数据库语句
Posted 鹏达君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库语句相关的知识,希望对你有一定的参考价值。
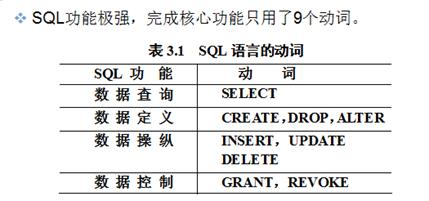
很快,我们就进入到我们数据库课程的核心章节,语句章节,首先我们先谈谈sql,其是结构化查询语句,是关系数据库的标准语言,同时,sql也是一个通用,功能极强的关系数据库语言。其特点有五个,分别为
1)综合统一
2)高度非过程化
3)面向集合的操作方式
4)以同一种语法结构提供多种使用方式
5)语言简洁,易学易用
我们先说说综合统一:
n 集数据定义语言(DDL),数据操纵语言(DML),数据控制语言(DCL)功能于一体。
n 可以独立完成数据库生命周期中的全部活动:
- 定义关系模式,插入数据,建立数据库;
- 对数据库中的数据进行查询和更新;
- 数据库重构和维护
- 数据库安全性、完整性控制等
n 用户数据库投入运行后,可根据需要随时逐步修改模式,不影响数据的运行。
n 数据操作符统一
然后说说高度非过程化:
v 非关系数据模型的数据操纵语言“面向过程”,必须制定存取路径
v SQL只要提出“做什么”,无须了解存取路径。
v 存取路径的选择以及SQL的操作过程由系统自动完成。
然后再说说面向集合的操作方式:
v 非关系数据模型采用面向记录的操作方式,操作对象是一条记录
v SQL采用集合操作方式
- 操作对象、查找结果可以是元组的集合
- 一次插入、删除、更新操作的对象可以是元组的集合
然后再说说以同一种语法结构提供多种使用方式
v SQL是独立的语言
能够独立地用于联机交互的使用方式
v SQL又是嵌入式语言
SQL能够嵌入到高级语言(例如C,C++,Java)程序中,供程序员设计程序时使用
最后说说语言简洁,易学易用
Sql所涉及的基本概念,我们也要了解,分别为三级模式结构图,基本表,存储文件,视图,首先先了解sql支持关系数据库的三级模式结构图:
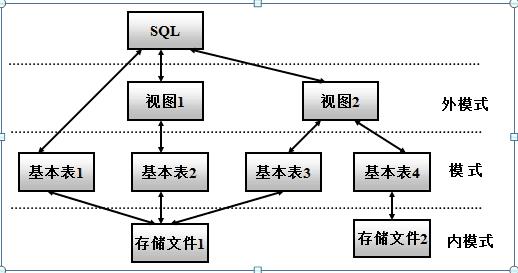
然后看看基本表:
本身独立存在的表
SQL中一个关系就对应一个基本表
一个(或多个)基本表对应一个存储文件
一个表可以带若干索引
再看看存储文件:
逻辑结构组成了关系数据库的内模式
物理结构是任意的,对用户透明
最后看看视图:
从一个或几个基本表导出的表
数据库中只存放视图的定义而不存放视图对应的数据
视图是一个虚表
用户可以在视图上再定义视图
了解到这些基础知识之后,然后我们就进入主题了,就是我们的语句,首先先说说我们sql的数据定义,sql的数据定义功能分:模式(数据库)定义,表定义,视图和索引的定义,具体的语句如下:
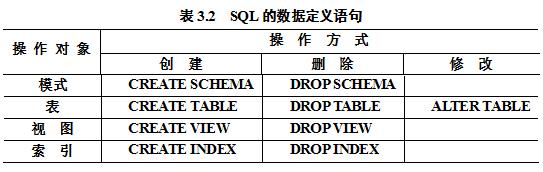
嘿嘿嘿,说了数据定义功能的四个分类,现在我们就先说模式的定义与删除(sql serverlar版本):
定义
不说其他,我们直接上代码,简单直白,通俗易懂:
[例1]定义一个学生-课程模式S-T
CREATE SCHEMA “S-T” AUTHORIZATION WANG;
为用户WANG定义了一个模式S-T
[例2]CREATE SCHEMA AUTHORIZATION WANG;
<模式名>隐含为用户名WANG
注意:如果没有指定<模式名>,那么<模式名>隐含为<用户名>
分析我们的模式:
v 定义模式实际上定义了一个命名空间(数据库中再建立一个数据库)
v 在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等。
v 在CREATE SCHEMA中可以接受CREATE TABLE,CREATE VIEW和GRANT子句。其语句块通式如下:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>[<表定义子句>|<视图定义子句>|<授权定义子句>]
例子:
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1( COL1 SMALLINT,
COL2 INT,
COL3 CHAR(20),
COL4 NUMERIC(10,3),
COL5 DECIMAL(5,2)
);
为用户ZHANG创建了一个模式TEST,并在其中定义了一个表TAB1。
删除
删除很简单,只需要把握一条语句语法,以及语句的两大关键词(级联和限制),不说其他,直接总结如下:
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
CASCADE(级联)
删除模式的同时把该模式中所有的数据库对象全部删除
RESTRICT(限制)
如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行。
当该模式中没有任何下属的对象时 才能执行。
然后我们就说数据定义的第二大模块,基本表的定义,删除与修改
定义:
一、定义基本表
CREATE TABLE <表名>
(<列名> <数据类型>[ <列级完整性约束条件> ]
[,<列名> <数据类型>[ <列级完整性约束条件>] ] …
[,<表级完整性约束条件> ] );
