LinkedHashMap学习
Posted JillWen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinkedHashMap学习相关的知识,希望对你有一定的参考价值。
一、概述
LinkedHashMap继承自HashMap,是Map接口的一个具体实现,它是有序的,可以按照插入顺序先后和访问时间先后进行排序,选择哪种排序方式取决于在新建LinkedHashMap的时候是否指定了accessOrder为true。如果不指定,accessOrder默认为false,LinkedHashMap会按照插入顺序进行排序;入股指定为true,则会按照LRU算法将最少访问的元素排在前面。
LinkedHashMap中的removeEldestEntry(Map.Entry)方法默认返回false,如果重写,如:
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
,则当节点达到100,再插入新节点就会删除过时的链表头部的节点。
LinkedHashMap提供了所有可选的Map操作,并允许插入null。因为要多维护一个链表,其性能可能略低于HashMap。但是,有一个例外:对LinkedHashMap的集合视图的迭代需要时间与map大小成正比,而不管其容量。 HashMap上的迭代可能会花销更大,需要的时间与其容量成正比。也就是说capacity 的大小对其性能影响没有对HashMap的大。
LinkedHashMap的实现是非同步的。当涉及到多个线程访问并且有线程改变其结构时,必须在外部进行同步。通常对使用map的对象进行同步来完成同步操作。如果不存在这样的对象,则应该使用Collections.synchronizedMap方法包裹该map。而且最好在创建时包裹,以防止不同步访问:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
这里,需要注意的是map节点的值改变不会导致结构改变,结构改变是指添加、删除节点或者修改顺序引起的改变。
LinkedHashMap继承了HashMap的fail-fast(快速失败)机制,该机制的实现是通过一个modCount变量来记录修改次数,在每次调用会导致LinkedHashMap结构改变的方法的时候就比较下理论上的修改次数和当前修改次数的值。如果相等则允许操作,并将modCount加1,如果不相等则抛出ConcurrentModificationException异常。这种机制只能用来检测错误,无法保证一定起效。
二、结构
LinkedHashMap之所以能够进行排序,是因为它在HashMap的“数组+链表”的结构上还维护了一个双向链表,其节点结构可以参考如下的图(这里重点关注before和after节点):

(图1)
其整体结构可以参考如下的图(图上半部分的“数组+链表”结构继承自HashMap,绿色的箭头代表图1中的next,排序的实现主要通过下面的双向链表):
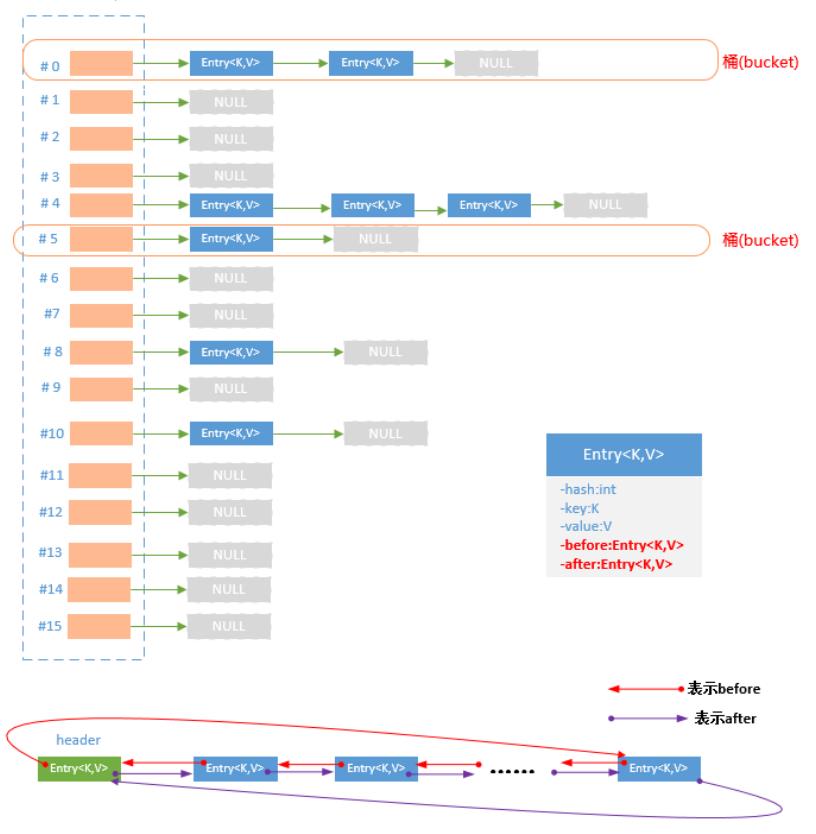
(图2来自:http://blog.csdn.net/luanlouis/article/details/43017071)
三、源码分析
构造函数:

这里注意到第四个构造函数,如果指定第三个参数为true会开启按访问时间排序。另外几个构造函数都有设置accessOrder = false。
属性:

accessOrder已经说明过了。剩下的,head代表的是双向链表的头部,表示最久未被访问的节点。tail代表的是双向链表的尾部,表示最近一次访问的节点。
方法:

这里可以重点看下afterNodeAccess方法,调用put,putAll,putIfAbsent,get,getOrDefault,compute,computeIfAbsent,computeIfPresent或merge方法时都将调用该方法。而调用该方法时,如果accessOrder为true,且当前操作的节点在方法调用后存在,则会移动当前操作的节点至双向链表尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
其他方法介绍可参考:
http://blog.csdn.net/u014634338/article/details/78494051
四、总结
LinkedHashMap继承于 HashMap,相当于在HashMap的基础上添加了顺序访问的功能,而方法的操作也是基于HashMap之上,增加了对提供顺序访问功能的双向链表的维护。
以上是关于LinkedHashMap学习的主要内容,如果未能解决你的问题,请参考以下文章