记一次TokuMX数据库集群恢复
Posted InDulGed
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次TokuMX数据库集群恢复相关的知识,希望对你有一定的参考价值。
中午在昏睡中接到电话,服务器扩容后数据库启动不了了,于是不假思索的想到了TokuMX需要关闭对透明大页的使用才可以正常启动,而这点恰巧大家都不是很清楚,在这里写下关闭的shell: echo never > /sys/kernel/mm/transparent_hugepage/enabled 一般情况下将其写入开机启动脚本,否则数据库不能正常启动。
然而当我远程查看了服务器后彻底懵逼了,数据库不见了,印象中服务安装在dev挂载点下,于是我翻遍了dev,全盘grep,find和tokumx相关的文件,后来只查到一些无关痛痒的东西,慌了。
谁会大意把数据库删了,或者说是我印象中记错目录了,慌乱中查找了home,opt,etc….等等等等,把整个服务器翻了个遍都没有找到踪迹,一个念头一闪而过,不是每台服务器都做了开机启动吗,里边儿不就有数据库路径。心知这个小问题要被解决掉了,打开rc.local一看:这是个大问题(其实我的内心是崩溃的,千万头羊驼在愉快地奔跑)..我不信,我不接受这个事实,于是又到dev下翻了个遍,各种grep,连find -name命令我都不相信。事实告诉我不信也没用,然而没有就是没有。
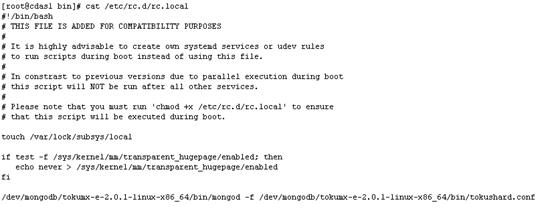
我开始怀疑是不是有人删掉了数据库,此时我还是很淡定的,因为我们还有备份机,最差也能找到数据库的正确安装路径吧。每当我沾沾自喜拥有聪明才智时,现实总会将我乱棒打醒。备份机离线了….电话得知为了扩容备份机也关了,于是告知开机取备份。然后,备份机也完蛋了,同样的目录,什么也没有…安排后事吧,死了就得葬,管杀就得管埋,领导负责给客户做好善后工作,我开始埋。到此时我仍然认为是有人无意中觉得这个目录下多了个奇怪的文件夹看着不顺眼删了,而这个目录正好是我们的数据库目录。
于是我开始了漫无目的的查找系统日志,各种搜索文件夹删除日志,linux系统日志,查看了/var/log下的各种日志并没有得到任何有用的内容。
我甚至想到了数据恢复,网上看了各种linux系统下的数据恢复方式和工具,尝试了各种搜索,但是想到了之前一些事情的粗心大意考虑欠稳妥,于是把数据恢复方案作为最后的手段,告一段落。。。
理理思路,因为主服务的数据库装载dev挂载点下,备份机为了保持一致也方便记忆,也没多想都装同一挂载点了,于是改变了搜索关键词:dev子目录丢失,我想我得到了答案
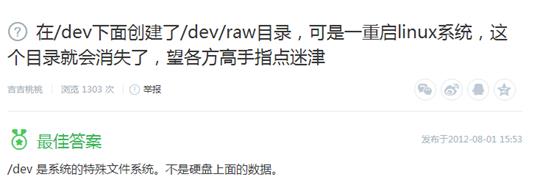
仍然不死心,直到我看到了这个答案后的尝试。mount /dev/mongodb ,各种mount,花式mount,提示在/etc/estab/ 下并没有此挂载点,事实上是没有此挂载点的记录,多次尝试,没用。
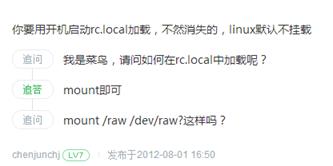
为了证明上面说法的真实性,亲手做了实验,在dev下建立了test目录,里面touch了123.txt,reboot,查看,没了。
意思很明确,数据库找不回来了,所有的东西都得从头开始。功夫不负有心人,领导的提示,我想到了补救措施,数据库文件和数据库应该不在同一目录下,欣喜的发现了库里的所有文件一一罗列在此了(这个目录的名称toku拼写错了)

