Pandas库的使用--Series
Posted L先生AI课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas库的使用--Series相关的知识,希望对你有一定的参考价值。
一。概念
Series相当于一维数组。
1.调用Series的原生方法创建
import pandas as pd s1 = pd.Series(data=[1,2,4,6,7],index=[\'a\',\'b\',\'c\',\'d\',\'e\'])# index表示索引 print(s1[\'a\']) print(s1[0]) print(s1[:3])# 在Series中切片是一个闭合区间表示Series中0-3的元素print(s1[\'a\':\'d\']) # 范围是一个闭合
print(s1[[\'a\',\'d\']]) #用逗号隔开,表示分别取这两个元素 注意 这里用两个中括号括起来
2.使用字典生成Series
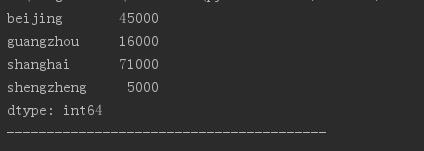
sdata = {\'beijing\':45000, \'shanghai\':71000, \'guangzhou\':16000, \'shengzheng\':5000}
obj3 = Series(sdata)
print(obj3)
print("-"*40)
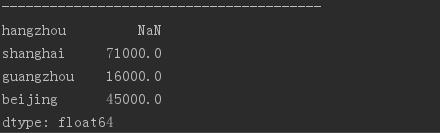
states = [\'hangzhou\', \'shanghai\', \'guangzhou\',\'beijing\'] obj4 = Series(sdata, index = states) # 索引重置 使用字典生成Series,并额外指定index,不匹配部分为NaN。 print(obj4)
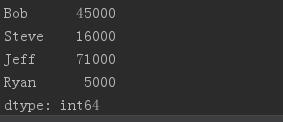
# #替换index 索引替换
obj.index = [\'Bob\', \'Steve\', \'Jeff\', \'Ryan\']
print(obj)
#Series相加,相同索引部分相加。不相同的索引部分为NaN print(obj3 + obj4)
二。Series的相关特性及函数
from pandas import Series #用数组生成Series ,默认情况下使用数字索引 obj = Series([4, 7, -5, 3]) print(obj)
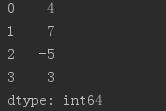
print(obj.values) print(obj.index)
print(obj.shape,obj.ndim) # 这里 shape表示每一个维度的数量, ndim表示的是维度
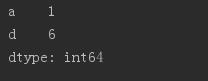
obj2 = Series([4, 7, -5, 3], index = [\'d\', \'b\', \'a\', \'c\']) print(obj2.index) print(obj2[\'a\']) obj2[\'d\']=6 #替换Series中的元素
print(obj2) # print(obj2[:3]) # 数字的下标还存在,也可以分片 # print(obj2[[\'c\', \'a\', \'d\']]) #获取索引a,c,d的值 # print(obj2[obj2 > 0]) # 找出大于0的元素
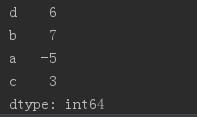
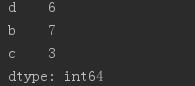
# print(\'b\' in obj2) # 判断索引是否存在 # print(\'e\' in obj2) # print("-"*40)
# # #指定Series及其索引的名字obj4.name = \'我定义的名字\'obj4.index.name = \'index\'print(obj4)
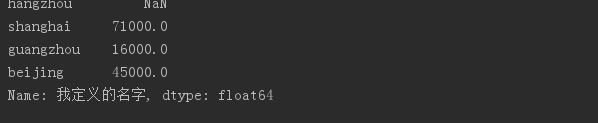
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

以上是关于Pandas库的使用--Series的主要内容,如果未能解决你的问题,请参考以下文章