一、介绍
1.什么是数据?
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种:


数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的的原始素材。
数据可以是连续的值,比如声音、图像,称为模拟数据。也可以是离散的,如符号、文字,称为数字数据。
在计算机系统中,数据以二进制信息单元0,1的形式表示。
2.数据类型
数字(整形,长整形,浮点型,复数)
字符串
字节串:在介绍字符编码时介绍字节bytes类型
列表
元组
字典
集合
3.数据类的定义及功能
学习Python的数据类型可以从以下几方面学习?
#一:基本使用 1 用途 2 定义方式 3 常用操作+内置的方法 #二:该类型总结 1 存一个值or存多个值 只能存一个值 可以存多个值,值都可以是什么类型 2 有序or无序 3 可变or不可变 !!!可变:值变,id不变。可变==不可hash !!!不可变:值变,id就变。不可变==可hash
二、数字
数字类型包括整形,长整形,浮点型,复数等,分别的定义方式:
A.整型,长整型:
基本使用(整型int):
作用:年纪,等级,身份证号,qq号等整型数字相关属于整数。
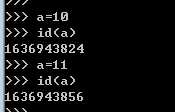
定义: a=int(10)
常用操作+内置的方法: 无 经常使用a=10 这种方式定义。
#长整形(了解)
在python2中(python3中没有长整形的概念):
>>> num=2L
>>> type(num)
<type ‘long‘>
该类型总结
1. 只能存一个值
2. 不涉及可以到数据索引的过程,故没有有序或无序直说。
3. 不可变的类型,值变,id就变。不可变==可hash,eq:
B、浮点型
浮点型基本使用(float)
作用:薪资,身高,体重,体质参数等浮点数相关
定义:salary=3000.3 #本质salary=float(3000.3)
>>> a=1.1 >>> type(a) <class ‘float‘> >>>
该类型总结
1. 只能存一个值
2. 不涉及可以到数据索引的过程,故没有有序或无序直说。
3. 不可变的类型,值变,id就变。不可变==可hash,eq:
C、复数(了解)
>>> x=1-2j
>>> x.real
1.0
>>> x.imag
-2.0
三、字符串
基本使用(str)
a.作用:名字,性别,国籍等描述性的信息
b.定义:在单引号,双引号或者三引号里定义的一串字符
name=‘shao’、name=“shao”、name=“”“shao”“”
c.常用操作+内置方法
c1.常用操作
1、按索引取值(正向取+反向取) :只能取
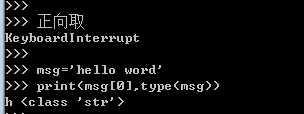
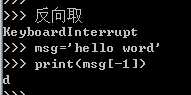
2、切片(顾头不顾尾,步长)
msg=‘hello word‘ print (msg[0:3]) #取出hel print(msg[::-1]) #到这打印出drow olleh
3、长度 len
msg=‘hello word‘
print(len(msg)) ##相当于print(msg.__len__())
4、成员运算in和not in
msg=‘hello world‘
print(‘llo‘ in msg)
print(‘llo‘ not in msg)
5、移除空白 strip
#移除空白,就是去除空格的意思。 # password=‘ alex3714 ‘ # print(password.strip()) #打印结果是没有空格的alex3714 # password=input(‘>>: ‘).strip() # 如何输入都不会保留空格,只限左右两面 # password=‘alex 3714 ‘ # print(password.strip()) #打印结果是没有空格的alex3714
6、切分 split
#6、切分split 与切片类似, # user_info=‘root:x:0:0::/root:/bin/bash‘ # res=user_info.split(‘:‘) #内置关键字split 使用:分割,相当与Linux的awk 功能 # print(res[0]) #只取出root #cmd=‘get /root/a/b/c/d.txt‘ #print(cmd.split(‘/‘,0)) #print(cmd.split(‘/‘,1)) #print(cmd.split(‘/‘,2)) #print(cmd.split(‘/‘,3)) #print(cmd.split(‘/‘,4)) 输出结果是: [‘get /root/a/b/c/d.txt‘] #0 不切分 [‘get ‘, ‘root/a/b/c/d.txt‘] #1 切分一次 [‘get ‘, ‘root‘, ‘a/b/c/d.txt‘] #2 切分两次 [‘get ‘, ‘root‘, ‘a‘, ‘b/c/d.txt‘] # …… [‘get ‘, ‘root‘, ‘a‘, ‘b‘, ‘c/d.txt‘] # …… #通过以上可以看该cmd 使用‘/’作为切分符,数字表示的是切分次数。
7、循环
#使用现有的for while 写出字符的循环: msg=‘hello‘ for a in msg: print(a) ##相当于 for i in range(len(msg)): #0 1 2 print(msg[i]) size=len(msg) n=0 while n<size: print(msg[n]) n+=1
c2.内置方法
