一次flannel和Docker网络不通定位问题
Posted ericnie的技术博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次flannel和Docker网络不通定位问题相关的知识,希望对你有一定的参考价值。
查看路由表的配置
路由表情况
[root@k8s-master ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.44.1 0.0.0.0 UG 100 0 0 enp0s3 10.1.0.0 0.0.0.0 255.255.0.0 U 0 0 0 flannel0 10.1.19.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0 192.168.44.0 0.0.0.0 255.255.255.0 U 100 0 0 enp0s3 192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
10.1.0.0为flannel0网段
而在这台机器上启动的pod都是在10.1.19.0网段的
node的节点路由表
[root@node1 flannel]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.44.1 0.0.0.0 UG 100 0 0 enp0s3 10.1.0.0 0.0.0.0 255.255.0.0 U 0 0 0 flannel0 10.1.28.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0 192.168.44.0 0.0.0.0 255.255.255.0 U 100 0 0 enp0s3 192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
10.1.0.0为flannel0网段
而在这台机器上启动的pod都是在10.1.28.0网段的
所有pod的ip地址
[root@k8s-master ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE helloworld-service-2437162702-r9v2q 2/2 Running 9 9d 10.1.28.3 node1 helloworld-service-v2-2637126738-s284c 2/2 Running 10 9d 10.1.28.4 node1 istio-egress-2869428605-2ftgl 1/1 Running 6 13d 10.1.28.6 node1 istio-ingress-1286550044-6g3vj 1/1 Running 6 13d 10.1.28.5 node1 istio-mixer-765485573-23wc6 1/1 Running 6 13d 10.1.28.7 node1 istio-pilot-1495912787-g5r9s 2/2 Running 11 13d 10.1.28.9 node1 tool-185907110-ms991 2/2 Running 4 8d 10.1.28.8 node1
正常情况下,ping pod节点的网络应该是通的
[root@k8s-master ~]# ping 10.1.28.3 PING 10.1.28.3 (10.1.28.3) 56(84) bytes of data. 64 bytes from 10.1.28.3: icmp_seq=1 ttl=61 time=0.967 ms 64 bytes from 10.1.28.3: icmp_seq=2 ttl=61 time=1.88 ms 64 bytes from 10.1.28.3: icmp_seq=3 ttl=61 time=0.867 ms 64 bytes from 10.1.28.3: icmp_seq=4 ttl=61 time=2.23 ms
整个通讯链路原理及报文追踪
整个链路简单的图如下
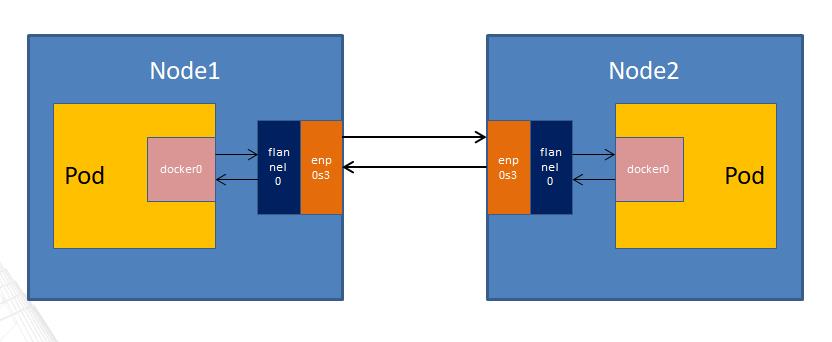
比较详细的可以参考下面这张
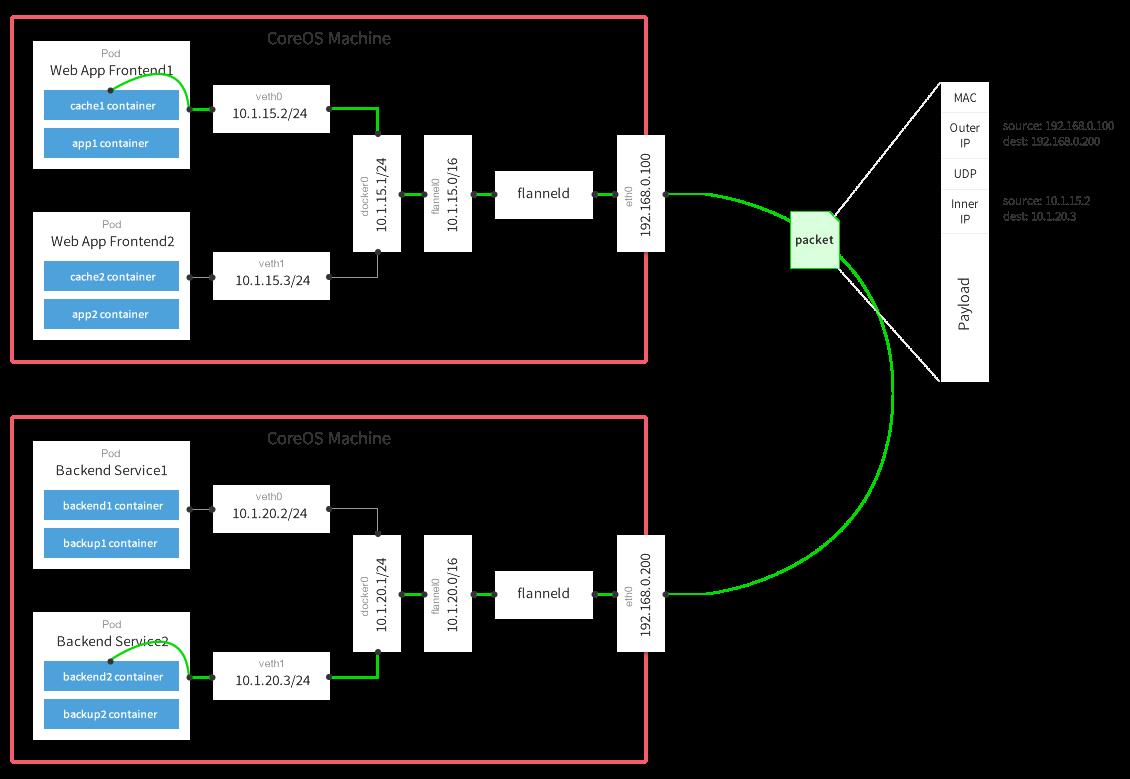
- 数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
- Flannel通过Etcd服务维护了一张节点间的路由表。
- 源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直 接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容 器。
所以要定位网络的不通就需要一步步的看报文是在哪处的转发出了问题。
源端网络
首先查看发器端的flannel0的地址
[root@k8s-master ~]# ifconfig docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 10.1.19.1 netmask 255.255.255.0 broadcast 0.0.0.0 ether 02:42:3a:a6:1d:bb txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.44.108 netmask 255.255.255.0 broadcast 192.168.44.255 inet6 fe80::a00:27ff:fee2:ae0a prefixlen 64 scopeid 0x20<link> ether 08:00:27:e2:ae:0a txqueuelen 1000 (Ethernet) RX packets 20866 bytes 2478600 (2.3 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 21990 bytes 13812121 (13.1 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 flannel0: flags=4305<UP,POINTOPOINT,RUNNING,NOARP,MULTICAST> mtu 1472 inet 10.1.19.0 netmask 255.255.0.0 destination 10.1.19.0 unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC) RX packets 14 bytes 1176 (1.1 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 14 bytes 1176 (1.1 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
