Tensorflow 函数学习笔记
Posted love小酒窝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow 函数学习笔记相关的知识,希望对你有一定的参考价值。
A:
A:## tf.argmax(A, axis).eval() 输出axis维度上最大的数的索引 axis=0:列,axis=1:行
A:## tf.add(a,b) 创建a+b的计算图
A:## tf.assign(a, b) 创建a=b的计算图
state = tf.Variable(0)
new_value = tf.add(state, tf.constant(1))
update = tf.assign(state, new_value)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(state))
for _ in range(3):
sess.run(update)
print(sess.run(state))
>>0 1 2 3
B:
B:## tf.boolean_mask(a,b)
tensorflow 里的一个函数,在做目标检测(YOLO)时常常用到。
其中b一般是bool型的n维向量,若a.shape=[3,3,3] b.shape=[3,3]
则 tf.boolean_mask(a,b) 将使a (m维)矩阵仅保留与b中“True”元素同下标的部分,并将结果展开到m-1维。
例:应用在YOLO算法中返回所有检测到的各类目标(车辆、行人、交通标志等)的位置信息(bx,by,bh,bw)
a = np.random.randn(3, 3,3)
b = np.max(a,-1)
c= b >0.5
print("a="+str(a))
print("b="+str(b))
print("c="+str(c))
with tf.Session() as sess:
d=tf.boolean_mask(a,c)
print("d="+str(d.eval(session=sess)))
>> a=[[[-1.25508127 1.76972539 0.21302597] [-0.2757053 -0.28133549 -0.50394556] [-0.70784415 0.52658374 -3.04217963]] [[ 0.63942957 -0.76669861 -0.2002611 ] [-0.38026374 0.42007134 -1.08306957] [ 0.30786828 1.80906798 -0.44145949]] [[ 0.22965498 -0.23677034 0.24160667] [ 0.3967085 1.70004822 -0.19343556] [ 0.18405488 -0.95646895 -0.5863234 ]]] b=[[ 1.76972539 -0.2757053 0.52658374] [ 0.63942957 0.42007134 1.80906798] [ 0.24160667 1.70004822 0.18405488]] c=[[ True False True] [ True False True] [False True False]] d=[[-1.25508127 1.76972539 0.21302597] [-0.70784415 0.52658374 -3.04217963] [ 0.63942957 -0.76669861 -0.2002611 ] [ 0.30786828 1.80906798 -0.44145949] [ 0.3967085 1.70004822 -0.19343556]]
C:
C:## tf.cast(x, dtype, name=None) 将x转换为dtype类型
C:## tf.convert_to_tensor(a) 转化为tensorflow张量
C:## tf.constant(? ?) 创建常量
# Constant 1-D Tensor populated with value list. tensor = tf.constant([1, 2, 3, 4, 5, 6, 7]) => [1 2 3 4 5 6 7]
# Constant 2-D tensor populated with scalar value -1. tensor = tf.constant(-1.0, shape=[2, 3]) => [[-1. -1. -1.][-1. -1. -1.]]
D:
E:
E:## tf.equal(A,B) 判断A,B是否相等 输出 true and false
F:
G:
G:## tf.global_variables_initializer() 全局变量初始函数
H:
I:
J:
K:
L:
L:## tf.linspace (10.0, 12.0, 3, name="linspace") 创建等差数列
tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0]
M:
M:## tf.matmul(w,x) 矩阵乘法
w = tf.Variable([[0.5,1.0]])
x = tf.Variable([[2.0],[1.0]])
y = tf.matmul(w, x)
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print (y.eval()) #tf中显示变量值需加.eval
>> [[ 2.]]
N:
N:## tf.nn.softmax (A) 求A的softmax值
N:## tf.nn.sigmoid(A) 计算sigmoid
N:## tf.nn.relu(A) 计算relu
N:## tf.nn.softmax_cross_entropy_with_logits(pred, y) 交叉熵函数
仅求得y*log(a),未经过求和操作。要求得求和的交叉熵,还要使用tf.reduce_sum
O:
O:## tf.ones(shape,dtype) 创建全1阵
tf.ones([2, 3], int32) ==> [[1, 1, 1], [1, 1, 1]]
O:## tf.ones_like(tensor) 创建tensor同维的全1阵
# \'tensor\' is [[1, 2, 3], [4, 5, 6]] tf.ones_like(tensor) ==> [[1, 1, 1], [1, 1, 1]]
P:
P:## tf.placeholder(dtype, shape=None, name=None) 创建占位符
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print(sess.run([output], feed_dict={input1:[7.], input2:[2.]})) #需要以字典方式赋值
》[[ 0. 0. 0.] [ 0. 0. 0.] [ 0. 0. 0.]]
