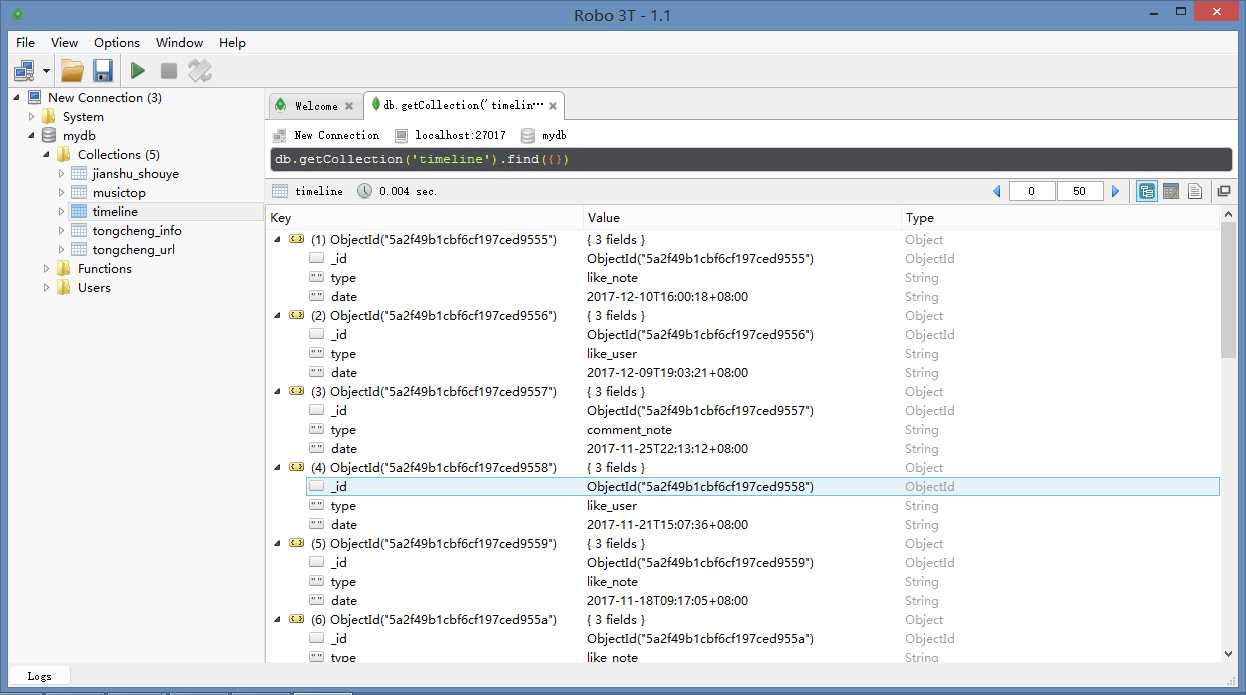
jianshuwanguser.py:
import requests
from lxml import etree
import pymongo
client = pymongo.MongoClient(‘localhost‘, 27017)
mydb = client[‘mydb‘]
timeline = mydb[‘timeline‘]
def get_time_info(url, page):
user_id = url.split(‘/‘)
user_id = user_id[4]
if url.find(‘page=‘):
page = page + 1
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath(‘//ul[@class="note-list"]/li‘)
for info in infos:
dd = info.xpath(‘div/div/div/span/@data-datetime‘)[0]
type = info.xpath(‘div/div/div/span/@data-type‘)[0]
timeline.insert_one({‘date‘: dd, ‘type‘: type})
id_infos = selector.xpath(‘//ul[@class="note-list"]/li/@id‘)
if len(infos) > 1:
feed_id = id_infos[-1]
max_id = feed_id.split(‘-‘)[1]
next_url = ‘http://www.jianshu.com/users/%s/timeline?max_id=%s&page=%s‘ % (user_id, max_id, page)
get_time_info(next_url, page)
if __name__ == ‘__main__‘:
get_time_info(‘http://www.jianshu.com/users/9104ebf5e177/timeline‘, 1)