然后运行下面命令监听从flannel0出去的任何的包
tcpdump -i flannel0 -nn host 10.1.19.0
同时再找个窗口ping pod,这是收到的信息是 ping 10.1.28.3
[root@k8s-master ~]# tcpdump -i flannel0 -nn host 10.1.19.0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on flannel0, link-type RAW (Raw IP), capture size 65535 bytes 16:28:43.961488 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4520, seq 1, length 64 16:28:43.963340 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4520, seq 1, length 64 16:28:44.962567 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4520, seq 2, length 64 16:28:44.963339 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4520, seq 2, length 64 16:28:45.966388 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4520, seq 3, length 64 16:28:45.966962 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4520, seq 3, length 64 16:28:46.967629 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4520, seq 4, length 64 16:28:46.968486 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4520, seq 4, length 64
可以看到报文已经发出,然后看发送端的物理网卡enp0s3,继续运行ping命令,然后看有没有转发到物理网卡的包
因为是master节点,所以有很多8080,443端口发的包,可以忽略,真实环境中相对比较少.核心可以看最后为UDP,length 84,属于把ping的包64封装后的包的大小。
[root@k8s-master ~]# tcpdump -i enp0s3 -nn host 192.168.44.109 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on enp0s3, link-type EN10MB (Ethernet), capture size 65535 bytes 16:46:59.146611 IP 192.168.44.108.8080 > 192.168.44.109.50060: Flags [P.], seq 1518764712:1518765120, ack 650646529, win 327, options [nop,nop,TS val 4304586 ecr 7794005], length 408 16:46:59.146863 IP 192.168.44.108.443 > 192.168.44.109.51564: Flags [P.], seq 474973224:474973663, ack 3595606551, win 248, options [nop,nop,TS val 4304586 ecr 7794006], length 439 16:46:59.147013 IP 192.168.44.109.50060 > 192.168.44.108.8080: Flags [.], ack 408, win 1424, options [nop,nop,TS val 7794610 ecr 4304586], length 0 16:46:59.147301 IP 192.168.44.109.51564 > 192.168.44.108.443: Flags [.], ack 439, win 1407, options [nop,nop,TS val 7794610 ecr 4304586], length 0 16:46:59.224901 IP 192.168.44.109.5353 > 224.0.0.251.5353: 0*- [0q] 1/0/0 (Cache flush) PTR node1.local. (109) 16:46:59.259598 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [P.], seq 3602262654:3602262700, ack 901869271, win 1407, options [nop,nop,TS val 7794724 ecr 4297197], length 46 16:46:59.267671 IP 192.168.44.108.8285 > 192.168.44.109.8285: UDP, length 84 16:46:59.269133 IP 192.168.44.109.8285 > 192.168.44.108.8285: UDP, length 84 16:46:59.270082 IP 192.168.44.108.443 > 192.168.44.109.34266: