MMU
Posted Darren_pty
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MMU相关的知识,希望对你有一定的参考价值。
MMU即内存管理单元,它负责虚拟地址到物理地址的映射,并提供硬件机制的内存访问权限检查。MMU使得每个用户进程拥有自己独立的地址空间,并通过内存访问权限的检查保护每个进程所用的内存不被其他进程破坏,它是一个与软件密切相关的硬件部件,也是理解linux等操作系统内核机制的最大障碍之一。
①地址映射
②内存访问权限检查
1)为什么会有虚拟内存和物理内存的区别?
正在运行的一个进程,他所需的内存是有可能大于内存条容量之和的,比如你的内存条是256M,你的程序却要创建一个2G的数据区,那么不是所有数据都能一起加载到内存(物理内存)中,势必有一部分数据要放到其他介质中(比如硬盘),待进程需要访问那部分数据时,在通过调度进入物理内存。所以,虚拟内存是进程运行时所有内存空间的总和,并且可能有一部分不在物理内存中,而物理内存就是我们平时所了解的内存条。有的地方呢,也叫这个虚拟内存为内存交换区。
虚拟地址/物理地址
2) 没有启动MMU时,CPU内部执行单元产生的内存地址信号将直接通过地址总线发送到芯片引脚,被内存芯片接收,这就是物理地址(physical address),简称PA,这时CPU核心,cache,外设等所有部件使用的都是物理地址。
启动MMU后,CPU执行单元产生的地址信号在发送到内存芯片之前将被MMU截获,这个地址信号称为虚拟地址(virtual address),简称VA,MMU会负责把VA翻译成另一个地址,然后发到内存芯片地址引脚上,即CPU核心对外发出虚拟地址VA;VA被转换为MVA供cache,MMU使用,在这里MVA被转换成PA;最后使用PA读取实际设备
①CPU核心看到和用到的只是虚拟地址VA,至于VA如果去对应物理地址PA,CPU核心不理会
②caches和MMU看不到VA,他们利用MVA转换得到PA
③实际设备看不到VA、MVA,读写它们使用的是物理地址PA
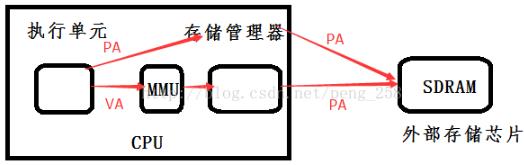
硬件上MMU一般封装于CPU芯片内部,虚拟地址又是CPU内部执行单元产生的,发送给MMU的地址。所以虚拟地址一般只存在于CPU内部,到了CPU外部地址总线引脚上的信号就是MMU转换过的物理地址。
软件上MMU对用户程序不可见,在启用MMU的平台上用户C程序中变量和函数背后的数据/指令地址等都是虚拟地址,这些虚拟内存地址从CPU执行单元发出后,都会首先被MMU拦截并转换成物理地址,然后再发送给内存。也就是说用户程序运行*a =100;"这条赋值语句时,假设debugger显示指针a的值为0x30004000(虚拟地址),但此时通过硬件工具(如逻辑分析仪)侦测到的CPU与外存芯片间总线信号很可能是另外一个值,如0x8000(物理地址)。当然对一般程序员来说,只要上述语句运行后debugger显示0x30004000位置处的内存值为100就行了,根本无需关心a的物理地址是多少。但进行OS移植或驱动开发的系统程序员不同,他们必须清楚软件如何在幕后辅助硬件MMU完成地址转换。
3)页/页帧/页表/页表项(PTE)
MMU是负责把虚拟地址映射为物理地址,但凡"映射"都要解决两个问题:映射的最小单位和映射的规则。
MMU中VA到PA映射的最小单位称为页,映射的最低单位是单个虚拟页到物理页,页大小通常是4K,即一次最少要把4K大小的VA页块整体映射到4K的PA页块(从0开始4K对齐划分页块),页内偏移不变,如VA的一页0x30004000~0x30004fff被映射到PA的一页 0x00008000~0x00008fff,当CPU执行单元访问虚拟地址0x30004008,实际访问的物理地址是0x00008008(0x30004008和0x00008008分别位于虚实两套地址空间,互不相干,不存在重叠和冲突)。以页为最小单位,就是不能把VA中某一页划分成几小块分别映射到不同PA,也不能把VA中属于不同页的碎块映射到PA某一页的不同部分,必须页对页整体映射。
页帧是指物理内存中的一页内存,MMU虚实地址映射就是寻找物理页帧的过程。
MMU软件配置的核心是页表,它描述MMU的映射规则,即虚拟内存哪(几)个页映射到物理内存哪(几)个页帧。页表由一条条代表映射规则的记录组成,每一条称为一个页表条目(PTE),整个页表保存在片外内存,MMU通过查找页表确定一个VA应该映射到什么PA,以及是否有权限映射。
4)TLB
