用python爬取亚马逊物品列表
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python爬取亚马逊物品列表相关的知识,希望对你有一定的参考价值。
1. 仔细分析亚马逊查询详细界面可以看出来,主要关键部分有三个地方,这三个地方分别控制了查询列表的页面和关键字,所以修改这几个参数可以改变列表页数以及模糊查询的结果
http://www.amazon.cn/s/ref=sr_pg_3?rh=n%3A658390051%2Ck%3Aphp&page=3&keywords=Java&ie=UTF8&qid=1459478790
2. 通过基础链接以及正则表达式匹配的方法进行替换的方式改变爬取页面,注意由于使用了正则表达式匹配,所以需要引入re模块
source_page = ‘sr_pg_‘+str(page_num) page_index = ‘page=‘+str(page_num) newkeywords = "%3A"+keywords+‘&‘ baseUrl = "http://www.amazon.cn/s/ref=sr_pg_3?rh=n%3A658390051%2Ck%3Aphp&page=3&keywords=" baseUrl,number = re.subn(r‘sr_pg_[0-9]+‘,source_page,baseUrl) baseUrl,number = re.subn(r‘page=[0-9]+‘,page_index,baseUrl) baseUrl,number = re.subn(r‘%3A(.*?)/&‘,newkeywords,baseUrl)
3. 调用F12查看网页源码,可以看到需要爬取的结果列表都是在一个<li></li>标签内,标签id按顺序递增,对urllib2.open(url).read()获取的网页源码用BeautifulSoup处理之后的结果集进行findAll查找可以获取单个页面的所有书籍对象信息。
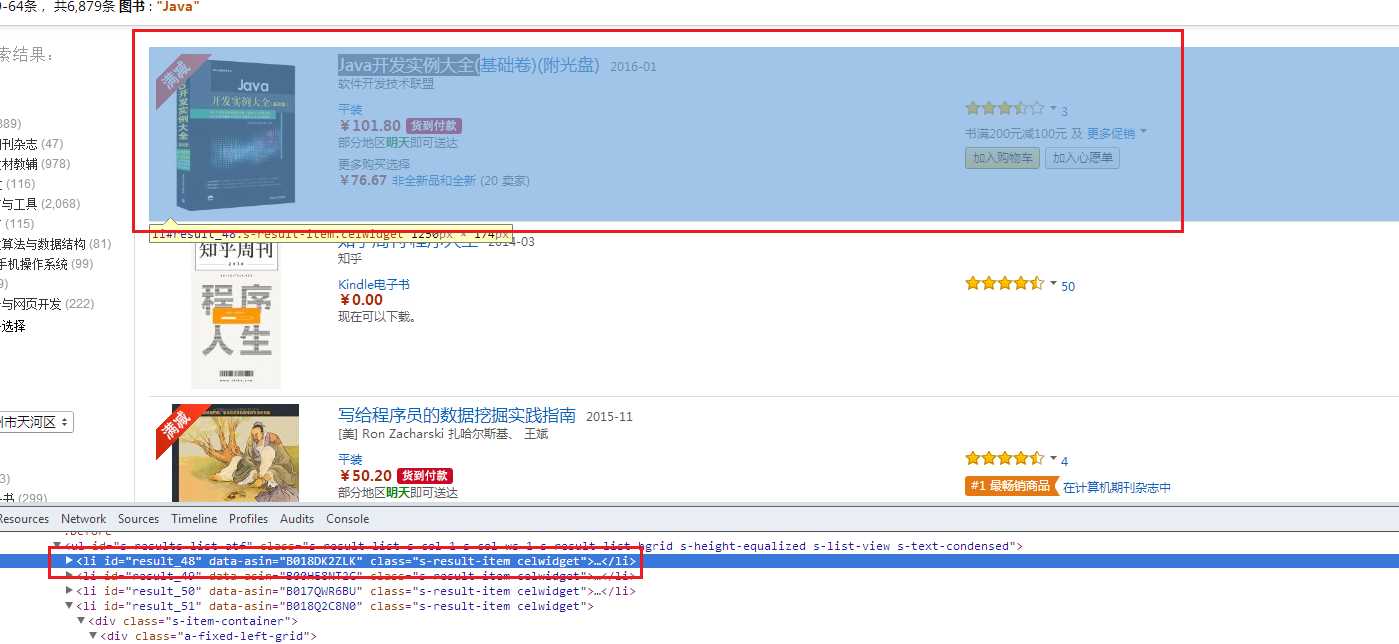
4. 获取书籍名称以及卖家数和优惠信息

通过分析网页源码可以知道获取书籍名称可以从<h2></h2>标签的string值获取。


而卖家信息和书籍优惠信息可以从<span></span>标签中使用正则表达式获取youHui = re.findall(‘<span class="a-color-secondary">(.*?)</span>‘,str(i),re.S)。至于为什么将卖家信息与优惠信息一块爬取。其实是我还没有好的办法区分两个信息,所以各位大神有什么好的方法请指导以下,
小弟感激不尽了。附上代码(page_num >= 2这个可以去掉,则可以爬取整个列表,调试时可以加上限制,只爬取2页):
#ecoding=utf-8 from bs4 import BeautifulSoup import urllib2 import re keywords = raw_input("请输入您要查询的书籍关键字:") isLast =1 page_num = 1 bookList=[] while isLast: source_page = ‘sr_pg_‘+str(page_num) page_index = ‘page=‘+str(page_num) newkeywords = "%3A"+keywords+‘&‘ baseUrl = "http://www.amazon.cn/s/ref=sr_pg_3?rh=n%3A658390051%2Ck%3Aphp&page=3&keywords=" baseUrl,number = re.subn(r‘sr_pg_[0-9]+‘,source_page,baseUrl) baseUrl,number = re.subn(r‘page=[0-9]+‘,page_index,baseUrl) baseUrl,number = re.subn(r‘%3A(.*?)/&‘,newkeywords,baseUrl) myUrl = baseUrl + keywords #伪装成浏览器访问,直接访问的话可能会拒绝 user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ headers = {‘User-Agent‘:user_agent} #构造请求 req = urllib2.Request(myUrl,headers=headers) #访问页面 myResponse = urllib2.urlopen(req) myPage = myResponse.read() print "--------------------------------第%d页--------------------------------------" % (page_num) myData = BeautifulSoup(myPage,"html.parser") rightContent = myData.findAll(‘li‘) for i in rightContent: bookName = i.findAll(‘h2‘,attrs={"class":"a-size-medium a-color-null s-inline s-access-title a-text-normal"}) for book in bookName: print "************************************************************************" print ("BOOK_NAME:").decode(‘utf-8‘).encode(‘gb2312‘) + book.get_text() youHui = re.findall(‘<span class="a-color-secondary">(.*?)</span>‘,str(i),re.S) for p in youHui: print p isLastTrue = myData.findAll(‘span‘,attrs={"class":"srSprite lastPageRightArrow"}) if len(isLastTrue) > 0 or page_num >= 2: isLast = 0 page_num+=1
以上是关于用python爬取亚马逊物品列表的主要内容,如果未能解决你的问题,请参考以下文章