学习笔记-----统计信息
Posted Angular_JS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记-----统计信息相关的知识,希望对你有一定的参考价值。
1、统计信息
SQL SERVER是根据表中的统计信息进行行数估计,按照脚本语义来确定物理操作步骤生成执行计划,再按照该执行计划访问数据。表和视图都有统计信息,统计信息对象是根据索引或表列的列表创建的。当某列第一次最为条件查询时,将创建单列的统计信息。当创建索引时,将创建同名的统计信息。索引中,统计信息只统计首列,因此索引除了按首列排序存储数据外,其统计信息也是按首列计算统计的,所以索引设置时定义的第一列非常重要。每个统计信息对象都在包含一个或多个表列的列表上创建,并且包括显示值在第一列中的分布的直方图。以下情况适用时,考虑使用 CREATE STATISTICS 语句创建统计信息:
① 数据库引擎优化顾问建议创建统计信息。
② 查询谓词包含尚不位于相同索引中的多个相关列。
③ 查询从数据的子集中选择数据。
④ 查询缺少统计信息。
2、查看统计信息
select * from sys.stats where object_id=OBJECT_ID(N\'[Sales].[SalesOrderDetail]\')

3、查看一张表的某个索引的统计信息
先查看整个数据库的索引
SELECT * FROM sys.sysindexes
查看表的索引的统计信息
DBCC SHOW_STATISTICS (\'tb_medicine\' ,\'pk_medic_3124D5480BC6C34E\');
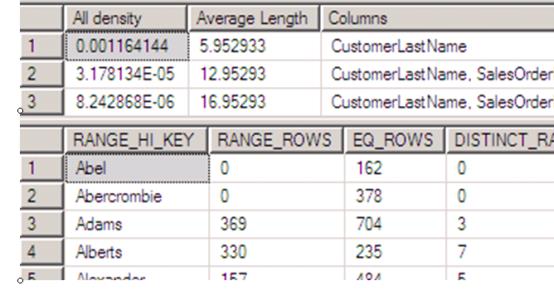
4、先创建一个聚集索引
DROP INDEX pk_medic_3124D5480BC6C34E ON tb_medicine
CREATE CLUSTERED INDEX ci_name
ON tb_medicine
(药品名称 ASC);
查看统计信息
DBCC SHOW_STATISTICS (\'tb_DrugsRegistration\' ,\'ci_name\');
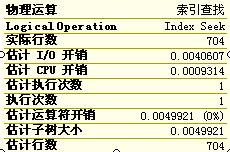
在执行一次查询语句
select d.*from tb_DrugsRegistration as d where d.name =\'硝苯地平\'
注意:查看估计行数,系统会在建立索引之后自动建立一个统计的信息,进行一个摸底的排查,对比真正查询出来的一个统计行数,可以看出估计出的行数较为准确,但是也存在偏差很多的因为查询是系统会隐藏某些药品的名字,在查询这些被隐藏的名字的时候,系统就会用隐藏的总行数除以隐藏的种类,得到一个估计的结果,只是取一个均值。
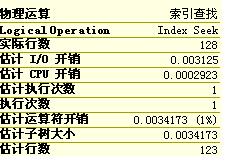
5、删除多余的tb_medicine表的某个相同行数的药品行数,查看药品名称为依替米星的估计行数,再执行查询语句
DELETE TOP(3) tb_medicine SELECT O.* FROM tb_medicine AS O WHERE o.name like \'依替米星%\';
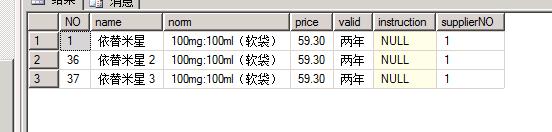
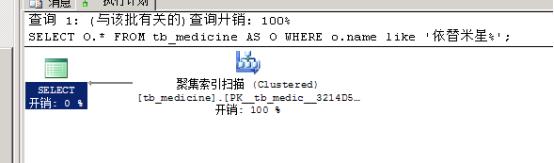

注意:由上面的查询结果可以看得出来,删除记录之后系统就可以进行一个样本的采集,但这个采集只是随意的,短暂的,因此存在误差。
下面就要对索引进行一个手动的更新(使用完整扫描)
UPDATE STATISTICS tb_medicne ci_name
WITH FULLSCAN;
再次查询统计信息
DBCC SHOW_STATISTICS (\'tb_DrugsRegistration\' ,\'ci_name\');
6、总结:对于改天查询中的一个参数或多个参数值导致查询执行时间差异很大的语句,多半是Statistics没有及时跟上,我们需要手动更新一下。在之后我们观察这个索引的自动更新统计是否为ON,如果配置正常但是Statistics还不能及时跟上的建议建立一个job定期检查统计信息更新情况并处理。
SQL Server基于开销(Cost)评估执行计划,选择开销最小的作为“最优化”的执行计划,由于SQL Server根据索引及其统计信息来计算开销,所以,对查询优化来说,索引和统计数据是非常重要的,查询优化器(Query Optimizer)使用统计信息对查询的开销进行评估(Estimate),选择开销小的查询计划,作为最终的、“最优的”的执行计划。
以上是关于学习笔记-----统计信息的主要内容,如果未能解决你的问题,请参考以下文章