如果MMU每次地址转换都到位于外部内存的页表上查找PTE,转换速度就会大大降低,于是出现了TLB 即转换快表,又简称快表,可以理解为MMU内部专用的存放页表的cache,保存着最近使用的PTE乃至全部页表。MMU接收到虚拟地址后,首先在TLB中查找,如果找到该VA对应的PTE就直接转换,找不到再去外存页表查找,并置换进TLB。TLB属于片上SRAM,访问速度快,通过TLB缓存PTE可以节省MMU访问外存页表的时间,从而加速虚实地址转换。TLB和CPU cache的工作原理一样,只是TLB专用于为MMU缓存页表。
注:cache中文是高速缓冲存储器,一种特殊的存储器子系统,其中复制了频繁使用的数据以利于快速访问。存储器的高速缓冲存储器存储了频繁访问的 RAM 位置的内容及这些数据项的存储地址。当处理器引用存储器中的某地址时,高速缓冲存储器便检查是否存有该地址。如果存有该地址,则将数据返回处理器;如果没有保存该地址,则进行常规的存储器访问。因为高速缓冲存储器总是比主RAM 存储器速度快,所以当 RAM 的访问速度低于微处理器的速度时,常使用高速缓冲存储器。
5)MMU的内存保护功能
既然所有发往内存的地址信号都要经过MMU处理,那让它只单单做地址转换,岂不是浪费了这个特意安插的转换层?显然它有能力对虚地址访问做更多的限定(就像路由器转发网络包的同时还能过滤各种非法访问),比如内存保护。可以在PTE条目中预留出几个比特,用于设置访问权限的属性,如禁止访问、可读、可写和可执行等。设好后,CPU访问一个VA时,MMU找到页表中对应PTE,把指令的权限需求与该PTE中的限定条件做比对,若符合要求就把VA转换成PA,否则不允许访问,并产生异常。
6)多级页表
虚拟地址由页号和页内偏移组成。
前面说过MMU映射以页为最小单位,假设页大小为4K,那么无论页表怎样设置,虚拟地址后12比特与MMU映射后的物理地址后12比特总是相同,这不变的比特位就是页内偏移。为什么不变?把搭积木想象成一种映射,不管你怎么搭,你也改变不了每块积木内部的原子排列吧。所谓以页为最小单位就是保持一部分不变作为最小粒度。
页号就更有故事了,一个32bits虚拟地址,可以划分为220个内存页,如果都以页为单位和物理页帧随意映射,页表的空间占用就是220*sizeof(PTE)*进程数(每个进程都要有自己的页表),PTE一般占4字节,即每进程4M,这对空间占用和MMU查询速度都很不利。
问题是实际应用中不需要每次都按最小粒度的页来映射,很多时候可以映射更大的内存块。因此最好采用变化的映射粒度,既灵活又可以减小页表空间。具体说可以把20bits的页号再划分为几部分(如下图linux的3级划分),
|
PGD(16bits) |
PMD(4bits) |
PTE(4bits) |
Offset(12bits) |
简单说每次MMU根据虚拟地址查询页表都是一级级进行,先根据PGD的值查询,如果查到PGD的匹配,但后续PMD和PTE没有,就以2(offset+pte+pmd)=1M为粒度进行映射,后20bits全部是块内偏移,与物理地址相同。
依次类推,具体可参考WolfGang Mauerer的professional linux kernel architecture的1.3.4节,以及各CPU的Spec中MMU章节,查看MMU组合出物理地址的详细过程。
7)操作系统和MMU
实际上MMU是为满足操作系统越来越复杂的内存管理而产生的。OS和MMU的关系简单说:
a.系统初始化代码会在内存中生成页表,然后把页表地址设置给MMU对应寄存器,使MMU知道页表在物理内存中的什么位置,以便在需要时进行查找。之后通过专用指令启动MMU,以此为分界,之后程序中所有内存地址都变成虚地址,MMU硬件开始自动完成查表和虚实地址转换。
b.OS初始化后期,创建第一个用户进程,这个过程中也需要创建页表,把其地址赋给进程结构体中某指针成员变量。即每个进程都要有独立的页表。
c.用户创建新进程时,子进程拷贝一份父进程的页表,之后随着程序运行,页表内容逐渐更新变化。比较复杂了,几句讲不清楚,不多说了哈,有时间讲linux的话再说吧
8)总结
相关概念讲完,VA到PA的映射过程就一目了然:MMU得到VA后先在TLB内查找,若没找到匹配的PTE条目就到外部页表查询,并置换进TLB;根据PTE条目中对访问权限的限定检查该条VA指令是否符合,若不符合则不继续,并抛出异常;符合后根据VA的地址分段查询页表,保持offset(广义)不变,组合出物理地址,发送出去。
在这个过程中,软件的工作核心就是生成和配置页表。
下面我们通过一个实例进行验证一下:
