作为全民购物网站的淘宝是在学习爬虫过程中不可避免要打交道的一个网站,而是淘宝上的数据真的很多,只要我们指定关键字,将会出现成千上万条数据。
今天我们来讲一下如何从淘宝上获取某一类宝贝的信息,比如今天我们以“手机”作为关键词,举个例子。
分析页面的源代码
【插入图片,淘宝手机页面示意】
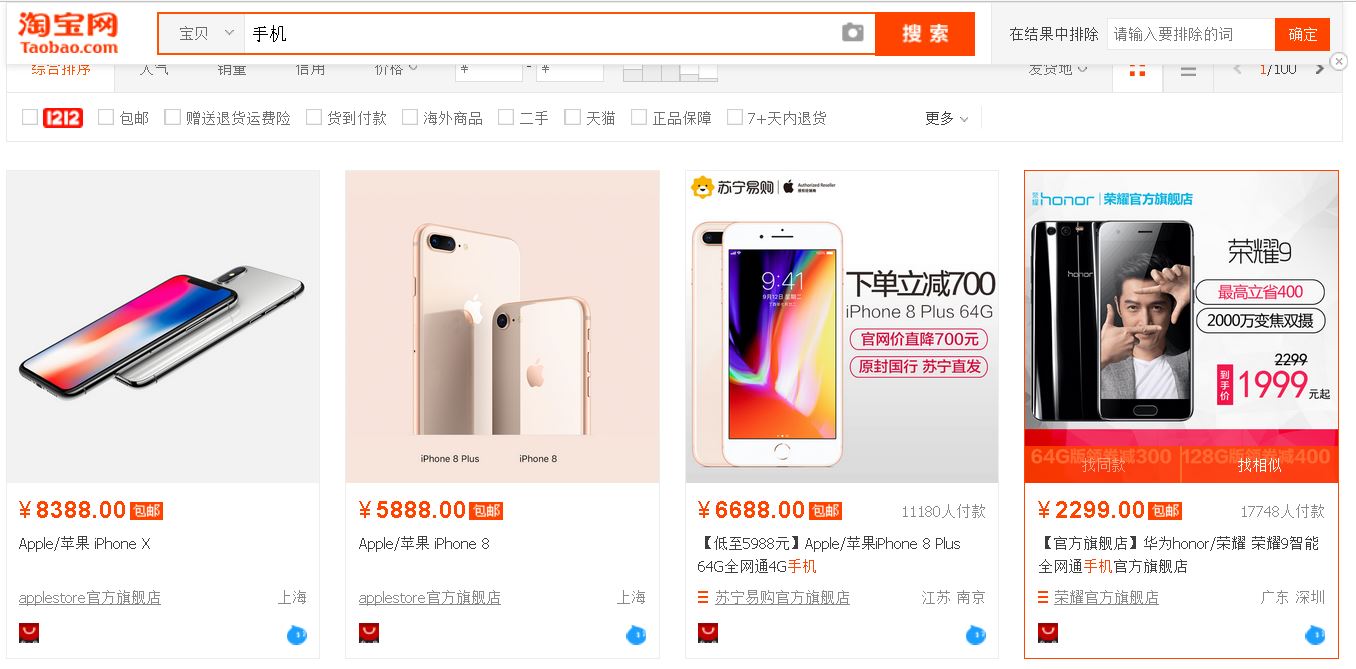
上面是搜索框,下面显示了很多宝贝信息,最下面是翻页的控制按钮。
【插入图片,淘宝手机页面源代码】

我们看一下这个页面的源代码,发现都是一些js,还提示了要运行脚本才能显示。
难道宝贝也是Ajax加载的?我们来找一下有没有数据信息。
【插入图片,XHR中什么都没有】
可惜XHR打开之后,发现并没有加载任何数据。
遇到这种情况,我们可以选择通过Selenium模仿浏览器访问,这样能够加载到所有的内容,虽然比直接访问数据慢一些,但基本上什么网页都能爬到。
我们先分析一下流程。
第一步,如何输入关键字?
