二叉树及其实现(基础版)
Posted 仪式黑刃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉树及其实现(基础版)相关的知识,希望对你有一定的参考价值。
前言:常见的数据结构都有指针和数组两种实现方式,这篇先介绍指针实现,而数组实现在后续文章里会讲到。
(长文预警!)
说完了一般的树,我们再来看看二叉树,这是一种很典型的树,它的所有节点度数都不超过2,最多只有两个孩子。这是一种特例,但是后面我们会看到在保证有序性和有根性之后,它却足以描述所有的树。每个节点的出度最多为2,在之前对所有节点按照深度划分的等价类,从规模上看就构成了一个公比为2的等比数列,相应地,深度为k(第k层)的节点,最多有2k个。那么对于含n个节点、高度为h的二叉树中(这里再多说一句,高度指的是:除了根节点,下面有几层高度就是几,回想一下,空树高度是-1,一个根节点高度为0。),满足这样一个条件:
h<n<2^h+1。
这个性质很好证明。对于上界的情况,树的每一层都是满的,所以从根到第n层累加,总数=1+2+4+…+2n=2n+1 - 1,也就是右半部分。而下界情况,根据定义每层至少有一个节点,所以一共h+1个,这种情况下,树就退化为一条单链。
具体来说一下上界的情况,在这个时候节点个数n=2h-1,是一颗满树,那每一层(每一个等价类)都会到达饱和状态。它的横向上的宽度与在纵向上的高度是呈指数关系的——h=log(W),高度会增长的很慢。
相关实现
讨论了二叉树的基本信息后,就该进入正题了,Talk is cheap,show me the code。现在来谈谈怎么在计算机中实现一棵二叉树。谈一个东西的实现不能脱离实际背景,不然就成了空中楼阁,二叉树也有很多种,比如最大堆,最小堆,优先队列,搜索树,这里给出一个其中一个二叉树的具体例子。首先需要知道的是,二叉树的一个重要应用是他们在查找(搜索)中的使用,那为什么查找往往要依靠树形结构呢?这是很自然的一个问题,前面的文章中我们说过,树结构对静态和动态操作的支持都是十分迅速的,因此是这种高效性使得树结构成为了搜索的“天选之人”。这也告诉我们,如果自身很强,那么遇到机会时才有可能把握住,机会是留给有准备的人(突然鸡汤2333)。