Flags [P.], seq 1:66, ack 46, win 1432, options [nop,nop,TS val 4304709 ecr 7794724], length 65 16:46:59.270419 IP 192.168.44.108.443 > 192.168.44.109.34266: Flags [P.], seq 66:639, ack 46, win 1432, options [nop,nop,TS val 4304709 ecr 7794724], length 573 16:46:59.270734 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [.], ack 66, win 1407, options [nop,nop,TS val 7794735 ecr 4304709], length 0 16:46:59.271040 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [.], ack 639, win 1407, options [nop,nop,TS val 7794735 ecr 4304709], length 0 16:46:59.272370 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [P.], seq 46:94, ack 639, win 1407, options [nop,nop,TS val 7794736 ecr 4304709], length 48 16:46:59.272522 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [P.], seq 94:667, ack 639, win 1407, options [nop,nop,TS val 7794736 ecr 4304709], length 573 16:46:59.272743 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [P.], seq 667:705, ack 639, win 1407, options [nop,nop,TS val 7794736 ecr 4304709], length 38 16:46:59.278885 IP 192.168.44.108.443 > 192.168.44.109.34266: Flags [.], ack 705, win 1432, options [nop,nop,TS val 4304718 ecr 7794736], length 0 16:46:59.283084 IP 192.168.44.108.443 > 192.168.44.109.34266: Flags [P.], seq 639:681, ack 705, win 1432, options [nop,nop,TS val 4304722 ecr 7794736], length 42 16:46:59.283224 IP 192.168.44.108.443 > 192.168.44.109.34266: Flags [P.], seq 681:723, ack 705, win 1432, options [nop,nop,TS val 4304722 ecr 7794736], length 42 16:46:59.284143 IP 192.168.44.109.34266 > 192.168.44.108.443: Flags [.], ack 723, win 1407, options [nop,nop,TS val 7794748 ecr 4304722], length 0 16:46:59.287279 IP 192.168.44.108.8080 > 192.168.44.109.50060: Flags [P.], seq 408:824, ack 1, win 327, options [nop,nop,TS val 4304726 ecr 7794610], length 416 16:46:59.287584 IP 192.168.44.109.50060 > 192.168.44.108.8080: Flags [.], ack 824, win 1424, options [nop,nop,TS val 7794751 ecr 4304726], length 0
命令确认ping命令的包发到192.168.44.109
目标段网络
再去node1目标端,看物理网卡的收包情况,源端继续运行ping
[root@node1 flannel]# tcpdump -i enp0s3 -nn host 192.168.44.108 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on enp0s3, link-type EN10MB (Ethernet), capture size 65535 bytes 16:49:04.022476 IP 192.168.44.108.8285 > 192.168.44.109.8285: UDP, length 84 16:49:04.022827 IP 192.168.44.109.8285 > 192.168.44.108.8285: UDP, length 84 16:49:05.022980 IP 192.168.44.108.8285 > 192.168.44.109.8285: UDP, length 84 16:49:05.023425 IP 192.168.44.109.8285 > 192.168.44.108.8285: UDP, length 84 16:49:05.273652 IP 192.168.44.108.8080 > 192.168.44.109.50060: Flags [P.], seq 1518824053:1518824479, ack 650646776, win 336, options [nop,nop,TS val 4430711 ecr 7919368], length 426 16:49:05.273754 IP 192.168.44.109.50060 > 192.168.44.108.8080: Flags [.], ack 426, win 1424, options [nop,nop,TS val 7920736 ecr 4430711], length 0 16:49:05.273951 IP 192.168.44.108.443 > 192.168.44.109.51564: Flags [P.], seq 475036916:475037373, ack 3595607190, win 248, options [nop,nop,TS val 4430711 ecr 7919369], length 457 16:49:05.274091 IP 192.168.44.109.51564 > 192.168.44.108.443: Flags [.], ack 457, win 1407, options [nop,nop,TS val 7920737 ecr 4430711], length 0
