Deep Learning之感知器
Posted Ariel_一只猫的旅行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Learning之感知器相关的知识,希望对你有一定的参考价值。
What is deep learning?
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。神经网络如下图所示:
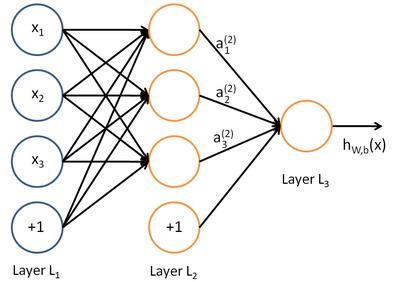
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。最左边的层叫做输入层,这层负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层。
隐藏层比较多(大于2)的神经网络叫做深度神经网络。而深度学习,就是使用深层架构(比如,深度神经网络)的机器学习方法。
那么深层网络和浅层网络相比有什么优势呢?简单来说深层网络能够表达力更强。事实上,一个仅有一个隐藏层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。而深层网络用少得多的神经元就能拟合同样的函数。也就是为了拟合一个函数,要么使用一个浅而宽的网络,要么使用一个深而窄的网络。而后者往往更节约资源。
深层网络也有劣势,就是它不太容易训练。简单的说,你需要大量的数据,很多的技巧才能训练好一个深层网络。这是个手艺活。
感知器
为了理解神经网络,我们应该先理解神经网络的组成单元——神经元。神经元也叫做感知器。感知器算法在上个世纪50-70年代很流行,也成功解决了很多问题。并且,感知器算法也是非常简单的。
感知器的定义
下图是一个感知器:
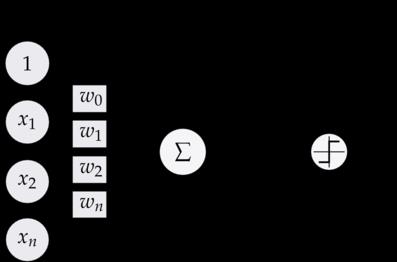
可以看到,一个感知器有如下组成部分:

用一个简单的例子来帮助理解:
例子:用感知器实现and函数
我们设计一个感知器,让它来实现and运算。程序员都知道,and是一个二元函数(带有两个参数和),下面是它的真值表:

为了计算方便,我们用0表示false,用1表示true。这没什么难理解的,对于C语言程序员来说,这是天经地义的。

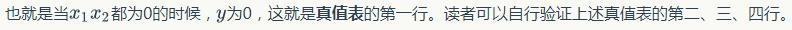
例子:用感知器实现or函数
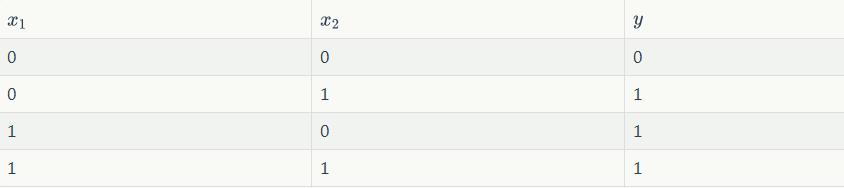
同样,我们也可以用感知器来实现or运算。仅仅需要把偏置项b的值设置为-0.3就可以了。我们验算一下,下面是or运算的真值表:

感知器还能做什么
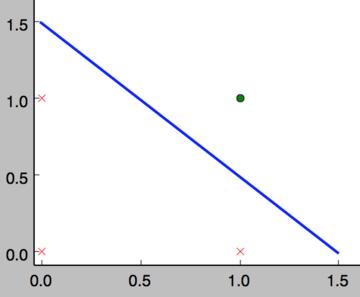
事实上,感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。如下面所示,and运算是一个线性分类问题,即可以用一条直线把分类0(false,红叉表示)和分类1(true,绿点表示)分开。
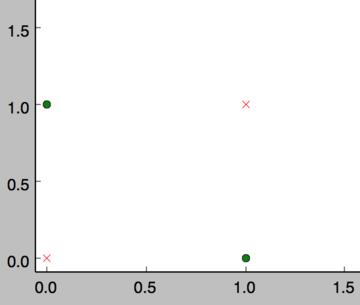
然而,感知器却不能实现异或运算,如下图所示,异或运算不是线性的,你无法用一条直线把分类0和分类1分开。
感知器的训练