假设树中的每个节点内部存了一个值,任何复杂的值都可以,不过这里为了简单起见,让它们都是int型,同时假设他们是互异的,以后我们再处理有重复值的情形。我们要进行一些操作的前提是:知道规则,有了规则,操作的步骤就一目了然了,这是老师在课上反复强调的。那搜索树的规则就是——对于每个节点X(作为根),左子树中存的所有值都小于X存的值;右子树的所有值都大于X的值。也就是从小到大依次是左-根-右,就像这样:
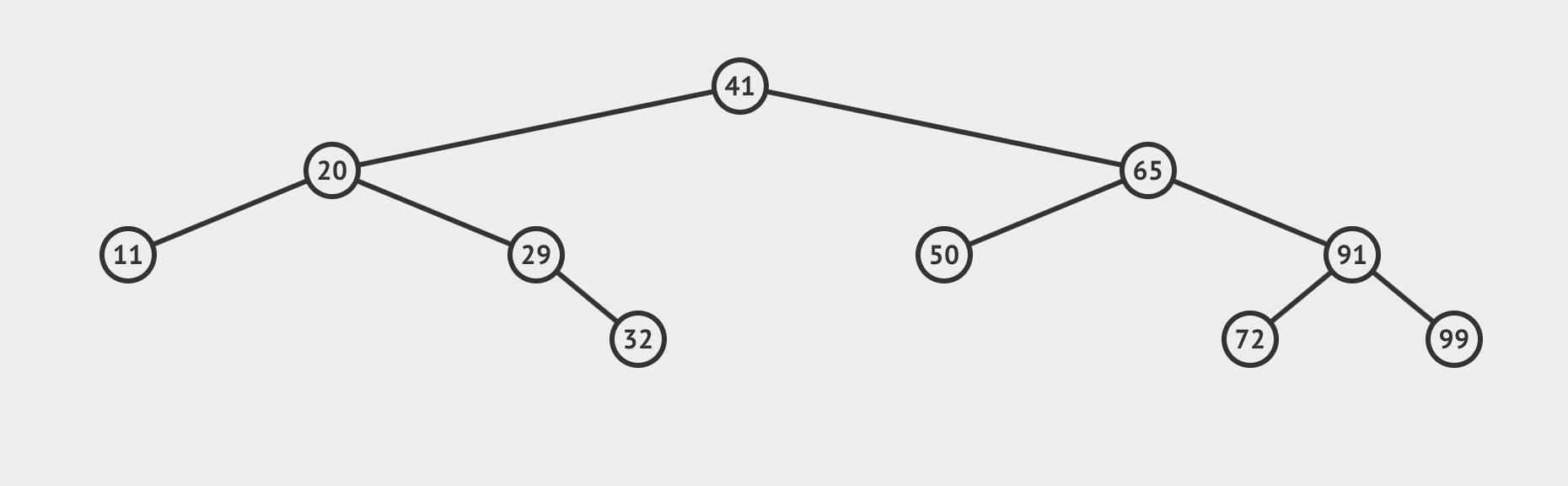
这个性质要引起注意,这意味着树中的所有元素可以用统一的方式排序。为什么要这样说?因为树是递归构造的,其中每一棵子树中都满足这个性质,那我们的排序过程就可以逐步分解到最小的子树中,每个被分解的部分和原来的总体都是“性质相同的子问题”这样一种关系,所以可以用统一的方法,从最小的子问题推而广之,直至解决整个问题。
现在具体说说怎么实现他们,由于树是递归定义的,所以通常递归地编写操作函数,前面说了,二叉树的平均深度是多少来着?忘的话往上翻翻。由于平均深度增长地很慢,所以我们不必担心栈空间被用尽(emmm这怎么突然提到栈了,忘了的话去前面讲栈的文章里翻翻)。先给出一般性的结点声明
1 struct BinNode;
2 typedef struct BinNode *Position; //只需要拿到某个单结点时用它表示
3 typedef struct BinNode *SearchTree; //对整棵树操作时,用它表示返回类型
4
5 struct BinNode{
6 int Value;
7 SearchTree Left,Right;
8 };
这里又遇到和链表那里一样,用两个typedef替换同一个类型的情况了,稍后我们会看到如此逻辑分层的优势,它便于我们在大脑中构建一个清晰的搜索树ADT模型。现在只要知道他们表示的都是一个指向二叉树节点的指针就好了,只是所指示的侧重有细微的不同。按照惯例,先说初始化的操作,然后说查找元素,最后就是重头戏——插入和删除了。每种结构都按这个顺序来讲解看似单调乏味,但这的确是我们从0搭建一个结构的必由之路,从简到繁,自下而上这也符合人类的认知规律。
1 SearchTree MakeEmpty(SearchTree T){
2 if (T){
3 MakeEmpty(T->Left);
4 MakeEmpty(T->Right);
5 free(T);
6 }
7 return NULL;
8 }