我们知道2440的寄存器值地址范围在0x48000000-0x5fffffff之间,我们可以将程序分为两部分进行运行,通过重定位将编译好的程序放到sram中的0地址和2048开始的地方,第一部分程序在SRAM中运行,第二部分代码复制到是SDRAM中进行运行,通过mmu建立虚拟地址和物理地址之间的映射,又通过对虚拟地址的访问实现对LED灯的点亮。
需要进行三段地址的映射:
1)PA:1M ---- VA: 1M //1M
2)PA: 0x56000000-0x560fffff ---- VA: 0xA0000000-0xA00fffff //1M
3)PA: 0x30000000-0x33ffffff ---- VA: 0xB0000000-0xB3ffffff //64M
<1>leds.c
#define GPFCON 0xA0000050
#define GPFDAT 0xA0000054
#define GPF4_reset (3<<(4*2))
#define GPF5_reset (3<<(5*2))
#define GPF6_reset (3<<(6*2)) //reset
#define GPF4_out (1<<(4*2))
#define GPF5_out (1<<(5*2))
#define GPF6_out (1<<(6*2)) //output
static inline void Delay_ms(volatile unsigned long ms) //延时函数
{
for(; ms>0;ms--);
}
int main(void)
{
GPFCON &=~(GPF4_reset | GPF5_reset | GPF6_reset);
GPFDAT |= GPF4_out | GPF5_out | GPF6_out; //设置为输出
while(1)
{
GPFDAT &=~(1<<4);
Delay_ms(30000);
GPFDAT |=(1<<4);
GPFDAT &=~(1<<5);
Delay_ms(30000);
GPFDAT |=(1<<5);
GPFDAT &=~(1<<6);
Delay_ms(30000);
GPFDAT |=(1<<6);
}
return 0;
}
<2>crt.S
.text
.global _start
_start:
ldr sp,=4096
bl disable_watch_dog
bl mem_setup
bl copy_to_sdram
bl create_page
bl init_mmu
ldr sp,=0x34000000
ldr pc,=0xB0004000 @跳转到SDRAM中进行执行
halt_loop:
b halt_loop
<3>init.c
#define WHATCH_DOG (*(volatile unsigned long*)0x53000000)
#define MEM_BASE 0x48000000
void disable_watch_dog(void)
{
WATCH_DOG=0;
}
void mem_setup(void)
{
unsigned long const mem_config_val[]={ 0x22011110,
0x00000700,
0x00000700,
0x00000700,
0x00000700,
0x00000700,
0x00000700,
0x00018005,
0x00018005,
0x008C07A3,
0x000000B1,
0x00000030,
0x00000030
};
int i=0;
volatile unsigned long *p=(volatile unsigned long*)MEM_BASE;
for(;i<13;i++)
{
p[i]=mem_config_val[i]; //setup
}
}
void copy_to_sdram(void)
{
unsigned int *psram=(unsigned int *)2048;
unsigned int *psdram=(unsigned int *)0x30004000;
while(psdram<(unsigned int *)0x34004800) //2048--4095对应着2K的地址空间
{
*psdram=*psram;
psram++;
psdram++;
}
}
void creat_page(void)//设置页表
{
#define MMU_ACCESS (3<<10) //访问权限
#define MMU_DOMAIN (0<<5) //域
#define MMU_SPECIAL (1<<4)