P:## tf.pad()
for example:
t=[[2,3,4],[5,6,7]],paddings=[[1,1],[2,2]],mode="CONSTANT"
那么sess.run(tf.pad(t,paddings,"CONSTANT"))的输出结果为:
array([[0, 0, 0, 0, 0, 0, 0],
[0, 0, 2, 3, 4, 0, 0],
[0, 0, 5, 6, 7, 0, 0],
[0, 0, 0, 0, 0, 0, 0]], dtype=int32)
可以看到,上,下,左,右分别填充了1,1,2,2行刚好和paddings=[[1,1],[2,2]]相等,零填充
Q:
R:
R:## tf.range(start, limit, delta) 创建等差数列start->limit 步长delta
tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15]
R:## tf.random_uniform(shape[], -1.0, 1.0) 创建[-1,1]内的随机数矩阵
R:## tf.random_normal(shape, mean=-1, stddev=4) 创建随机数矩阵 服从mean=-1,stddev=4的高斯分布
R:## tf.random_shuffle(c) 洗牌,打乱矩阵c
norm = tf.random_normal([2, 3], mean=-1, stddev=4)
# Shuffle the first dimension of a tensor
c = tf.constant([[1, 2], [3, 4], [5, 6]])
shuff = tf.random_shuffle(c)
# Each time we run these ops, different results are generated
sess = tf.Session()
print (sess.run(norm))
print (sess.run(shuff))
>>[[-0.30886292 3.11809683 3.29861784]
[-7.09597015 -1.89811802 1.75282788]]
[[3 4]
[5 6]
[1 2]]
R:## tf.reduce_mean(input_tensor, reduction_indices=None, keep_dims=False, name=None) 求平均值
R:## tf.reduce_max(input_tensor, reduction_indices=None, keep_dims=False, name=None) 求最大值
R:## tf.reduce_sum(input_tensor, reduction_indices=None, keep_dims=False, name=None) 求和
参数1--input_tensor:待求值的tensor。
参数2--reduction_indices:在哪一维上求解。
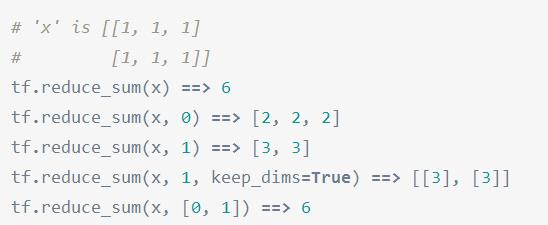
R:## tf.rank(A).eval() 输出矩阵维度
S:
S:## tf.square(a) 求a的平方
S:## tf.shape(A).eval() 输出矩阵各维度元素个数
S:## tf.slice()
1,函数原型 tf.slice(inputs,begin,size,name=\'\')
2,用途:从inputs中抽取部分内容
inputs:可以是list,array,tensor
begin:n维列表,begin[i] 表示从inputs中第i维抽取数据时,相对0的起始偏移量,也就是从第i维的begin[i]开始抽取数据
size:n维列表,size[i]表示要抽取的第i维元素的数目
有几个关系式如下:
(1) i in [0,n]
(2)tf.shape(inputs)[0]=len(begin)=len(size)
(3)begin[i]>=0 抽取第i维元素的起始位置要大于等于0
(4)begin[i]+size[i]<=tf.shape(inputs)[i]
例子详见:http://blog.csdn.net/chenxieyy/article/details/53031943
T:
T:## tf.train.SummaryWriter("./tmp", sess.graph) 生成tensorflow 可视化图表并保存到路径
T:## tf.train.GradientDescentOptimizer(learining_rate).minimize(loss) 梯度下降优化器
learning_rate = 学习率
loss = 系统成本函数
T:## tf.train.Saver() 保存训练模型
#tf.train.Saver
w = tf.Variable([[0.5,1.0]])
x = tf.Variable([[2.0],[1.0]])
y = tf.matmul(w, x)
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
# Do some work with the model.
# Save the variables to disk.
save_path = saver.save(sess, "C://tensorflow//model//test")
print ("Model saved in file: ", save_path)
>>Model saved in file: C://tensorflow//model//test
U:
V:
V:## tf.Variable(??) 创建tf变量
W:
X:
Y:
Z:
Z:## tf.zeros(shape, dtype) 创建全零阵
tf.zeros([3, 4], int32) ==> [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
Z:## tf.zeros_like(tensor) 创建矩阵tensor同维的全零阵
# \'tensor\' is [[1, 2, 3], [4, 5, 6]] tf.zeros_like(tensor) ==> [[0, 0, 0], [0, 0, 0]]
以上是关于Tensorflow 函数学习笔记的主要内容,如果未能解决你的问题,请参考以下文章