# 最常用的有 #1、strip,lstrip,rstrip ##再上面取空白就使用了,lstsip只去左面的空格,rstrip只取右面的空格 #2、lower,upper ##字符的大小写输出lower小写,upper大写 调用方式print(msg.lower()); #3、startswith,endswith ##表示以什么什么开头,或者结尾的字符匹配。结果为是布尔值 真或假 #4、format的三种玩法 ##与%s 类似的格式化输出。常用语传值 #5、split,rsplit ##切片 默认是从左往右,rsplit是从右往左 #6、join ##字符串的关联或者是相加 #7、replace ## 字符串替换,可以替换次数 #8、isdigit ##常用的数字判断方法
#strip name=‘*egon**‘ print(name.strip(‘*‘)) print(name.lstrip(‘*‘)) print(name.rstrip(‘*‘)) #lower,upper name=‘egon‘ print(name.lower()) print(name.upper()) #startswith,endswith name=‘alex_SB‘ print(name.endswith(‘SB‘)) print(name.startswith(‘alex‘)) #format的三种玩法 res=‘{} {} {}‘.format(‘egon‘,18,‘male‘) res=‘{1} {0} {1}‘.format(‘egon‘,18,‘male‘) res=‘{name} {age} {sex}‘.format(sex=‘male‘,name=‘egon‘,age=18) #split name=‘root:x:0:0::/root:/bin/bash‘ print(name.split(‘:‘)) #默认分隔符为空格 name=‘C:/a/b/c/d.txt‘ #只想拿到顶级目录 print(name.split(‘/‘,1)) name=‘a|b|c‘ print(name.rsplit(‘|‘,1)) #从右开始切分 #join tag=‘ ‘ print(tag.join([‘egon‘,‘say‘,‘hello‘,‘world‘])) #可迭代对象必须都是字符串 #replace name=‘alex say :i have one tesla,my name is alex‘ print(name.replace(‘alex‘,‘SB‘,1)) ##数字1 表示替换一次的意思 #isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法 age=input(‘>>: ‘) print(age.isdigit()) 示例
8、需要了解后续自己研究
#1、find,rfind,index,rindex,count #2、center,ljust,rjust,zfill #3、expandtabs #4、captalize,swapcase,title #5、is数字系列 #6、is其他
#find,rfind,index,rindex,count name=‘egon say hello‘ print(name.find(‘o‘,1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引 # print(name.index(‘e‘,2,4)) #同上,但是找不到会报错 print(name.count(‘e‘,1,3)) #顾头不顾尾,如果不指定范围则查找所有 #center,ljust,rjust,zfill name=‘egon‘ print(name.center(30,‘-‘)) print(name.ljust(30,‘*‘)) print(name.rjust(30,‘*‘)) print(name.zfill(50)) #用0填充 #expandtabs name=‘egon\\thello‘ print(name) print(name.expandtabs(1)) #captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg=‘egon say hi‘ print(msg.title()) #每个单词的首字母大写 #is数字系列 #在python3中 num1=b‘4‘ #bytes num2=u‘4‘ #unicode,python3中无需加u就是unicode num3=‘四‘ #中文数字 num4=‘Ⅳ‘ #罗马数字 #isdigt:bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode #bytes类型无isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判断浮点数 num5=‘4.3‘ print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) ‘‘‘ 总结: 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 如果要判断中文数字或罗马数字,则需要用到isnumeric ‘‘‘ #is其他 print(‘===>‘) name=‘egon123‘ print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier()) print(name.islower()) print(name.isupper()) print(name.isspace()) print(name.istitle()) 示例