#define MMU_SECTION (2<<0) //section
#define MMU_CACHE (1<<3) //cache
#define MMU_BUFFER (1<<2) //buffer
#define MMU_CB (MMU_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_SECTION | MMU_CACHE | MMU_BUFFER ) //HAVE C&B
#define MMU_NCB (MMU_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_SECTION) //NOT C&B
unsigned int virtuladdr =0; //VA
unsigned int physicaladdr =0;//PA
unsigned int * mmu_ttb=(unsigned int *)0x30000000;//ttb
//1M - 1M
virtuladdr=0;
physicaladdr=0;
*(mmu_ttb + (virtuladdr>>20))=((physicaladdr & 0xfff00000) | MMU_CB);
//0x56000000-0x560fffff to 0xB0000000-0xB00fffff
virtuladdr=0xB0000000;
physicaladdr=0x56000000;
*(mmu_ttb + (virtuladdr>>20))=((physicaladdr & 0xfff00000) | MMU_NCB);
//0x30000000-0x33ffffff to 0xA0000000-A3ffffff
virtuladdr=0xA0000000;
physicaladdr=0x30000000;
while(physicaladdr<0x34000000)
{
*(mmu_ttb + (virtuladdr >> 20)=((physicaladdr & 0xfff00000) | MMU_CB);
virtuladdr +=0x100000;
physicaladdr +=0x100000;
}
}
void mmu_init(void)
{
unsigned long ttb=0x30000000;
__asm__(
"mov r0,#0\\n"
"mcr p15,0,r0,c7,c7,0\\n"
"mcr p15,0,r0,c7,c10,4\\n"
"mcr p15,0,r0,c8,c7,0\\n"
"mov r4,%0\\n"
"mcr,p15,0,r4,c2,c0,0\\n"
"mov r0,#0\\n"
"mcr p15,0,r0,c3,c0,0\\n"
"mrc p15,0,r0,c1,c0,0\\n"
"bic r0,r0, #0x3000\\n"
"bic r0,r0, #0x3000\\n"
"bic r0,r0, #0x0087\\n"
"orr r0,r0,#0x0002\\n"
"orr r0,r0,#0x0004\\n"
"orr r0,r0,#0x1000\\n"
"orr r0,r0,#0x0001\\n"
"mcr p15,0,r0,c1,c0,0\\n"
:
:"r" (ttb)
);
}
<4>mmu.lds
SECTIONS{
first 0x00000000 : {head.o init.o}
second 0xB0004000 : AT(2048) {leds.0}
}
<5>Makefile
objs: =head.o init.o leds.o //变量objs
mmu.bin :$(objs)
arm-linux-ld -Tmmu.lds -o mmu_elf $^
arm-linux-objcopy -o binary -S mmu_elf mmu.bin
arm-linux-objdump -D -m arm mmu_elf mmu.dis
%.o : %.o
arm-linux-gcc -Wall -O2 -c -o $@ $<
%.o ;%.S
arm-linux-gcc -Wall -O2 -c -o $@ $<
clean:
rm -f mmu.bin mmu.dis mmu_elf *.o
经编译后烧录到开发板中,我发现led灯闪烁的比较快,这里虽有部分程序在SDRAM中运行,但是其中使用了cache使得它的速度加快
以上是关于MMU的主要内容,如果未能解决你的问题,请参考以下文章