每次从训练数据中取出一个样本的输入向量x,使用感知器计算其输出y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
编程实战:实现感知器
完整代码请参考GitHub: https://github.com/hanbt/learn_dl/blob/master/perceptron.py (python2.7)
对于程序员来说,没有什么比亲自动手实现学得更快了,而且,很多时候一行代码抵得上千言万语。接下来我们就将实现一个感知器。
下面是一些说明:
- 使用python语言。python在机器学习领域用的很广泛,而且,写python程序真的很轻松。
- 面向对象编程。面向对象是特别好的管理复杂度的工具,应对复杂问题时,用面向对象设计方法很容易将复杂问题拆解为多个简单问题,从而解救我们的大脑。
- 没有使用numpy。numpy实现了很多基础算法,对于实现机器学习算法来说是个必备的工具。但为了降低读者理解的难度,下面的代码只用到了基本的python(省去您去学习numpy的时间)。
下面是感知器类的实现,非常简单。去掉注释只有27行,而且还包括为了美观(每行不超过60个字符)而增加的很多换行。
1 class Perceptron(object): 2 def __init__(self, input_num, activator): 3 \'\'\' 4 初始化感知器,设置输入参数的个数,以及激活函数。 5 激活函数的类型为double -> double 6 \'\'\' 7 self.activator = activator 8 # 权重向量初始化为0 9 self.weights = [0.0 for _ in range(input_num)] 10 # 偏置项初始化为0 11 self.bias = 0.0 12 def __str__(self): 13 \'\'\' 14 打印学习到的权重、偏置项 15 \'\'\' 16 return \'weights\\t:%s\\nbias\\t:%f\\n\' % (self.weights, self.bias) 17 def predict(self, input_vec): 18 \'\'\' 19 输入向量,输出感知器的计算结果 20 \'\'\' 21 # 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起 22 # 变成[(x1,w1),(x2,w2),(x3,w3),...] 23 # 然后利用map函数计算[x1*w1, x2*w2, x3*w3] 24 # 最后利用reduce求和 25 return self.activator( 26 reduce(lambda a, b: a + b, 27 map(lambda (x, w): x * w, 28 zip(input_vec, self.weights)) 29 , 0.0) + self.bias) 30 def train(self, input_vecs, labels, iteration, rate): 31 \'\'\' 32 输入训练数据:一组向量、与每个向量对应的label;以及训练轮数、学习率 33 \'\'\' 34 for i in range(iteration): 35 self._one_iteration(input_vecs, labels, rate) 36 def _one_iteration(self, input_vecs, labels, rate): 37 \'\'\' 38 一次迭代,把所有的训练数据过一遍 39 \'\'\' 40 # 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...] 41 # 而每个训练样本是(input_vec, label) 42 samples = zip(input_vecs, labels) 43 # 对每个样本,按照感知器规则更新权重 44 for (input_vec, label) in samples: 45 # 计算感知器在当前权重下的输出 46 output = self.predict(input_vec) 47 # 更新权重 48 self._update_weights(input_vec, output, label, rate) 49 def _update_weights(self, input_vec, output, label, rate): 50 \'\'\' 51 按照感知器规则更新权重 52 \'\'\' 53 # 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起 54 # 变成[(x1,w1),(x2,w2),(x3,w3),...] 55 # 然后利用感知器规则更新权重 56 delta = label - output 57 self.weights = map( 58 lambda (x, w): w + rate * delta * x, 59 zip(input_vec, self.weights)) 60 # 更新bias 61 self.bias += rate * delta
接下来,我们利用这个感知器类去实现and函数。
1 def f(x): 2 \'\'\' 3 定义激活函数f 4 \'\'\' 5 return 1 if x > 0 else 0 6 def get_training_dataset(): 7 \'\'\' 8 基于and真值表构建训练数据 9 \'\'\' 10 # 构建训练数据 11 # 输入向量列表 12 input_vecs = [[1,1], [0,0], [1,0], [0,1]] 13 # 期望的输出列表,注意要与输入一一对应 14 # [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0 15 labels = [1, 0, 0, 0] 16 return input_vecs, labels 17 def train_and_perceptron(): 18 \'\'\' 19 使用and真值表训练感知器 20 \'\'\' 21 # 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f 22 p = Perceptron(2, f) 23 # 训练,迭代10轮, 学习速率为0.1 24 input_vecs, labels = get_training_dataset() 25 p.train(input_vecs, labels, 10, 0.1) 26 #返回训练好的感知器 27 return p 28 if __name__ == \'__main__\': 29 # 训练and感知器 30 and_perception = train_and_perceptron() 31 # 打印训练获得的权重 32 print and_perception 33 # 测试 34 print \'1 and 1 = %d\' % and_perception.predict([1, 1]) 35 print \'0 and 0 = %d\' % and_perception.predict([0, 0]) 36 print \'1 and 0 = %d\' % and_perception.predict([1, 0]) 37 print \'0 and 1 = %d\' % and_perception.predict([0, 1])
将上述程序保存为perceptron.py文件,通过命令行执行这个程序,其运行结果为:

附完整代码:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 class Perceptron(object): 5 def __init__(self, input_num, activator): 6 \'\'\' 7 初始化感知器,设置输入参数的个数,以及激活函数。 8 激活函数的类型为double -> double 9 \'\'\' 10 self.activator = activator 11 # 权重向量初始化为0 12 self.weights = [0.0 for _ in range(input_num)] 13 # 偏置项初始化为0 14 self.bias = 0.0 15 16 def __str__(self): 17 \'\'\' 18 打印学习到的权重、偏置项 19 \'\'\' 20 return \'weights\\t:%s\\nbias\\t:%f\\n\' % (self.weights, self.bias) 21 22 23 def predict(self, input_vec): 24 \'\'\' 25 输入向量,输出感知器的计算结果 26 \'\'\' 27 # 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起 28 # 变成[(x1,w1),(x2,w2),(x3,w3),...] 29 # 然后利用map函数计算[x1*w1, x2*w2, x3*w3] 30 # 最后利用reduce求和 31 return self.activator( 32 reduce(lambda a, b: a + b, 33 map(lambda (x, w): x * w, 34 zip(input_vec, self.weights)) 35 , 0.0) + self.bias) 36 37 def train(self, input_vecs, labels, iteration, rate): 38 \'\'\' 39 输入训练数据:一组向量、与每个向量对应的label;以及训练轮数、学习率 40 \'\'\' 41 for i in range(iteration): 42 self._one_iteration(input_vecs, labels, rate) 43 44 def _one_iteration(self, input_vecs, labels, rate): 45 \'\'\' 46 一次迭代,把所有的训练数据过一遍 47 \'\'\' 48 # 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...] 49 # 而每个训练样本是(input_vec, label) 50 samples = zip(input_vecs, labels) 51 # 对每个样本,按照感知器规则更新权重 52 for (input_vec, label) in samples: 53 # 计算感知器在当前权重下的输出 54 output = self.predict(input_vec) 55 # 更新权重 56 self._update_weights(input_vec, output, label, rate) 57 58 def _update_weights(self, input_vec, output, label, rate): 59 \'\'\' 60 按照感知器规则更新权重 61 \'\'\' 62 # 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起 63 # 变成[(x1,w1),(x2,w2),(x3,w3),...] 64 # 然后利用感知器规则更新权重 65 delta = label - output 66 self.weights = map( 67 lambda (x, w): w + rate * delta * x, 68 zip(input_vec, self.weights)) 69 # 更新bias 70 self.bias += rate * delta 71 72 73 def f(x): 74 \'\'\' 75 定义激活函数f 76 \'\'\' 77 return 1 if x > 0 else 0 78 79 80 def get_training_dataset(): 81 \'\'\' 82 基于and真值表构建训练数据 83 \'\'\' 84 # 构建训练数据 85 # 输入向量列表 86 input_vecs = [[1,1], [0,0], [1,0], [0,1]] 87 # 期望的输出列表,注意要与输入一一对应 88 # [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0 89 labels = [1, 0, 0, 0] 90 return input_vecs, labels 91 92 93 def train_and_perceptron(): 94 \'\'\' 95 使用and真值表训练感知器 96 \'\'\' 97 # 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f 98 p = Perceptron(2, f) 99 # 训练,迭代10轮, 学习速率为0.1 100 input_vecs, labels = get_training_dataset() 101 p.train(input_vecs, labels, 10, 0.1) 102 #返回训练好的感知器 103 return p 104 105 106 if __name__ == \'__main__\': 107 # 训练and感知器 108 and_perception = train_and_perceptron() 109 # 打印训练获得的权重 110 print and_perception 111 # 测试 112 print \'1 and 1 = %d\' % and_perception.predict([1, 1]) 113 print \'0 and 0 = %d\' % and_perception.predict([0, 0]) 114 print \'1 and 0 = %d\' % and_perception.predict([1, 0]) 115 print \'0 and 1 = %d\' % and_perception.predict([0, 1])
以上是关于Deep Learning之感知器的主要内容,如果未能解决你的问题,请参考以下文章
Deep Learning学习 之 CNN代码解析(MATLAB)