When run SparkSubmit --class [mainClass], SparkSubmit will call a childMainClass which is
1. client mode, childMainClass = mainClass
2. standalone cluster mde, childMainClass = org.apache.spark.deploy.Client
3. yarn cluster mode, childMainClass = org.apache.spark.deploy.yarn.Client
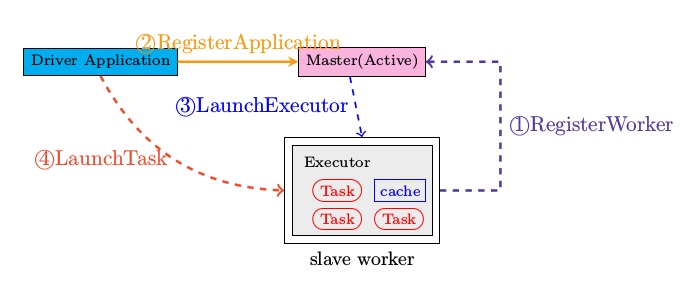
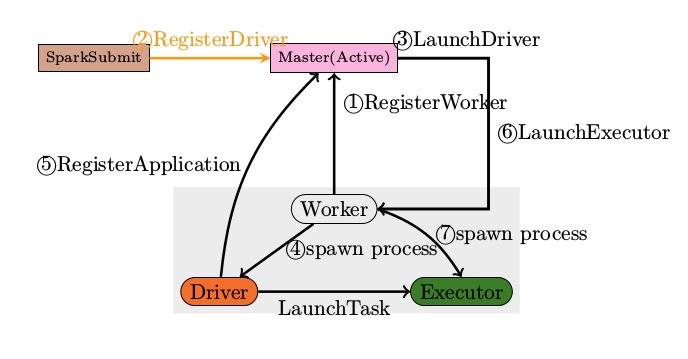
Bundling Your Application’s Dependencies
If your code depends on other projects, you will need to package them alongside your application in order to distribute the code to a Spark cluster. To do this, to create an assembly jar (or “uber” jar) containing your code and its dependencies. Both sbt and Maven have assembly plugins. When creating assembly jars, list Spark and Hadoop as provided dependencies; these need not be bundled since they are provided by the cluster manager at runtime. Once you have an assembled jar you can call the bin/spark-submit script as shown here while passing your jar.
For Python, you can use the --py-files argument of spark-submit to add .py, .zip or .egg files to be distributed with your application. If you depend on multiple Python files we recommend packaging them into a .zip or .egg.
备注:
1.必须将项目打包成assembly jars 的形式
2.可以使用maven assembly插件进行打包
3.如果是使用idea开发,可以使用idea的buid方式进行打包
Launching Applications with spark-submit
Once a user application is bundled, it can be launched using the bin/spark-submit script. This script takes care of setting up the classpath with Spark and its dependencies, and can support different cluster managers and deploy modes that Spark supports:
./bin/spark-submit \\
--class <main-class>
--master <master-url> \\
--deploy-mode <deploy-mode> \\
--conf <key>=<value> \\
... # other options
<application-jar> \\
[application-arguments]
Some of the commonly used options are:
--class: The entry point for your application (e.g.org.apache.spark.examples.SparkPi)--master: The master URL for the cluster (e.g.spark://23.195.26.187:7077)--deploy-mode: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default:client)*--conf: Arbitrary Spark configuration property in key=value format. For values that contain spaces wrap “key=value” in quotes (as shown).application-jar: Path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, anhdfs://path or afile://path that is present on all nodes.application-arguments: Arguments passed to the main method of your main class, if any
*A common deployment strategy is to submit your application from a gateway machine that is physically co-located with your worker machines (e.g. Master node in a standalone EC2 cluster). In this setup, client mode is appropriate. In client mode, the driver is launched directly within the client spark-submit process, with the input and output of the application attached to the console. Thus, this mode is especially suitable for applications that involve the REPL (e.g. Spark shell).
Alternatively, if your application is submitted from a machine far from the worker machines (e.g. locally on your laptop), it is common to usecluster mode to minimize network latency between the drivers and the executors. Note that cluster mode is currently not supported for standalone clusters, Mesos clusters, or python applications.
备注:
1.cluster 模式是支持程序自动重启的.
2.重要的事说三遍,重要的事说三遍,重要的事说三遍: cluster 模式不支持standalone clusters, Mesos clusters, or python applications模式.
三.关于checkpoint
1. spark streaming 的checkpoint 有点坑,如果程序有升级,代码结构有变化,重新部署的时候需要删除checkpoint文件夹,不然会报错。但是删除了checkpoint 文件夹,程序里的rdd状态会丢失。
2.spark streaming checkpoint的升级方案是使用structed streaming 的checkpoint ,structed streaming 的checkpoint 支持程序升级。