大数据量情况下高效比较两个list
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据量情况下高效比较两个list相关的知识,希望对你有一定的参考价值。
比如,对两个list<object>进行去重,合并操作时,一般的写法为两个for循环删掉一个list中重复的,然后再合并。
如果数据量在千条级别,这个速度还是比较快的。但如果数据量超过20W+(比如大批量的导入数据并对数据进行处理)时,则这块代码执行时间会比较长,非常影响用户体验和程序功能。这时我们可以用差集(Except)来处理重复数据。
下面MSDN上的代码示例演示了如何使用 Except<TSource>(IEnumerable<TSource>, IEnumerable<TSource>) 方法来比较两个数字序列,并返回仅在第一个序列中出现的元素。
double[] numbers1 = { 2.0, 2.1, 2.2, 2.3, 2.4, 2.5 }; double[] numbers2 = { 2.2 }; IEnumerable<double> onlyInFirstSet = numbers1.Except(numbers2); foreach (double number in onlyInFirstSet) outputBlock.Text += number + "\\n"; /* This code produces the following output: 2 2.1 2.3 2.4 2.5 */
需要注意的是A.Except(B)与B.Except(A)结果是不一样的。
A.Except(B):
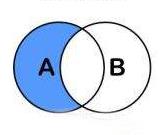
B.Except(A):
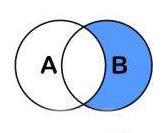
如果希望比较某种自定义数据类型对象的序列,则必须在您的类中实现 IEqualityComparer<T> 泛型接口。 下面的代码演示了如何在自定义数据类型中实现此接口并提供 GetHashCode 和 Equals 方法。
假设有需求是:在oldlist中过滤掉和list有相同ContractNo值的数据。
public class AssetPoolDataComparer : IEqualityComparer<AssetPoolData> { public bool Equals(AssetPoolData x, AssetPoolData y) { if (Object.ReferenceEquals(x, y)) return true; //设置比较条件为两个ContractNo相同 return x != null && y != null && x.ContractNo.Equals(y.ContractNo); } public int GetHashCode(AssetPoolData obj) { int hashContractNo = obj.ContractNo == null ? 0 : obj.ContractNo.GetHashCode(); //主键ID int hashProductID = obj.Id.GetHashCode(); return hashContractNo ^ hashProductID; } } var exceptList = oldlist.Except(list, new AssetPoolDataComparer()).ToList();
修改完代码,测试前后代码块运行时间,效果还是非常可观的。
By QJL
以上是关于大数据量情况下高效比较两个list的主要内容,如果未能解决你的问题,请参考以下文章