四、列表
基本使用(list)
a.作用:多个信息,如多个爱好,多个人名
b.定义:在中括号中用逗号分割的任意字符
name=[‘shao‘,‘18‘,‘man‘]
c.常用操作+内置方法
#1、按索引存取值(正向存取+反向存取):即可存也可以取
#2、切片(顾头不顾尾,步长)
#3、长度
#4、成员运算in和not in
#5、追加
#6、删除
#7、循环
#优先掌握的操作: #1、按索引存取值(正向存取+反向存取):即可存也可以取 # my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,4,5] #2、切片(顾头不顾尾,步长) print(my_girl_friends[0:5:2]) #2是步长的意思 #3、长度 # print(my_girl_friends.__len__()) # print(len(my_girl_friends)) #4、成员运算in和not in # print(‘wupeiqi‘ in my_girl_friends) #5、追加 # my_girl_friends[5]=3 #IndexError: list assignment index out of range # my_girl_friends.append(6) # print(my_girl_friends) #6、删除 my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,4,5] #单纯的删除 # del my_girl_friends[0] # print(my_girl_friends) # res=my_girl_friends.remove(‘yuanhao‘) # print(my_girl_friends) # print(res) # print(my_girl_friends) #删除并拿到结果:取走一个值 # res=my_girl_friends.pop(2) # res=my_girl_friends.pop() # print(res) # my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,4,5] # print(my_girl_friends.pop(0)) #‘alex‘ # print(my_girl_friends.pop(0)) #‘wupeqi‘ # print(my_girl_friends.pop(0)) #‘yuanhao‘ #7、循环 # my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,4,5] # i=0 # while i < len(my_girl_friends): # print(my_girl_friends[i]) # i+=1 # for item in my_girl_friends: # print(item) # for i in range(10): # if i== 3: # break # # continue # print(i) # else: # print(‘===>‘)
D.内置方法
#常用内置方法 1.insert #(1,‘str’) 1 就是索引index 在索引是1的位置插入str 2.clear #清空 3.copy #复制一个列表 4.count #统计 统计个数 5.extend # 列表扩展填充,与append类似但append只能添加一个值 6.index #索引 7.reverse #列表反向输出 8.sort #正序输出
#掌握的方法 my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,‘yuanhao‘,4,5] # my_girl_friends.insert(1,‘egon‘) # print(my_girl_friends) # my_girl_friends.clear() # print(my_girl_friends) # l=my_girl_friends.copy() # print(l) # print(my_girl_friends.count(‘yuanhao‘)) # l=[‘egon1‘,‘egon2‘] # my_girl_friends.extend(l) # my_girl_friends.extend(‘hello‘) # print(my_girl_friends) # my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,‘yuanhao‘,4,5] # print(my_girl_friends.index(‘wupeiqi‘)) # print(my_girl_friends.index(‘wupeiqissssss‘)) # my_girl_friends.reverse() # my_girl_friends=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,‘yuanhao‘,4,5] # my_girl_friends.reverse() # print(my_girl_friends) # l=[1,10,4,11,2,] # l.sort(reverse=True) # print(l) # x=‘healloworld‘ # y=‘he2‘ # print(x > y) # l=[‘egon‘,‘alex‘,‘wupei‘] # l.sort() # print(l)
#该类型总结 # 1 存一个值or存多个值? # 可以存多个值,值都可以是任意类型 # 2 有序 # 3 可变or不可变? # !!!可变:值变,id不变。可变==不可hash