接下来怎么办,想到初来公司时就是因为误改了数据库路径导致了数据库加载不上,然而就算是有这些文件没有原来的集群配置又有什么用。但是想想这么大的公司做出来的软件不应该会这么傻,而当初是因为对linux操作系统和mongodb的不了解和畏惧没有深究导致的,这次不论如何我要把这些数据恢复回去。
此时因为以前用mongodb时试过直接更改配置文件中的dbpath是不管用的,甚至不确定更改了dbpath配置数据库文件会不会被重建,本着谨慎的态度我重装了tokumx,这次将数据库安装指定在home目录下,数据库文件目录也指定在新的tokumx安装目录下:/home/tokumx/data/(感慨一下一键安装真好用,省了不少时间)。
到这里两台服务器的tokumx重装完毕,集群貌似有点小问题,手动处理了一下将集群恢复。
这次和之前不一样的地方在于,数据库是以集群的方式运转的,假设只恢复了数据那么集群是否还能正常运转?不管怎么样先弄好一台服务器用standalone模式也行,于是我搜索各种mongodb数据导入方式,得知用mongoimport,用mongoimport –h查看了帮助,告知用--dbpath指定导入文件夹。于是./mongoimport --dbpath /home/cdasTuko/data/ 结果呢,mongoimport只支持json,csv等等类型的导入。于是接着搜索如何直接加载数据库文件,像sqlserver的分离和加载那样,得不到任何有用的答案。Mongorestore也不适用。
后来想了想TokuMX毕竟不是Mongodb,它有更多人性化的一面,何不尝试一下直接修改dbpath,万一能加载上呢,就算没了还有备份机呢。给自己壮了壮胆,确认了备份机上的数据库文件存在后开始动手。
理了下思路,大概是这样的:为了不影响集群,先修改standalone模式的配置文件,以非集群的方式启动,如果能加载上就把集群的配置文件做同样修改,如果集群启动不了就删除一台机器的数据库让集群自动同步过去。
停止数据库服务
./mongod –shutdown –f tokuShard.cfg
修改standalone的配置文件
vi tokumx.cfg
修改:dbpath=/home/cdasTuko/data/
重新启动,用standalone的配置
./mongod –f tokumx.cfg
启动完成,赶紧查了查数据,一个不少都在。成功!激动万分!
接下来的工作就简单了,数据在,数据库在,集群搭起来不就好了,于是按照上述方法修改了tokuShard.cfg 将里面的dbpath更变成旧的数据库路径,备份机的也一样。修改完成,分别以集群配置文件启动两台服务器的TokuMX,万分幸运,成功了。此时虽已凌晨却因高兴完全没睡意,兴冲冲的连接到集群看了看状态

STARTUP2是个什么鬼?能吃吗???搜索了关于Mongo集群的stateStr的各种含义,等待,1分钟,2分钟,5分钟,10分钟过去了 ,仍然是STARTUP2,心想不好,有事情要发生。赶紧打开RoboMongo查了查库,果不其然,两台服务器都不能查询,处于假死状态,任何操作都不管用。再一次心灰意冷。
仔细看了看上面显示的时间,又懵了,完全对不上号,于是用date命令查看了两台服务器的时间,相差1分钟左右,会不会是因为这里导致同步不了,用date –s 命令手动修改了两台服务器时间,让其保持相差在10秒之内(时间同步服务可能没有起作用)。
date –s 02:44
然后shutdown集群,重新启动。情况没有转变,再看了看rs.status(),看到状态:
replSet initial sync pending
