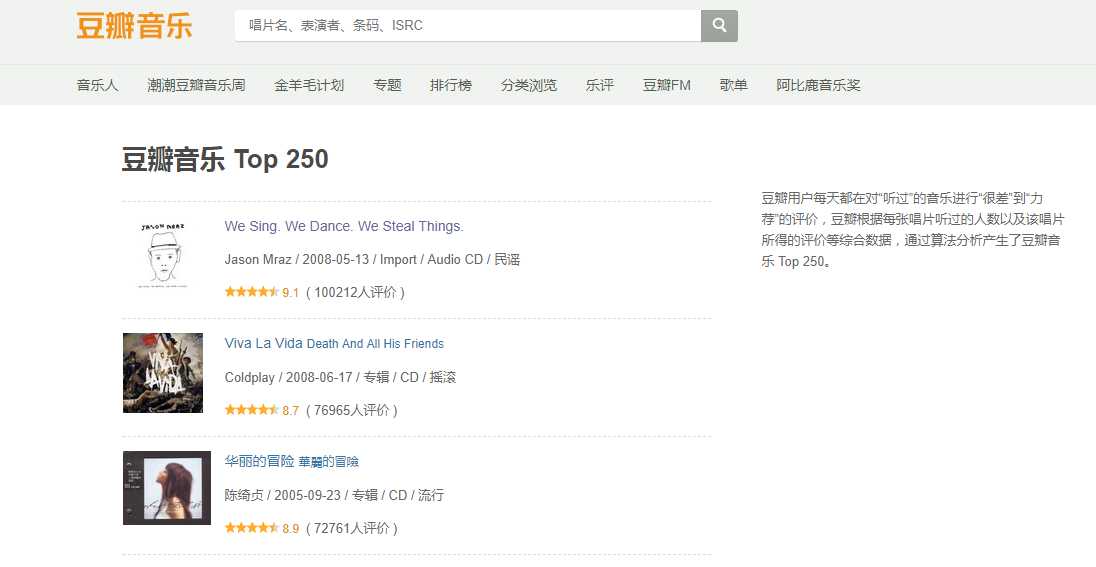
doubanyinyue.py:
import requests
from lxml import etree
import re
import pymongo
import time
client = pymongo.MongoClient(‘localhost‘, 27017)
mydb = client[‘mydb‘]
musictop = mydb[‘musictop‘]
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ‘
‘(Khtml, like Gecko) Chrome/55.0.2883.87 Safari/537.36‘
}
def get_url_music(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
music_hrefs = selector.xpath(‘//a[@class="nbg"]/@href‘)
for music_href in music_hrefs:
get_music_info(music_href)
def get_music_info(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
name = selector.xpath(‘//*[@id="wrapper"]/h1/span/text()‘)[0]
# author = selector.xpath(‘//*[@id="info"]/span[1]/span/a/text()‘)
author = re.findall(‘表演者:.*?>(.*?)</a>‘, html.text, re.S)[0]
styles = re.findall(‘<span class="pl">流派:</span> (.*?)<br />‘, html.text, re.S)
if len(styles) == 0:
style = ‘未知‘
else:
style = styles[0].strip()
time = re.findall(‘发行时间:</span> (.*?)<br />‘, html.text, re.S)[0].strip()
publishers = re.findall(‘出版者:.*?>(.*?)</a>‘, html.text, re.S)
if len(publishers) == 0:
publisher = ‘未知‘
else:
publisher = publishers[0].strip()
score = selector.xpath(‘//*[@id="interest_sectl"]/div/div[2]/strong/text()‘)[0]
print(name, author, style, time, publisher, score)
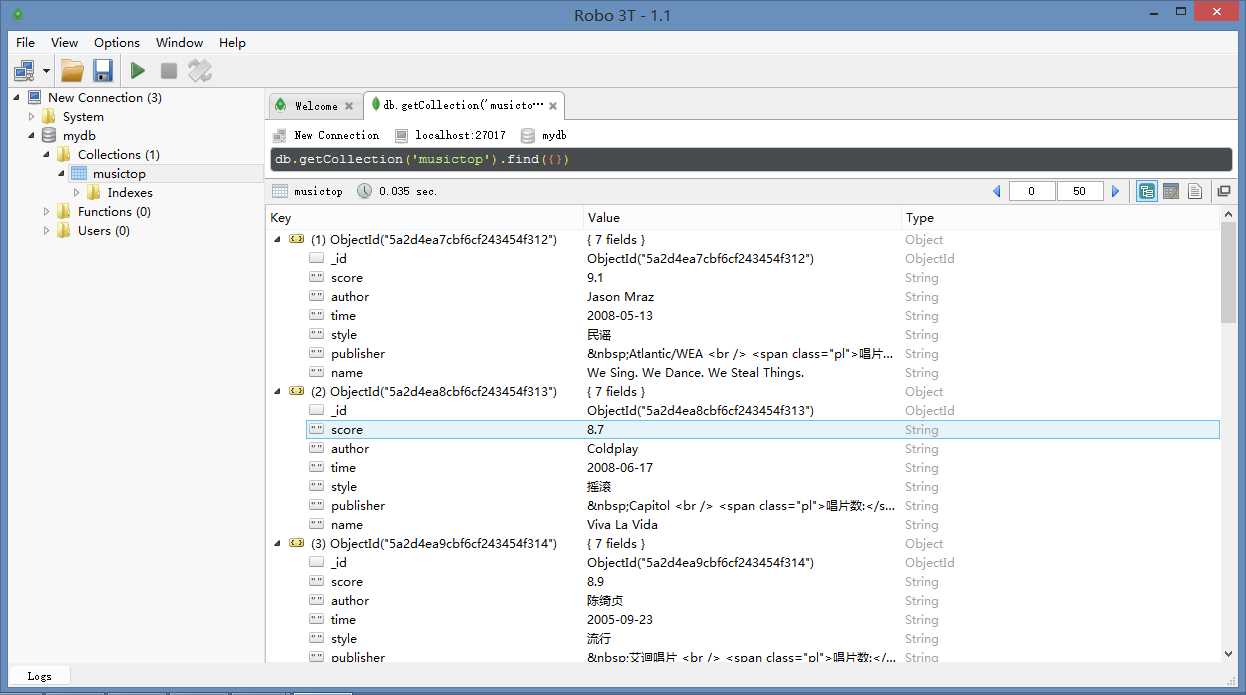
info = {
‘name‘: name,
‘author‘: author,
‘style‘: style,
‘time‘: time,
‘publisher‘: publisher,
‘score‘: score
}
musictop.insert_one(info)
if __name__ == ‘__main__‘:
urls = [‘https://music.douban.com/top250?start={}‘.format(str(i)) for i in range(0, 250, 25)]
for url in urls:
get_url_music(url)
time.sleep(2)