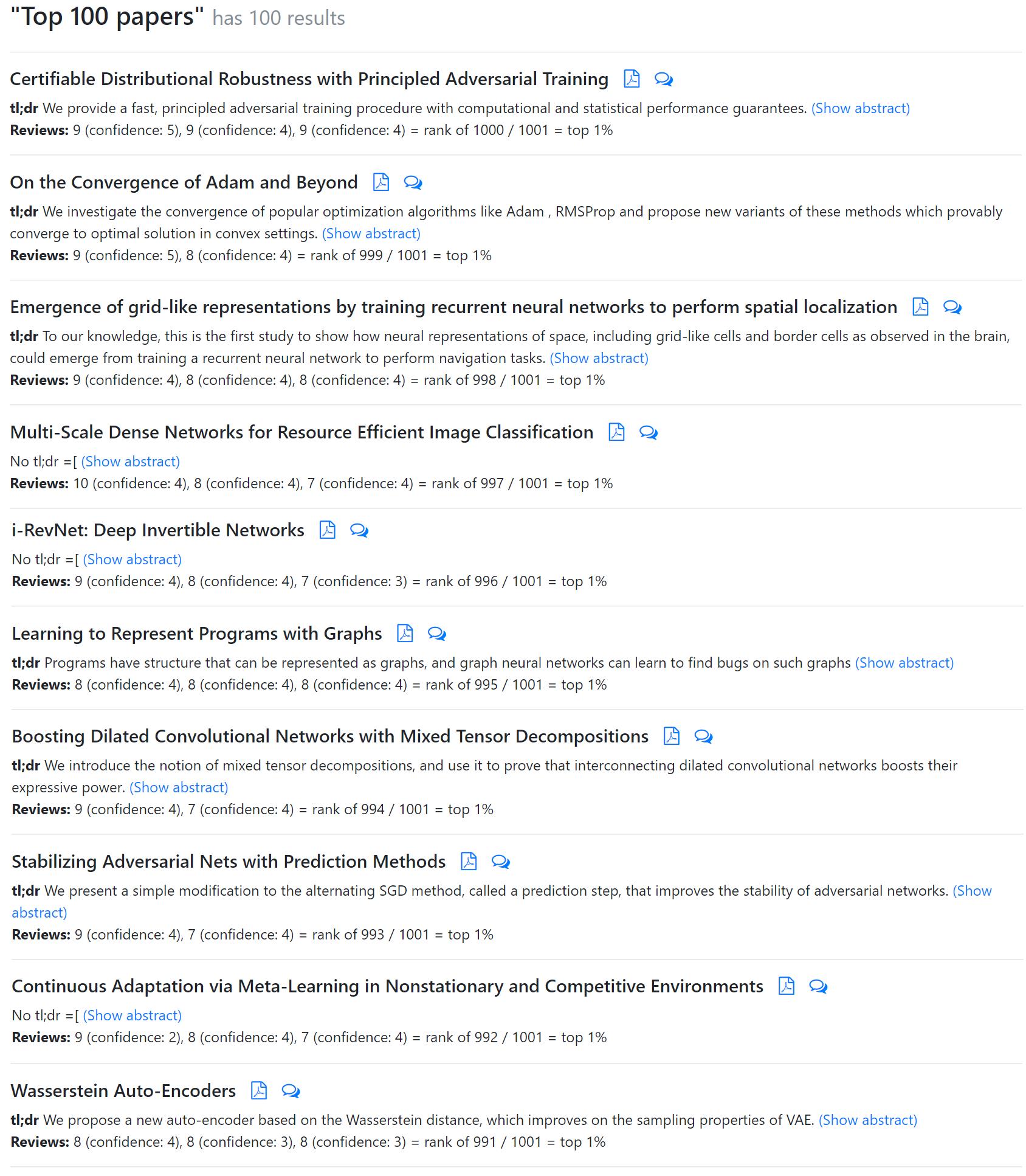
请注意,目前评审分数的提交尚未完全结束。现在评分最高的论文是斯坦福大学 Aman Sinha 等人的 Certifiable Distributional Robustness with Principled Adversarial Training。另有一篇值得注意的论文,英伟达 Tero Karras 等人的 Progressive Growing of GANs for Improved Quality, Stability, and Variation。收到了 8,8,1 的评分。此外,我们比较关注的第二篇 Capsule 论文:Matrix capsules with EM routing 并没有太高的评分,该论文目前的评分大约在前 40% 左右。
下面,我们将简要介绍目前 ICLR 2018 大会评审中排名前五的论文。
论文 1:Certifiable Distributional Robustness with Principled Adversarial Training

链接:https://arxiv.org/pdf/1710.10571.pdf
摘要:神经网络很容易受到对抗样本的干扰,因此研究人员提出了许多启发式的攻击与防御机制。我们采取了分布式鲁棒优化的原则,以保证模型在对抗性扰动输入的条件下保持性能。我们通过给予 Wasserstein ball 上的潜在数据分布一个扰动来构建 Lagrangian 罚项,并且提供一个训练过程以加强模型在最坏的训练数据扰动情况下能持续正确地更新参数。对于平滑的损失函数,我们的过程相对于经验风险最小化可以证明有适度的鲁棒性,且计算成本或统计成本也相对较小。此外,我们的统计保证允许我们高效地证明总体损失的鲁棒性。因此,该研究结果至少匹配或超越监督学习和强化学习任务中的启发式方法。
如下所示,鲁棒性的模型在原版的马尔科夫决策过程(MDP)中要比一般的模型学习更高效:
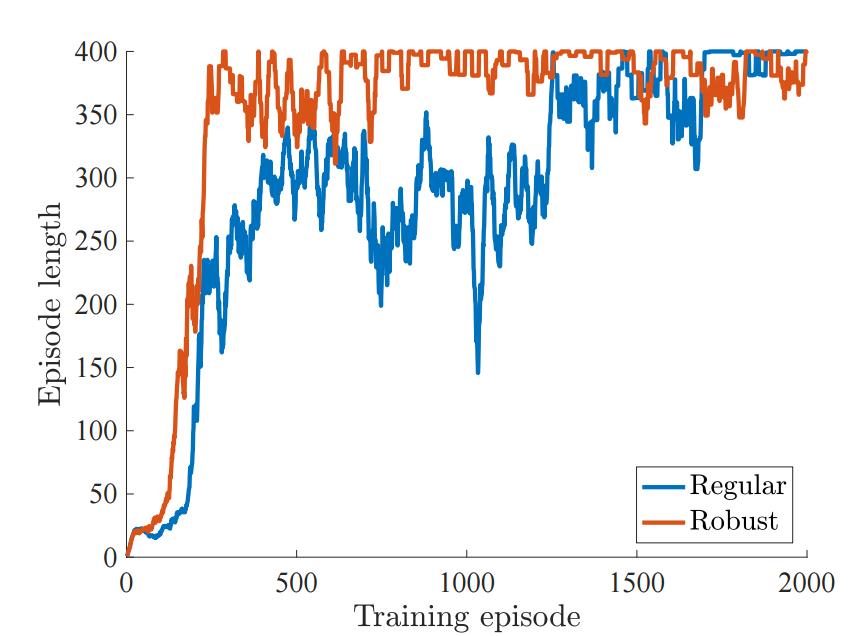
