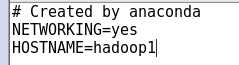
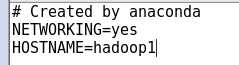
1.1设置机器名:hostname
gedit /etc/sysconfig/network
Scala
http://www.scala-lang.org/
cd /opt
mkdir scala
cp /home/hserver1/desktop/scala-2.12.2.tgz /opt/scala
cd /opt/scala
tar -xvf scala-2.12.2.tgz
配置环境变量
gedit /etc/profile
export SCALA_HOME=/opt/scala/scala-2.12.2
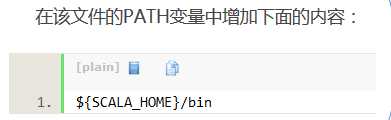
source /etc/profile
验证Scala
scala -version
Spark源码
* 下载http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/


* tar -xvf 
2、编译代码
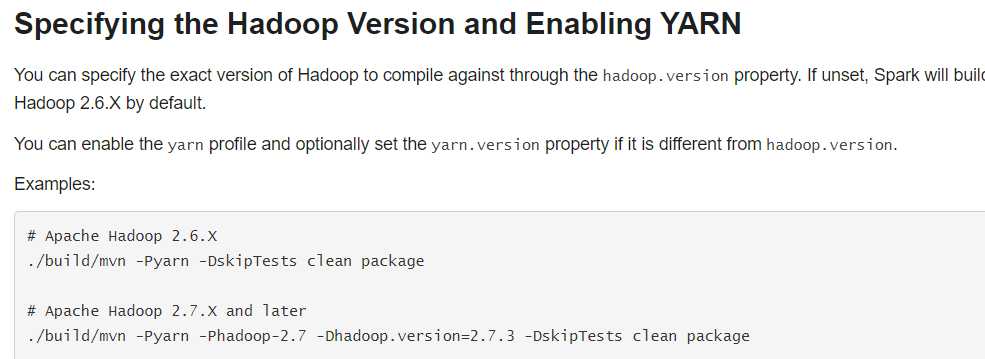
* 进入源码根目录,执行如下编译命令:
1. mvn -Pyarn -Phadoop-2.6 -DskipTests clean package
2. mvn -Pyarn -Dscala-2.10 -DskipTests clean package
3. mvn -Pyarn -Phadoop-2.7 -PHive -Dhadoop.version=2.7.4 -DskipTests clean package 这个时间吧 大概是我从四点开始编译到了六点半竟然还没有编译完。
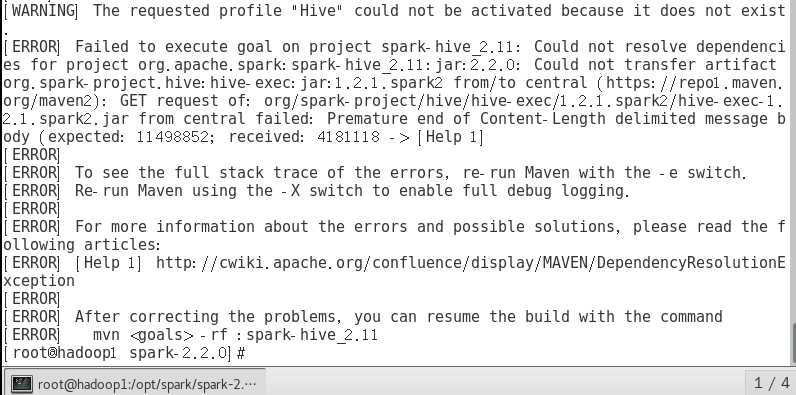
经过修改


mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.4 -PHive -Phive-thriftserver -DskipTests clean package
mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.4 -PHive -Phive-thriftserver -DskipTests clean package
进行了很多次编译,终于通过
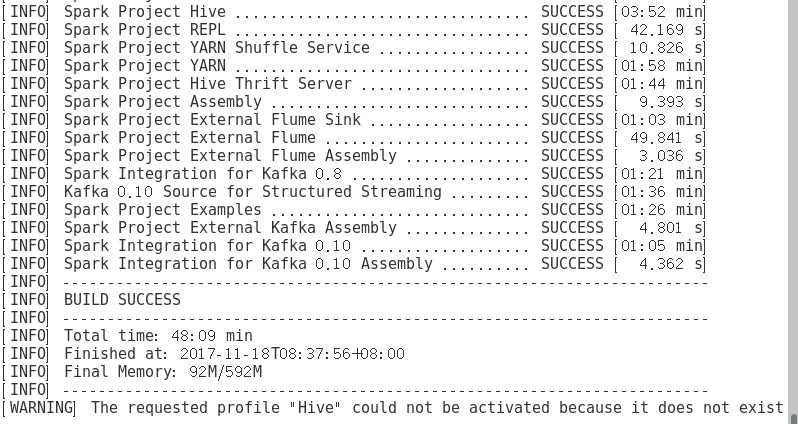

第二次编译也成功了
3、生成部署包
./make-distribution.sh --name hadoop2.7.4 --tgz -Phadoop-2.7 -Phive -Phive-thriftserver -Pyarn
./make-distribution.sh --tgz -Phadoop-2.7 -Pyarn -DskipTests -Dhadoop.version=2.7.4 -Phive
./dev/make-distribution.sh --name hadoop2.7.4 --tgz -Psparkr -Phadoop-2.7 -Phive -Phive-thriftserver -Pmesos -Pyarn
同样耗时略久,如无异常,会在源码包根目录生成安装包
spark-2.2.0-bin-hadoop2.8.2.tgz
4、解压spark安装包至目标目录
1. tar -xvf spark-2.2.0-bin-hadoop2.8.2.tgz -C /opt/spark/5、将spark加入到环境变量
在/etc/profile加入
gedit /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_152
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.4
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.2
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:$PATH
source /etc/profile
6、配置conf
进入conf目录
cp slaves.template slaves
gedit slaves
添加hadoop1
cp spark-env.sh.template spark-env.sh
gedit spark-env.sh
1. export SPARK_MASTER_IP=hadoop1
2. export SPARK_LOCAL_IP=hadoop1
3. export SPARK_MASTER_PORT=7077
4. export SPARK_WORKER_CORES=1
5. export SPARK_WORKER_INSTANCES=1
6. export SPARK_WORKER_MEMORY=512M
7. export LD_LIBRARY_PATH=$JAVA_LIBRARY_PATHcp spark-defaults.conf.template spark-defaults.conf
gedit spark-defaults.conf
1. spark.master spark://master:7077
2. spark.serializer org.apache.spark.serializer.KryoSerializer
3. spark.driver.memory 512m
4. spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" 更改日志级别:
cp log4j.properties.template log4j.properties
gedit log4j.properties
19 log4j.rootCategory=WARNING, console
7、启动hdfs
cd $HADOOP_HOME/sbin
./start-dfs.sh
8、启动spark
cd $SPARK_HOME/sbin
./start-all.sh
浏览器访问http://hadoop1:8080/就可以访问到spark集群的主页
注意:需要将防火墙关闭service iptables stop
验证启动:
jps
验证客户端连接:
spark-shell --master spark://hadoop1:7077 --executor-memory 500m