今天用node的cheerio模块做了个某乎的爬虫
Posted 三十亿少女的梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了今天用node的cheerio模块做了个某乎的爬虫相关的知识,希望对你有一定的参考价值。
一时兴起,想做个爬虫,经过各种深思熟虑,最后选择了某乎,毕竟现在某乎的数据质量还是挺高的。说干就干
打开某乎首页,随便搜索了一串关键字,相关的问题和答案就展现在眼前,我就思考怎么把这些搜索结果全部通过爬虫爬下来,方便收集(我也不知道收集来干嘛嘻嘻)。
发现搜索结果每页只会显示10条数据,某乎用的是点击加载更多数据,于是打开chrome的network工具,点击加载更多的按钮,发现多了一个新的ajax请求,很明显这个请求就是用来请求后十条数据的。
分析这个请求头,观察这个get请求的url最后的参数,offset=10,用脚都想的出来,这明显就是告诉后台我要的数据从哪条开始,而我要通过爬虫把后面的数据爬下来就是要在这个参数上做些手脚,我只要改一下后面的offset构造新的url,然后发送新的请求,就可以得到其他页面的数据。
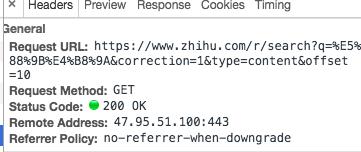
然而事情并没有那么简单,我们先自己手动构造一个请求url,用浏览器打开看一下,服务器返回如下图:
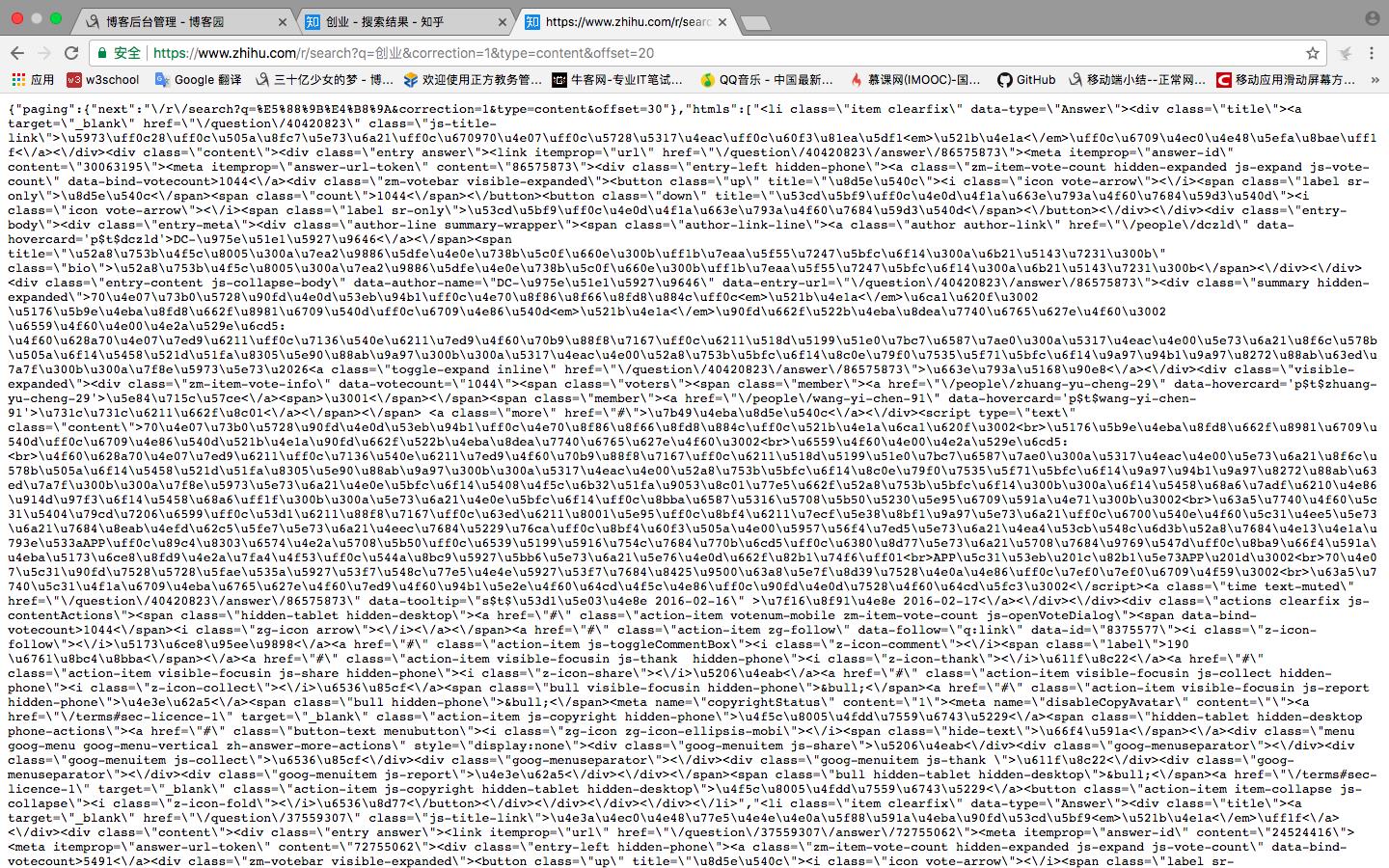
我滴个乖乖,这是什么鬼,但是不要慌张,虽然一眼看上去很恐怖,但是仔细分析一下就知道这是用了unicode编码而已,还有一堆转意字符。