图 4:训练中 Episode 的长度,其中环境设置最大为 400 Episode 的长度。
论文 2:ON THE CONVERGENCE OF ADAM AND BEYOND

链接:https://openreview.net/pdf?id=ryQu7f-RZ
摘要:近来提出的几种随机优化方法已经成功地应用于深度网络的训练,如 RMSPROP、ADAM、ADADELTA 和 NADAM 等方法,它们都是基于使用前面迭代所产生梯度平方的指数滑动平均值,在对该滑动平均值取平方根后用于缩放当前梯度以更新权重。根据经验观察,这些算法有时并不能收敛到最优解(或非凸条件下的临界点)。我们证明了导致这样问题的一个原因是这些算法中使用了指数滑动平均(exponential moving average)操作。本论文提供了一个简单的凸优化案例,其中 ADAM 方法并不能收敛到最优解。此外,我们还描述了过去文献中分析 ADAM 算法所存在的精确问题。我们的分析表明,收敛问题可以通过赋予这些算法对前面梯度的「长期记忆」能力而得到解决。因此本论文提出了一种 ADAM 算法的新变体,其不仅解决了收敛问题,同时还提升了经验性能。
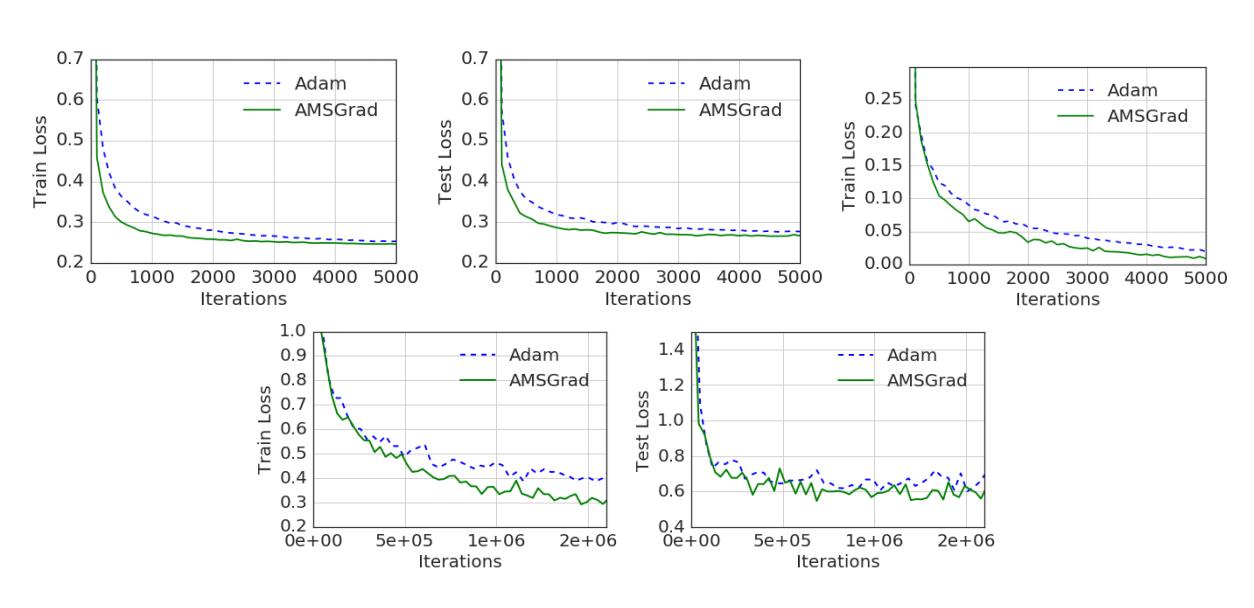
图 2:ADAM 和 AMSGRAD 算法在 Logistic 回归、前馈神经网络和 CIFARNET 上的性能对比。
论文 3:Emergence of grid-like representations by training recurrent neural networks to perform spatial localization

链接:https://openreview.net/pdf?id=B17JTOe0-