集群初始化同步挂起…于是按照此关键词搜索了一堆文章,有人提出使用rs.SlaveOK(),分别在两台服务器上执行,无果。想到了集群的特殊性,是否不能直接去修改数据库路径,否则影响到集群正常运转,是否有其它配置记录在admin或者local库里,于是我翻遍了两台服务器的local和admin库的表,得到唯一感觉不大对的是集群操作日志表中的dbpath字段还记录着安装时的/home/tokumx/data/ ,虽然是日志感觉没什么用吧,反正已经到这一步了,就把看到的dbpath都替换成旧的数据库文件路径(/home/cdasTuko/data/)。
想了想觉得正常的集群配置和现在的是不是有什么差别,于是打开了本地的虚拟机,查看了虚拟机上的local库,发现并无差异。
可能是兴奋冲昏了头脑,许久才想起来还有日志,为了清晰明了,我清空了日志文件夹,重新启动集群,5分钟后赶紧打开了log文件cat /home/tokumx/log/tokumx.log
我看到了几行非常有意思的话:
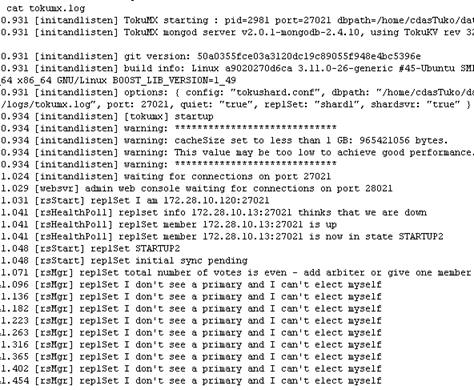
我找不到主服务,而且我不能选举自己(因为是主从备份)
于是搜索到了如下的解决方案,重置集群配置:

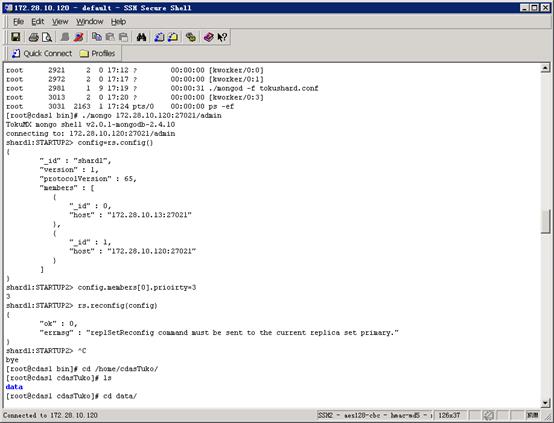
在两台服务器上分别执行后并没有什么效果,即使使用admin登录也完全没用。后来找到相关资料说,集群在选举主服务的时候会有个优先级,修改优先级后重启集群会选举出主服务,于是我们连接到集群,获取到配置文件,这里将其中一台优先级调到3:
config=rs.config()
config.members[0].priority=3 (这里数字越大表示优先级越高,默认是1)
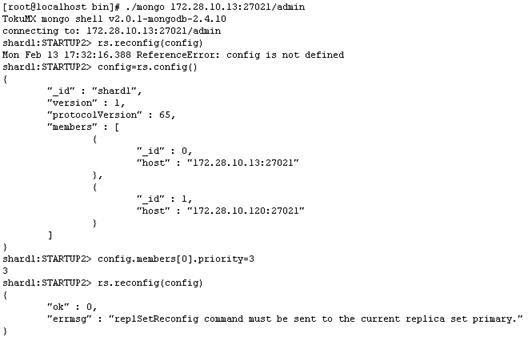
然而我得到的还是失败。虽有个备选方案就是删掉备份机的所有数据,重置集群,自动去同步主服务的数据,但是这个方案动静太大,难以确保万无一失,数据量之大不知道什么时候才能同步完,迫不得已再使用此方案。
于是回到初始问题上,集群卡在状态StartUp2上,花样搜索嘛,国内没有什么有用的信息,看来还得求助歪果仁了,改变搜索内容:replicaset stuck at startup2。别说还真管用,万能的stackoverflow,以负载均衡闻名程序猿界的网站得到了答案
看了看楼主和解答者的对话,发现和我遇到的一模一样.
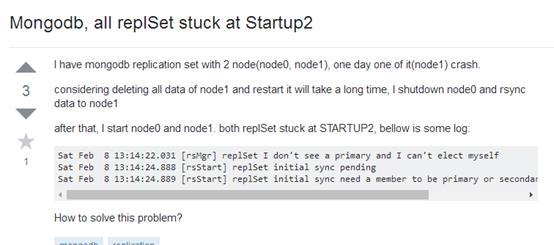
这里版主和解答者的对话有好几种解决方案,步骤写的很详细,内容较多这里贴上地址
http://stackoverflow.com/questions/21642396/mongodb-all-replset-stuck-at-startup2
这里我只使用了第一步,强制重置集群状态,敲下回车的那一刻我知道管用了,别问我为什么知道,因为我看见它卡住不动了,而不是立马返回了错误信息。
丢了个盹儿,大概过了半个小时,回到服务器一看报错了,但是紧接着下面的集群状态已经是PRIMARY。这意味着这么久的努力终于得到回报了。

大悲大喜,情绪起伏的一晚上,真是惊心动魄也无比欢乐,大问题解决了还睡什么觉,趁刚做完还有印象,趁热打铁记下此文,以备不时之患。
以上是关于记一次TokuMX数据库集群恢复的主要内容,如果未能解决你的问题,请参考以下文章
记一次虚机强制断电 K8s 集群 etcd pod 挂掉快照丢失(没有备份)问题处理
记一次虚机强制断电 K8s 集群 etcd pod 挂掉快照丢失(没有备份)问题处理
记一次虚机强制断电 K8s 集群 etcd pod 挂掉快照丢失(没有备份)问题处理