一上来,我们要打开淘宝的首页,在搜索框中输入关键字,然后点击搜索按钮。
【插入图片,主页内容解析】
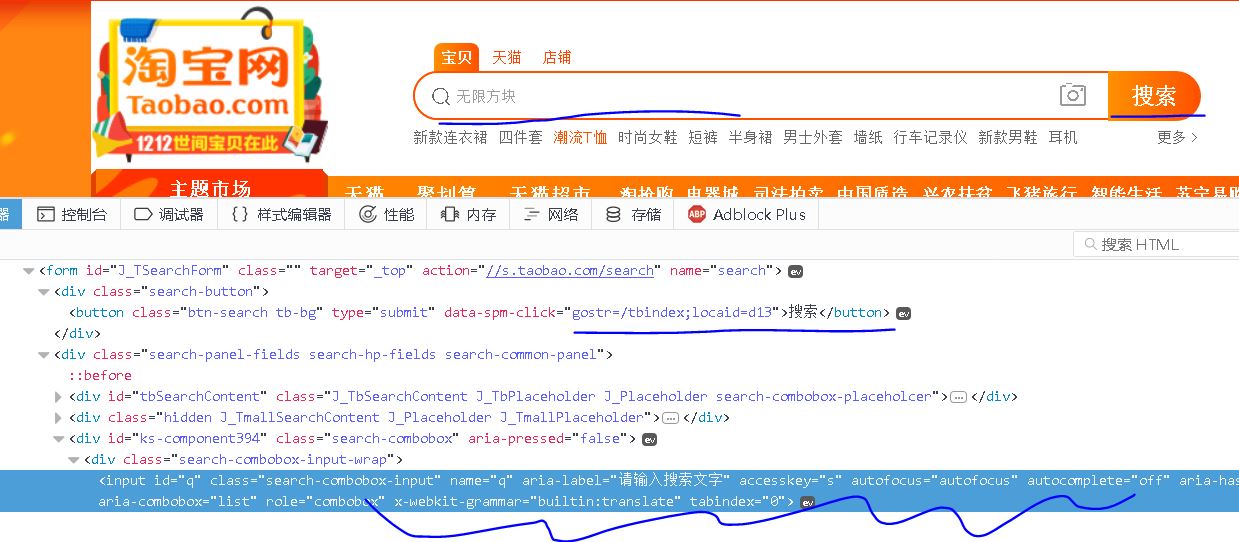
有两个元素是我们要获取到的,一个是搜索框,一个是搜索按钮。
在Selenium中得到元素的方法,请回顾一下我之前写的入门文章,或者查看Selenium的API文档,不是很负责。在本文中我们通过CSS选择器来选定元素。
另外一个需要注意的事情,Selenium模仿浏览器加载页面是受限于计算机和网络情况的,我们必须设置等待,否则很可能找不到这两个元素。
在Selenium的API文档中,我们借鉴如下代码,来显式等待元素的加载。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
这时另外一些判断调试,我们可能也会用到的。
得到输入框,我们将关键字填进去,然后点击搜索按钮即可。
第二步,如何获取多个显示宝贝的页面?
【插入图片,多页控制】

宝贝信息翻页的话,有两种方式,一个是点击下一页,或者直接在右边的输入框中写入你要打开的页面,然后点击后面的确认按钮。
这里我们选择第二种方式,而且这个过程与第一步中获取input和button的方法是一样的。
同时,我们需要获取到一共有多少页面。淘宝有限制的,只会显示100页的宝贝信息,大约是4000多宝贝,也足够我们进行简单分析了。
当然我们会通过代码来获取到这个100.
还有一个需要考虑的事情,在我们翻页之后,如何判定Selenium确实翻页了呢?
大家还是看上面图片中高亮的那个数字,如果我们要打开的页面,比如是第3页,高亮数字也是3的话,那么就说明翻页成功了。
-------text_to_be_present_in_element
上面的一个判断方法,这时就能够用上了。
我们今天先分析这么多,大家来看一下这两步的代码。
代码1 主页搜索
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
\'\'\'要搜索的关键字\'\'\'
KEYWORD=\'Iphone8\'
\'\'\'PhantomJS参数\'\'\'
SERVICE_ARGS=[\'--load-images=false\']#不加载图片,节省时间
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url=\'https://www.taobao.com/\'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector(\'#q\')
#user_search_button=browser.find_element_by_css_selector(\'.btn-search\')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'div.total\')))
total_page=re.compile(r\'(\\d+)\').search(total.text).group(1)
print(total_page)
return int(total_page)
except TimeoutException:
search(keyword)
我对上面的代码做一些解释:
1、webdriver可以用Firefox,但是会打开一个页面;PhantomJs是无头浏览器,比较适合;
2、选定input和button的代码,借鉴了API文档中的显式等待方法,CSS选择器对应的内容可以在浏览器中得到,前面也讲过类似,有疑问的话可以咨询我或者翻一下前面的内容。
3、send_keys()和click()是一些基本动作,控制元素。
4、在click之后,我们就打开了显示宝贝信息的页面,这时候就可以获取总共页面的数量了。由于文本是“共100页,”,我们用re解析一下只要数字。
这样browser就打开了宝贝信息的第一页,而且返回了总共的页码数。
代码2 获取下一页宝贝
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()#尤其注意要清空
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,\'li.active > span:nth-child(1)\'),str(pageNum)))
except TimeoutException:
get_next_page(pageNum)
实际上,获取多页我们是不断通过获取下一页来实现的。
这里我尝试了一下用XPATH定位,可以可以实现的。
尤其注意要清空pageinput里面的内容,否则会导致翻页错误。
最后判断一下,高亮页面是否是我们想要打开的那个页面代码。
运行
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__==\'__main__\':
main()
这里我们用了range方法,从第2页一直到最后一页,会依次打开,最终关闭浏览器(假如你用的是Firefox或者Chrome)。
请注意这里不能用多进程了,会报错的,模拟访问还是需要循序渐进。。。