五、元组
基本使用(tuple)
a.作用:存多个值,对于列表来说,元组是不可变(可以当做字典的key),主要用来读。
b.定义:元组的定义是使用小括号如:age=(11,22,33,44,55)本质age=tuple((11,22,33,44,55))
c.常用操作+内置方法
c1.常用操作
1.按索引存取值(正向存取+反向存取):只能取
2.切片
3.长度len
4.成员运算in 和not in
5.循环
age=(11,22,33,44,55) print(age[-1]) #反向取 print(age[:2]) #切片 print(age[:2:-1]) #倒着取出两个数 print(len(age)) #长度 print(66 not in age) #成员运算 for a in age: #循环 print(a)
c2.内置操作
1.index #索引
2.count #统计某个str 字符串
age=(11,22,33,44,55) print(age.index(55)) a=[‘shao‘,18] print(a.index(‘shao‘)) age=(11,22,33,44,55,gg) print(age.count(‘gg‘))
#二:该类型总结
# 1 存一个值or存多个值?
# 可以存多个值,值都可以是任意类型
# 2 有序
# 3 可变or不可变?
# !!!不可变:值变,id就变。不可变==可hash
六、字典
基本使用(dict)
- 作用:存放多个值,key=value 形式存在,取存速度快
- 定义:使用大括号定义,如 info={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘} 相当于#info=dict({‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘})
#了解--其余的定义方式 # info=dict(age=18,sex=‘male‘,name=‘egon‘) # print(info) # info=dict([[‘name‘,‘egon‘],[‘age‘,18],[‘sex‘,‘male‘]]) # print(info) # info={}.fromkeys([‘name‘,‘age‘,‘sex‘],None) # print(info) # info={}.fromkeys(‘hello‘,None) # print(info)
- 常用操作+内置参数
1、按key存取值:可存可取
d={‘name‘:‘egon‘} print(d[‘name‘])
2、长度len
print(d.len())
3、成员运算in和not in
# info={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}
# print(‘name‘ in info)
4、删除
info={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}
# print(info.pop(‘name‘)) #pop 只能删除一个值且该值必须为key
# print(info)
# print(info.popitem()) #(‘sex‘, ‘male‘) 可删任意的值
# print(info)
5、键keys(),值values(),键值对items()
info={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}
print(info.keys())
print(list(info.keys())[0])
print(list(info.values()))
print((info.items()))
6、循环
for a in info:
print(a)
print(a,info[a])
内置参数
setdefault #解决重复赋值
setdefault的功能 1:key存在,则不赋值,key不存在则设置默认值 2:key存在,返回的是key对应的已有的值,key不存在,返回的则是要设置的默认值 d={} print(d.setdefault(‘a‘,1)) #返回1 d={‘a‘:2222} print(d.setdefault(‘a‘,1)) #返回2222
info={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}
print(info.setdefault(‘shao‘,‘mmz‘)) #shao 不存在info 的字典,所以他直接返回默认定义的mmz
七、集合
#作用:去重,关系运算, #定义(set): 知识点回顾 可变类型是不可hash类型 不可变类型是可hash类型 #定义集合: 集合:可以包含多个元素,用逗号分割, 集合的元素遵循三个原则: 1:每个元素必须是不可变类型(可hash,可作为字典的key) 2:没有重复的元素 3:无序 注意集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值 #优先掌握的操作: #1、长度len #2、成员运算in和not in #3、|合集 #4、&交集 #5、-差集 #6、^对称差集 #7、== #8、父集:>,>= #9、子集:<,<=
八、字符编码
抄袭: http://www.cnblogs.com/linhaifeng/articles/5950339.html
九:文件处理
摘抄:http://www.cnblogs.com/linhaifeng/articles/5984922.html