虚拟机下 solr7.1 cloud 集群搭建 (手动解压和官方脚本两种方式)
Posted 初心丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虚拟机下 solr7.1 cloud 集群搭建 (手动解压和官方脚本两种方式)相关的知识,希望对你有一定的参考价值。
准备工作:
vmware workstation 12,OS使用的是ubuntu16.04,三台虚拟机搭建一个solr集群,zookeeper共用这三台虚拟机组成zookeeper集群。
zookeeper的版本为3.4.10,solr版本为7.1,不使用tomcat,使用solr自带的jetty。jdk版本为1.8.0_151。
第一步:虚拟机的建立
选择默认配置即可,内存我配置的2G一台,1CPU,网络采用NAT,DHCP自动分配。建好一台虚拟机后,我们可以去配置一些基本环境,如Jdk等,然后使用克隆的方式,减少一些不必要的操作。
基本配置也就是安装openssh-server,jdk等常用环境即可。
安装完成的结果如下。

图1 安装完成后xshell下远程连接的界面
第二步:zookeeper集群环境搭建
下载zookeeper3.4.10,我把zookeeper解压到了登录用户(我的用户是solr)的根目录下(我的是/home/solr/zookeeper-3.4.10),实际可根据需求自行放置在相应的目录下即可。
随后我们进入zookeeper下conf目录,复制一份cfg文件,并进行配置。
cd /zookeeper-3.4.10/conf # 进入zookeeper config目录 cp zoo_sample.cfg zoo.cfg # 复制一份配置文件,并修改内容
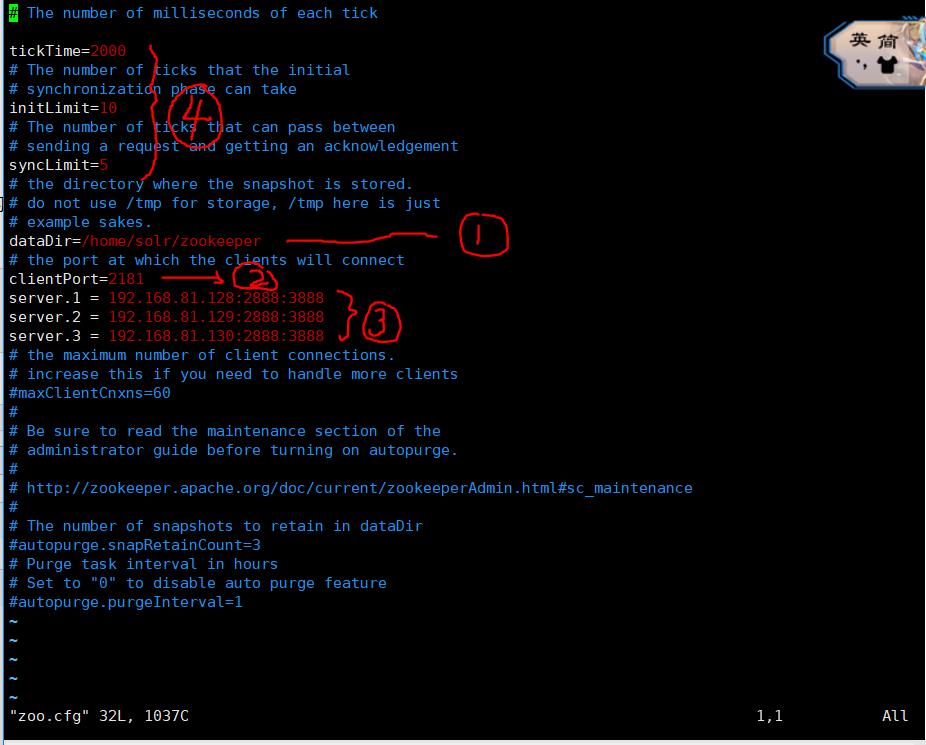 图2 zoo.cfg配置文件
图2 zoo.cfg配置文件
对上述1.2.3.4进行说明:
- zookeeper的数据存放的地方(我的理解),我这里为了方便配置在Home目录下,实际可根据需求进行配置
- zookeeper的端口
- zookeeper集群的设置,2888和3888分别是监听和投票选举端口,server.1 server.2 server.3后续进行说明
- 是一些配置参数,比如触发事件什么,请自行百度了解相关意思。
server.1 server.2 server.3 说明的是集群中其他zookeeper的"代号",server.后的数字的范围为1~255
这个数字在刚才配置文件目录(如上述的/home/solr/zookeeper)下新建一个myid文件,里面填写这些数字来标识身份即可,比如server.1所在的服务器的zookeeper目录下就应该有一个myid文件,内容为1。
./zkServer.sh start # 启动zookeeper
启动zookeeper查看状态可以看到如下内容,说明zookeeper集群搭建成功。

