爬虫实践-爬取酷狗TOP500数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫实践-爬取酷狗TOP500数据相关的知识,希望对你有一定的参考价值。
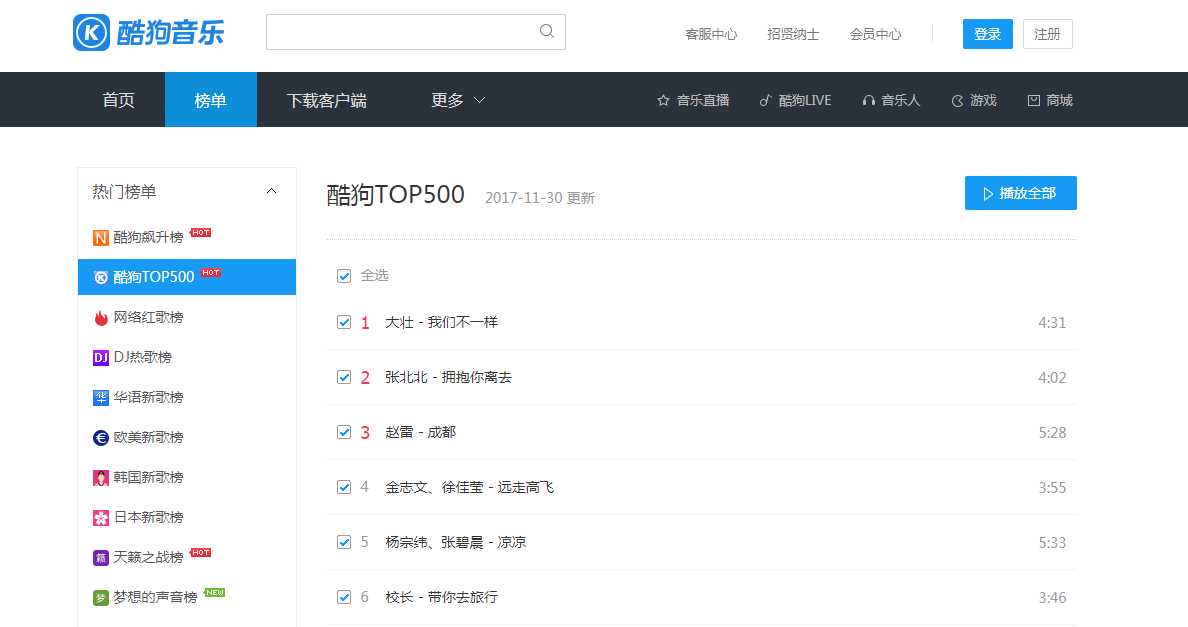
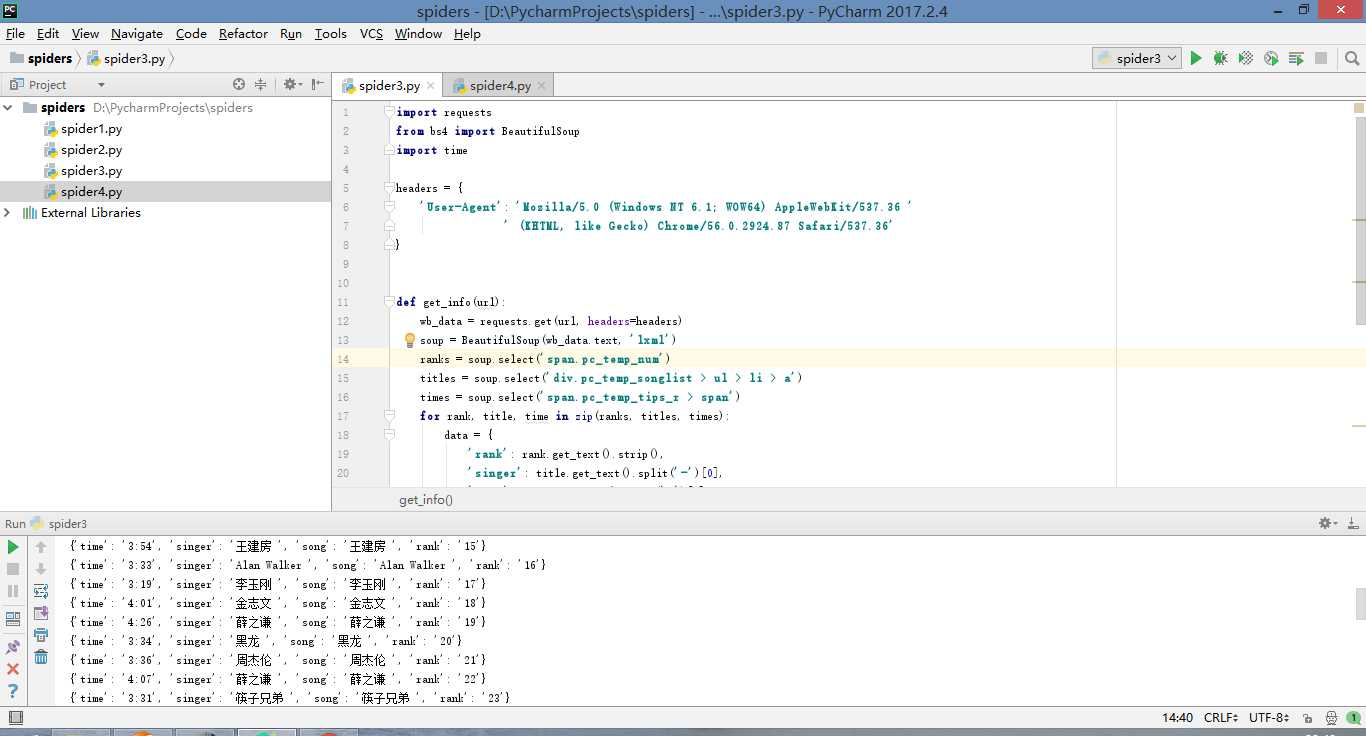
源代码:
import requests
from bs4 import BeautifulSoup
import time
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ‘
‘ (Khtml, like Gecko) Chrome/56.0.2924.87 Safari/537.36‘
}
def get_info(url):
wb_data = requests.get(url, headers=headers)
soup = BeautifulSoup(wb_data.text, ‘lxml‘)
ranks = soup.select(‘span.pc_temp_num‘)
titles = soup.select(‘div.pc_temp_songlist > ul > li > a‘)
times = soup.select(‘span.pc_temp_tips_r > span‘)
for rank, title, time in zip(ranks, titles, times):
data = {
‘rank‘: rank.get_text().strip(),
‘singer‘: title.get_text().split(‘-‘)[0],
‘song‘: title.get_text().split(‘-‘)[0],
‘time‘: time.get_text().strip()
}
print(data)
if __name__ == ‘__main__‘:
urls = [‘http://www.kugou.com/yy/rank/home/{}-8888.html‘.format(str(i)) for i in range(1, 24)]
for url in urls:
get_info(url)
time.sleep(1)
以上是关于爬虫实践-爬取酷狗TOP500数据的主要内容,如果未能解决你的问题,请参考以下文章