发现源端有包过来,正常
在目标节点node1上运行,10.1.19.0是源端的flannel0地址,正常。
[root@node1 flannel]# tcpdump -i flannel0 -nn host 10.1.19.0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on flannel0, link-type RAW (Raw IP), capture size 65535 bytes 16:51:49.795788 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4797, seq 1, length 64 16:51:49.795911 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4797, seq 1, length 64 16:51:50.797484 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4797, seq 2, length 64 16:51:50.797566 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4797, seq 2, length 64 16:51:51.796934 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4797, seq 3, length 64 16:51:51.797024 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4797, seq 3, length 64 16:51:52.800567 IP 10.1.19.0 > 10.1.28.3: ICMP echo request, id 4797, seq 4, length 64 16:51:52.800641 IP 10.1.28.3 > 10.1.19.0: ICMP echo reply, id 4797, seq 4, length 64
最后看目标端docker0有没有报文,28.3目标pod地址
tcpdump -i docker0 -nn host 10.1.28.3
问题定位
遇到的问题是目标端flannel0上有包发过来,但docker0网段没有任何包。
所以定位是目标段的flannel0->docker0的转发出了问题。
通过iptables -nvL 查看现有的iptables规则,发现
chain FORWARD链路 policy是DROP,以下命令修改
iptables -P FORWARD ACCEPT
另外查宿主机的 ip forward是否有问题
sysctl -a | grep ip_forward
源端如何找到目标端地址
全靠flannel会找etcd的中的数据,然后进行路由
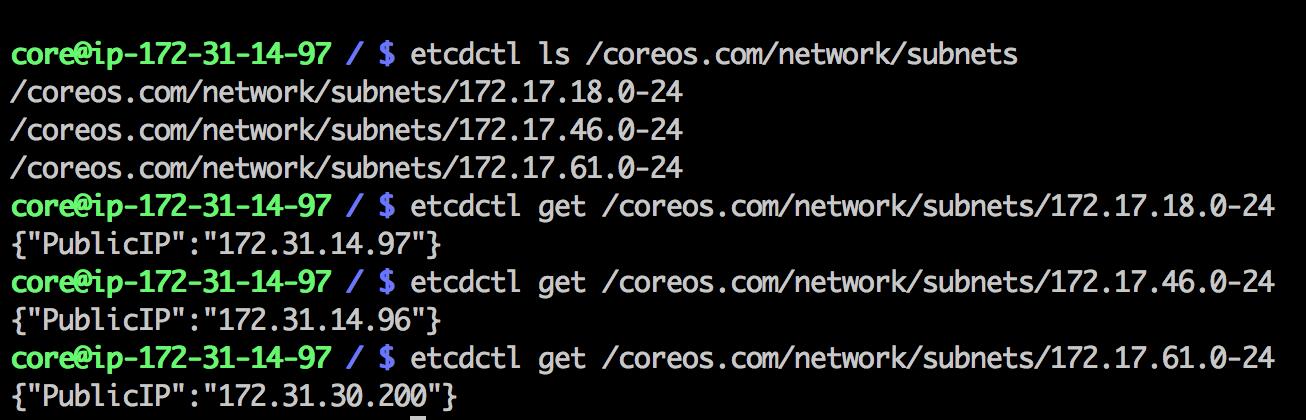
华丽的分割线
====================================================================================
服务启动顺序
Kubernetes启动这些服务的顺序非常重要
先是flannel Service
flannel服务启动时主要做了以下几步的工作:
- 从etcd中获取network的配置信息
- 划分subnet,并在etcd中进行注册
- 将子网信息记录到
/run/flannel/subnet.env中
cat /run/flannel/subnet.env FLANNEL_NETWORK=10.0.0.0/16 FLANNEL_SUBNET=10.0.53.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=false
- 之后将会有一个脚本将subnet.env转写成一个docker的环境变量文件
/run/flannel/docker
cat /run/flannel/docker DOCKER_OPT_BIP="--bip=10.0.53.1/24" DOCKER_OPT_IPMASQ="--ip-masq=true" DOCKER_OPT_MTU="--mtu=1450" DOCKER_NETWORK_OPTIONS=" --bip=10.0.53.1/24 --ip-masq=true --mtu=1450 "
然后是Docker服务
Docker服务会根据flannel拿到的网段然后把pod启动在这些网段,这样Kubernetes在寻址pod的时候就会找到相应的宿主机,进行通讯。
如果Docker服务和Flannel服务没有这种关联关系的化,很可能Docker先用原来的ip段启动,而这个段并没有写到etcd中,导致寻址失败。
这就是在另一次定位问题的出错点。
==============================================================
验证是否开墙开通
nc -u 10.93.0.131 (host B) 8472
输入字符
再host B上,通过tcpdump -i eth0 -nn host hostA来验证是否能收到报文
以上是关于一次flannel和Docker网络不通定位问题的主要内容,如果未能解决你的问题,请参考以下文章