图3 zookeeper follwer 状态

图4 zookeeper leader 状态
第三步 solr集群的搭建(按照官方按照脚本来进行配置)
在这里,我们先用官方的文档中的脚本来进行安装,将solr安装为系统中的一个服务。
tar xzf solr-7.1.0.tgz solr-7.1.0/bin/install_solr_service.sh --strip-components=2 # 将脚本文件从包中解压出来 sudo bash ./install_solr_service.sh solr-7.1.0.tgz # 进行安装solr
在这种情况下,solr会默认安装在/opt/solr-7.1.0/下,同时会自动建立一个/opt/solr 去链接/opt/solr-7.1.0,这是为了方便后续更新solr版本是,只要更换/opt/solr-7.1.0文件即可。
同时,默认情况下,会将一些配置文件放置在/var/solr中,后续我们会用到该文件夹。
同时,如果不存在用户solr,会自动新建一个solr用户,最后,该脚本会自动启动solr。
上述的命令采用的是默认安装的情况,实际条件我们可以进行一些自己的配置。
- -d solr的一些参数和可写的文件存放的位置,默认为/var/solr
- -i solr的解压位置,默认为/opt/下
- -p solr绑定的端口,默认为8983
- -s service的名称
- -u 对应的用户的名称,默认为solr
- -n 这个参数说明执行完成后不启动solr
在执行完脚本后,我们就可以用 sudo service solr [start|restart|stop|status] 等命令来控制solr。
但是在上述情况下,我们并没有配置solr和zookeeper之间的关系,所以启动后不会是cloud模式,随后,我们来配置solr。
首先,进入/var/solr/data 目录,修改solr.xml文件。

图5 solr.xml 配置文件
在这里,我们主要配置host这个参数,将host:后面填入虚拟机对应的IP,否则搭建集群的时候,cloud会显示localhost,会引发错误。
随后,安装脚本在默认情况下,会在/etc/default/下生成一个solr.in.sh文件,我们要修改这个文件,配置zk_Host参数(也就是zookeeper的参数)。
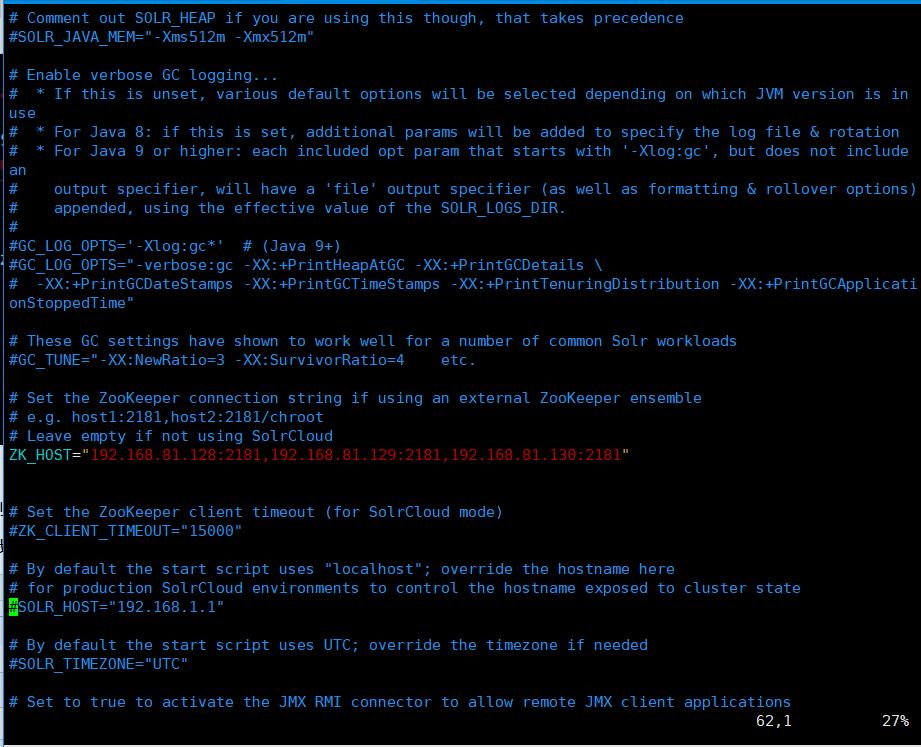
图6 solr.in.sh 配置文件
这个配置文件还有其他很多的参数,读者可以自行去查看是如何意思,我在这里只配置了zk_host,其他都采用默认设置
zk_host 说明了zookeeper集群的位置,可以看出来,这就是我们第一步配置的zookeeper的集群中所以节点的地址。
配置完成后,我们就可以启动solr。
第四步,基础操作
首先我们应该用zookeeper上传一份我们自己的配置文件,放置在我们的zookeeper集群中。
root@ubuntu:/opt/solr-7.1.0/bin# ./solr zk upconfig -d [要上传的配置文件目录] -n [zookeeper上保存的配置文件名称] -z [zookeeper的集群地址]
很多教程中用的是cloud_scripts/下的zkcli.sh。实际上都是一样的,看自己的喜好,这个文件在zookeeper下也有,可以用help来看看参数说明。
上传之后,我们在新建一个集合,用我们刚才上传的配置文件,如果不指定,就会使用默认的配置文件
root@ubuntu:/opt/solr-7.1.0/bin# ./solr create-collection -c [新建集合的名字] -n [zookeeper上配置文件的名称,上一步设置的那个n] -shards 2 [分两块] -replicationFactor 2 [replic数量]
我们进入solr-cloud,就可以看到我们新建的集合,也可以看到我们solr-cloud集群已经搭载成功。

图7 solr-cloud
第五步 直接解压solr的配置说明
其他配置和官方脚本安装都一样,核心问题就是配置文件的位置不一样,需要特别说明。
solr.xml在解压后根目录下server/solr 下
solr.in.sh 在根目录下的bin/下
启动命令要使用 -cloud -z 参数,具体请参考官方文档。
以上是关于虚拟机下 solr7.1 cloud 集群搭建 (手动解压和官方脚本两种方式)的主要内容,如果未能解决你的问题,请参考以下文章
大数据之一:Hadoop2.6.5+centos7.5三节点大数据集群部署搭建
在VWwear下,用文件中的挂载光盘在linux虚拟机下搭建本地仓库
VMWare虚拟机下为Ubuntu 12.04.1配置静态IP_转