摘要:几十年来关于空间导航的神经编码研究揭示了一系列不同的神经反应特性。哺乳动物大脑的内嗅皮层(Entorhinal Cortex/EC)含有丰富的空间关联性,包括网格细胞(grid cell)使用完全嵌入模式(tessellating patterns)编码空间。然而,这些空间表征的机制和功能仍然非常神秘。作为理解这些神经表征的新方法,我们训练一个循环神经网络(RNN),以在基于速率输入的二维环境下执行导航任务。令人惊讶的是,我们发现类网格(grid-like)响应模式出现在训练后的网络中,它和其它空间相关的单元(包括边缘(border cell)和带状细胞)一同出现。所有这些不同的功能性神经元都已经在实验中观察到。网格状和边缘细胞出现的顺序也与发育性研究的观察一致。总之,我们的结果表明,在 EC 中观察到的网格细胞、边缘细胞等可能是用于高效表示空间的自然解决方案,它们在神经回路中给出了主要的循环连接。
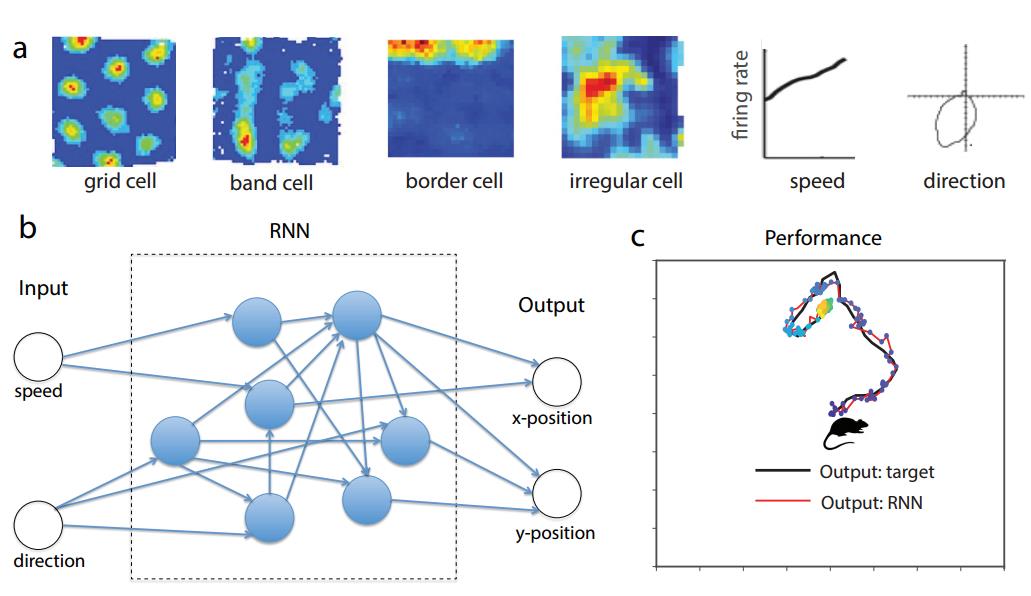
图 1:其中 a)为样本神经数据表示 EC 空间导航任务中不同神经关联性。b)中的循环网络由 N = 100 个循环单元(或神经元)组成,它们接收两个外部输入,即代表动物的速度和方向。c)为训练后的典型轨迹,RNN 的输出可以精确地在导航期间追踪动物的位置。
论文 4:MULTI-SCALE DENSE NETWORKS FOR RESOURCE EFFICIENT IMAGE CLASSIFICATION

链接:https://arxiv.org/pdf/1703.09844.pdf
摘要:在本论文中,我们探究了图像分类任务在给定时间内的计算资源消耗。实验的两个设定为:1. 即时分类,其中网络预测的示例图会逐渐更新,以保证随时输出预测结果;2. 批预算分类,其中计算资源是有限的,而输入的示例图片存在「简单的」和「困难的」。与大多数先前的工作相比(如流行的 Viola 和 Jones 算法)我们的方法基于卷积神经网络。我们训练多个具有不同资源需求的分类器,并在测试期间自适应地应用这些分类器。为了最大化这些分类器计算资源的使用效率,我们将它们整合进一个深度卷积神经网络中,使用密集连接将它们联通。为了更快实现高质量的分类,我们使用了二维混合比例网络架构,在整个网络中保持了粗糙与精细的特征。三个图像分类任务的实验证明,我们的框架可以大大提升两种设置目前的业内最佳水平。