如果完整性约束条件涉及到该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级。
嘿嘿嘿,看到没,这边有个数据类型和约束条件,那么数据类型又有什么,约束条件又有什么呢?那么就得继续往下看,首先看看数据类型吧
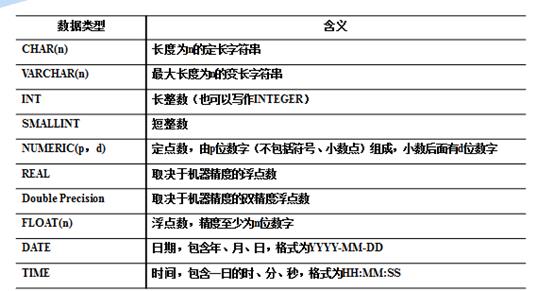
而约束条件有点多,而sql的约束有以下类型:

然后我说说表的一些补充,就是表和模式的关系:
v 每一个基本表都属于某一个模式(一个数据库一般有多个模式)
v 一个模式包含多个基本表
v 定义基本表所属模式
n 方法一:在表名中明显地给出模式名
Create table “S-T”.Student(......); /*模式名为 S-T*/
Create table “S-T”.Course(......);
Create table “S-T”.SC(......);
n 方法二:在创建模式语句中同时创建表
n 方法三:设置所属的模式
v 创建基本表(其他数据库对象也一样)时,若没有指定模式,系统根据搜索路径来确定该对象所属的模式
v RDBMS会使用模式列表中第一个存在的模式作为数据库对象的模式名
v 若搜索路径中的模式名都不存在,系统将给出错误
v 显示当前的搜索路径: SHOW search_path;
v 搜索路径的当前默认值是:$user, PUBLIC
v DBA用户可以设置搜索路径,然后定义基本表
SET search_path TO “S-T”,PUBLIC;
Create table Student(......);
结果建立了S-T.Student基本表。
RDBMS发现搜索路径中第一个模式名S-T存在,就把该
模式作为基本表Student所属的模式。
修改
其语法如下所示:
ALTER TABLE <表名>
[ ADD <新列名> <数据类型> [ 完整性约束 ] ]
[ADD <标记完整性约束>]
[DROP <列名>]
[ DROP <完整性约束名> ]
[ ALTER COLUMN<列名> <数据类型> ];
其中ADD子句用于增加新列,新的列级完整性约束条件和新的表级完整性约束条件。
DROP COLUMN子句用于删除表中的列,如果指定了CASCADE短语,则自动删除引用了该列的其他对象,比如视图;如果是RESTRICT短语,则如果该列被其他对象引用,RDBMS将拒绝删除该列。
DROP CONSTRAINT子句用于删除指定的完整性约束条件。
ALTER COLUMN子句用于修改原有的列定义,包括修改列名( alter table test change column address address1 varchar(30)--修改表列名)和数据类型
删除
DROP TABLE <表名>[RESTRICT| CASCADE];
n RESTRICT:删除表是有限制的。
- Ø 欲删除的基本表不能被其他表的约束所引用
- Ø 如果存在依赖该表的对象,则此表不能被删除
n CASCADE:删除该表没有限制。
- Ø 在删除基本表的同时,相关的依赖对象一起删除
然后我们要说说数据定义的第三个模块,索引的建立与删除,在说索引的建立与删除之前,我们需要知道一些基础知识,具体如下:
v 建立索引的目的:加快查询速度
v 谁可以建立索引
- DBA 或 表的属主(即建立表的人)
- DBMS一般会自动建立以下列上的索引
PRIMARY KEY
UNIQUE
v 谁 维护索引
DBMS自动完成
v 使用索引
DBMS自动选择是否使用索引以及使用哪些索引
v RDBMS中索引一般采用B+树、HASH索引来实现
n B+树索引具有动态平衡的优点
n HASH索引具有查找速度快的特点
v 采用B+树,还是HASH索引则由具体的RDBMS来决定
v 索引是关系数据库的内部实现技术,属于内模式的范畴
v CREATE INDEX语句定义索引时,可以定义索引是唯一索引、非唯一索引或聚簇索引
嘿嘿嘿,好了,了解完一些基础之后,我们就进入到建立和删除的知识点了
建立
v 语句格式
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);
[例13] CREATE CLUSTER INDEX Stusname ON Student(Sname);
- 在Student表的Sname(姓名)列上建立一个聚簇索引
Sc表按学号升序和课程号降序建唯一索引:
Create unique index scno on sc(sno asc,cno desc);
建表注意事项:
v 在最经常查询的列上建立聚簇索引以提高查询效率
v 一个基本表上最多只能建立一个聚簇索引
v 经常更新的列不宜建立聚簇索引
修改索引
对于已经建立的索引,如果需要对其重新命名,可是使用ALTER INDEX语句。其一般格式是:
ALTER INDEX <旧索引名> RENAME TO <新索引名>;
删除索引
DROP INDEX <索引名>;
删除索引时,系统会从数据字典中删去有关该索引的
描述。
[例15] 删除Student表的Stusname索引
DROP INDEX Stusname;
以上是关于数据库语句的主要内容,如果未能解决你的问题,请参考以下文章