给这个函数输入一个节点作为根,然后在它不为空的情况下,逐层递归地销毁它以下的所有子树。注意到了吧,这里用的是“SearchTree”来标识,因为置空后要返回的是一个根节点,实际上从整体理解,是以返回值为根的一整棵树(当然这里是空树)。
再说查找,它要返回的是一个指针,指向我们所查的值所在的结点(既然只返回一个单一结点指针,自然用Position做返回类型更清晰),没有的话就NULL。树的结构使得这种操作很简单,我们先分析一下大体策略:如果T是NULL,也就是走到某一个叶子结点仍然没有找到,那就返回NULL;如果T中存的值是要查找的X,那么返回T的地址;如果既没找到,但也没走到末尾(叶结点)时,就按照X和根节点的大小关系来逐层递归左或右子树:如果比根小,左边,否则右边,这就很类似二分查找的思想。
1 Position Find(int X,SearchTree T){
2 if(T == NULL) return NULL; //如果走到叶子还没找到,返回空
3 if (X < T->Value) return Find(X, T->Left); //如果给定值比根小,往左边找
4 else if(X > T->Value) return Find(X , T->Right);//比根大就往右找
5 else return T; //这种情况就是某时X==T->Value,正好命中的情况
6 }
接着来说两种Find的具体情况,分别是找最小最大值,这种递归写法是很自然的,以至于深受喜爱,不过递归调用过多的话会占用大量资源,这是一个弊端,所以迭代和递归两种方法都要熟稔于心。因此,我们用两种方法编写,FindMin(递归)和FindMax(迭代)。
1 Position FindMin(SearchTree T){
2 if(T == NULL) return NULL; //同上
3 else if (T->Left==NULL) return T; //左子树空,意味着没有比它更小的值了,直接返回地址
4 else return FindMin(T->Left); //如果上面两个情况都不符合,接着往左找
5 }
1 Position FindMax(SearchTree T) {
2 if (T!=NULL) //没有走到叶结点时寻找
3 while (T->Right!=NULL) //右边还有子树时一直往右走
4 T=T->Right;
5 return T; //这个return包含了两种情形,如果传入的是叶子,自动返回NULL,如果找到最右边了,返回对应地址