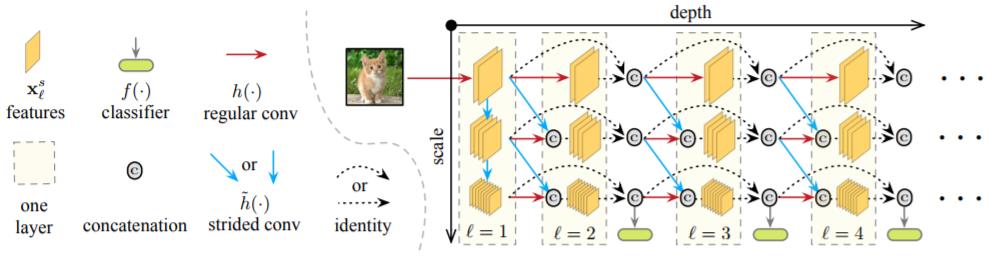
图 2:具有三个比例的 MSDNet 的前四层图示。水平方向对应于网络的层方向(深度),垂直方向对英语特征图的比例。水平箭头表示常规卷积操作,而对角线和垂直箭头表示步进卷积操作。分类器仅在最粗糙比例的特征映射上运行。跨越超过一层的连接未明确绘制:它们隐藏地通过递归串联。
论文 5:i-RevNet: Deep Invertible Networks

链接:https://openreview.net/forum?id=HJsjkMb0Z
摘要:人们普遍认为,目前深度卷积神经网络的成功是建立在逐步抛弃输入中对于当前问题无意义的变化而实现的。在大多数常用的网络体系结构中,从隐藏表示中恢复图像的难度获得了实践的证明。在本论文中,我们展示了这种信息损失并不是学习表示如何在 ImageNet 等复杂问题上得到通用性的必要条件。通过一系列的同胚层,我们构建了 i-RevNet 网络——一个可以被完全倒置,直到最终投影到类上的网络,在处理过程中没有信息被丢弃。建立一个可逆的架构是困难的,例如局部倒转是非常困难的,我们通过提供明确的反转来克服这个问题。对于 i-RevNet 的学习表征过程的分析证明了它可以通过渐进收缩和线性分离深度得到很高的准确性。此外,为了解释由 i-RevNet 学习到的模型的性质,我们重建了自然图像表示之间的线性插值。
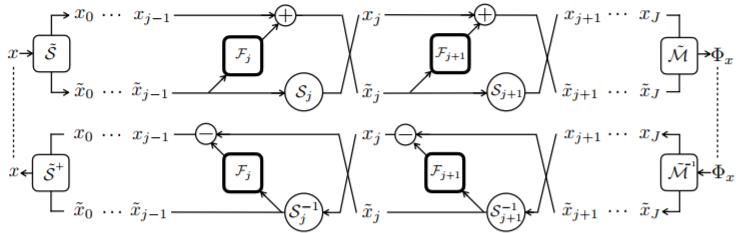
i-RevNet 及其伪逆结构
ICLR 2018 将于 4 月 30 日-5 月 3 日于加拿大温哥华的 Vancouver Convention Center 举行。机器之心将持续跟进本次大会的相关信息。
参考内容:https://liyaguang.github.io/iclr2018-stats
以上是关于ICLR 2018论文评审结果出炉:一文概览论文 TOP 5的主要内容,如果未能解决你的问题,请参考以下文章
近期必读的五篇ICLR 2021图神经网络(GNN)相关论文和代码