6 }
同理,查找最小值的如果用迭代来写,就是完全对称的。
1 SearchTree FindMinByLoop(SearchTree T) {
2 if(T)
3 while (T->Left)
4 T=T->Left;
5 return T;
6 }
这里要注意时如何处理空树这种退化情形的,一定要小心。
接着就是两大重头戏——插入和删除,我们慢慢讨论,对于插入一个数X来讲,从概念上很好理解:先用find查一下,看是不是已经存在,有的话就不用做什么了(或者做一些修改)。如果没有,就把X插到遍历路径的末尾。
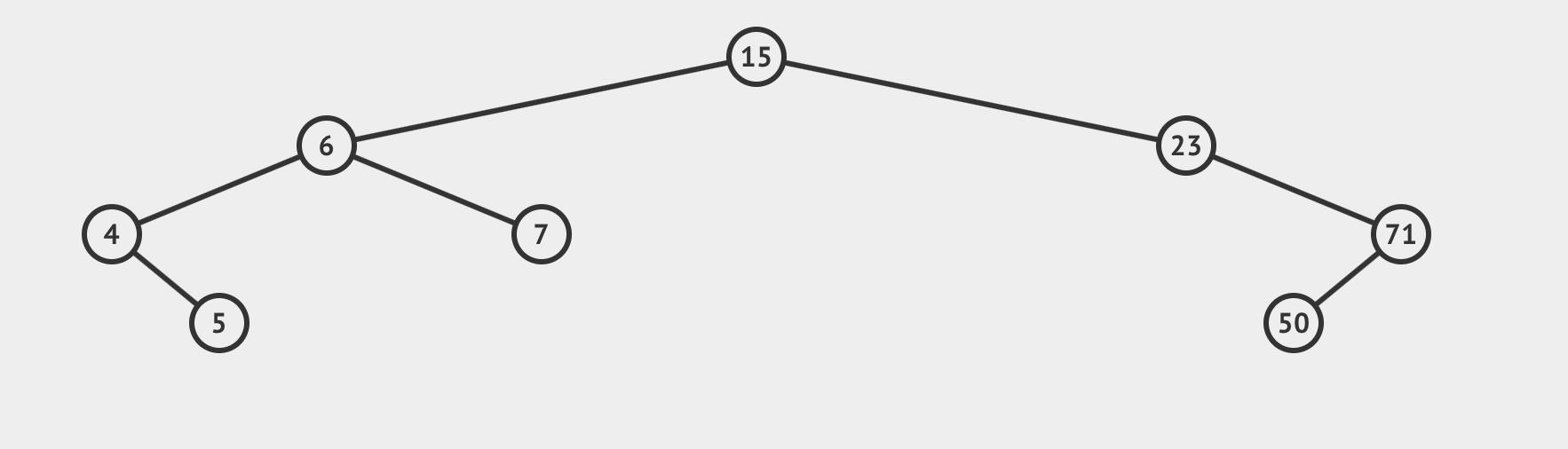
比如对于这样一棵树

我们要插入66这个数,那么就应该按下面这个路径放置。

1 SearchTree Insert(SearchTree T,int X) {
2 if(!T){ //这是应对初始情况,空树
3 T=(SearchTree)malloc(sizeof(struct BinNode));
4 T->Value=X;
5 T->Left=T->Right=NULL; //底部封口
6 }
7 //在一棵现成的树里插入,二分查找
8 else if (X < T->Value) T->Left=Insert(T->Left, X);
9 else if (X > T->Value) T->Right=Insert(T->Right, X);
10 //X==T->Value的情况什么也不用做
11 return T;
12 }
而正如许多数据结构一样,最困难的是删除,因为这会涉及到好多种情况,我们都需要将其考虑在内。
- 节点是一片叶子
- 节点有一个儿子
- 节点有两个儿子
分类讨论,1.叶子的话就直接删除。
2.只有一个儿子的话,就可以在它的父节点调整指针时绕过该节点后被删除。
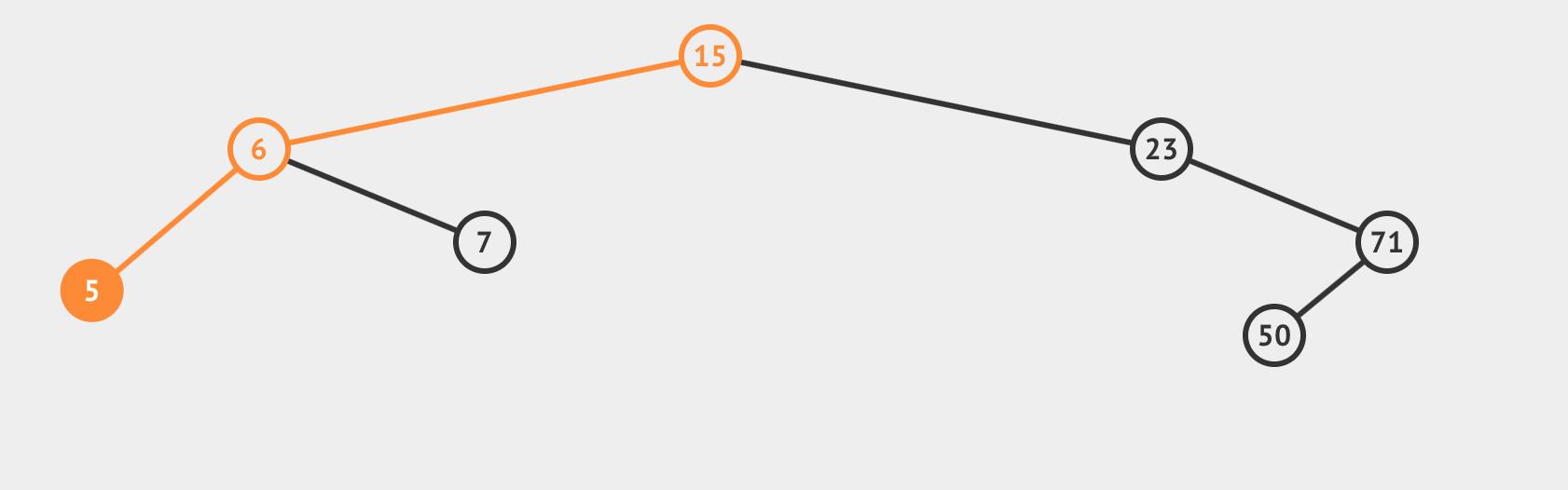
这棵树中,删除4

从父节点直接绕过去,bypass
而有两个儿子的话情况就复杂了,一般来说是用它右子树下最小的数据来代替该节点数据并递归删除。因为右子树下面最小的节点不可能有左儿子,所以第二次delete就更容易了。
//好像插入不了视频……所以请点击这里查看删除演示。如果你们知道怎么弄,请在评论里告诉我以上是关于二叉树及其实现(基础版)的主要内容,如果未能解决你的问题,请参考以下文章