我用的是node的https模块来进行get请求,拿到数据之后,先把拿到的数据(也就是上一张图上的那些乱七八糟的东西)用正则匹配把\\/替换成/,把\\"替换成",然后用node的cheerio模块就能解析出dom结构,然后就是提取出我们需要的信息,到这里我们已经可以把搜索结果的所有问题都爬下来了,但是这只是抓取到了问题,问题的答案我们还要跳转对应问题的链接才知道,同样打开chrome的开发者工具,这次用elements的功能,看一下问题对应的超链接 ,可以看到这是一个相对路径。所以我们只要把这个相对路径改为绝对路径就可以,其实也就是在这个相对路径前面加上www.zhihu.com就可以,得到路径之后,我们就可以用node的https.get方法去进行get请求,这样就可以得到对应问题的答案。美滋滋,爬下来的数据如下图(我利用node的fs模块把爬下来的数据写到了项目路径下的txt文档里):
,可以看到这是一个相对路径。所以我们只要把这个相对路径改为绝对路径就可以,其实也就是在这个相对路径前面加上www.zhihu.com就可以,得到路径之后,我们就可以用node的https.get方法去进行get请求,这样就可以得到对应问题的答案。美滋滋,爬下来的数据如下图(我利用node的fs模块把爬下来的数据写到了项目路径下的txt文档里):

果然,事情再一次没有想象中的简单,从数据可以看到,答案只抓取到了两个,然而答案并不应该只有两条,所以可以初步推测,当我们进入答案的页面,后台返回页面的时候只返回了两条答案,其他答案应该是用ajax后加载的。为了验证我的假设,我把答案页面的javascript禁止了,然后刷新,果然答案只返回了两条,所以,可以证明我的假设是正确的,下面要做的就是找到加载更多答案的那个ajax请求,国际惯例,打开chrome的network工具,查看有哪些ajax请求,如下图:
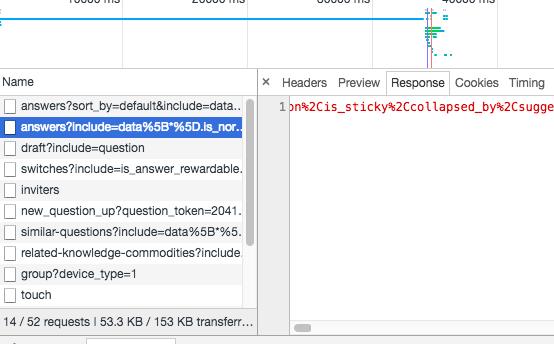
经过各种分析(响应大小,响应内容分析等等),最终锁定目标,上图被选中的get请求就是加载更多答案的那个get请求,把这个get请求url拷贝下来,我们在浏览器中打开看一下,结果如下图:
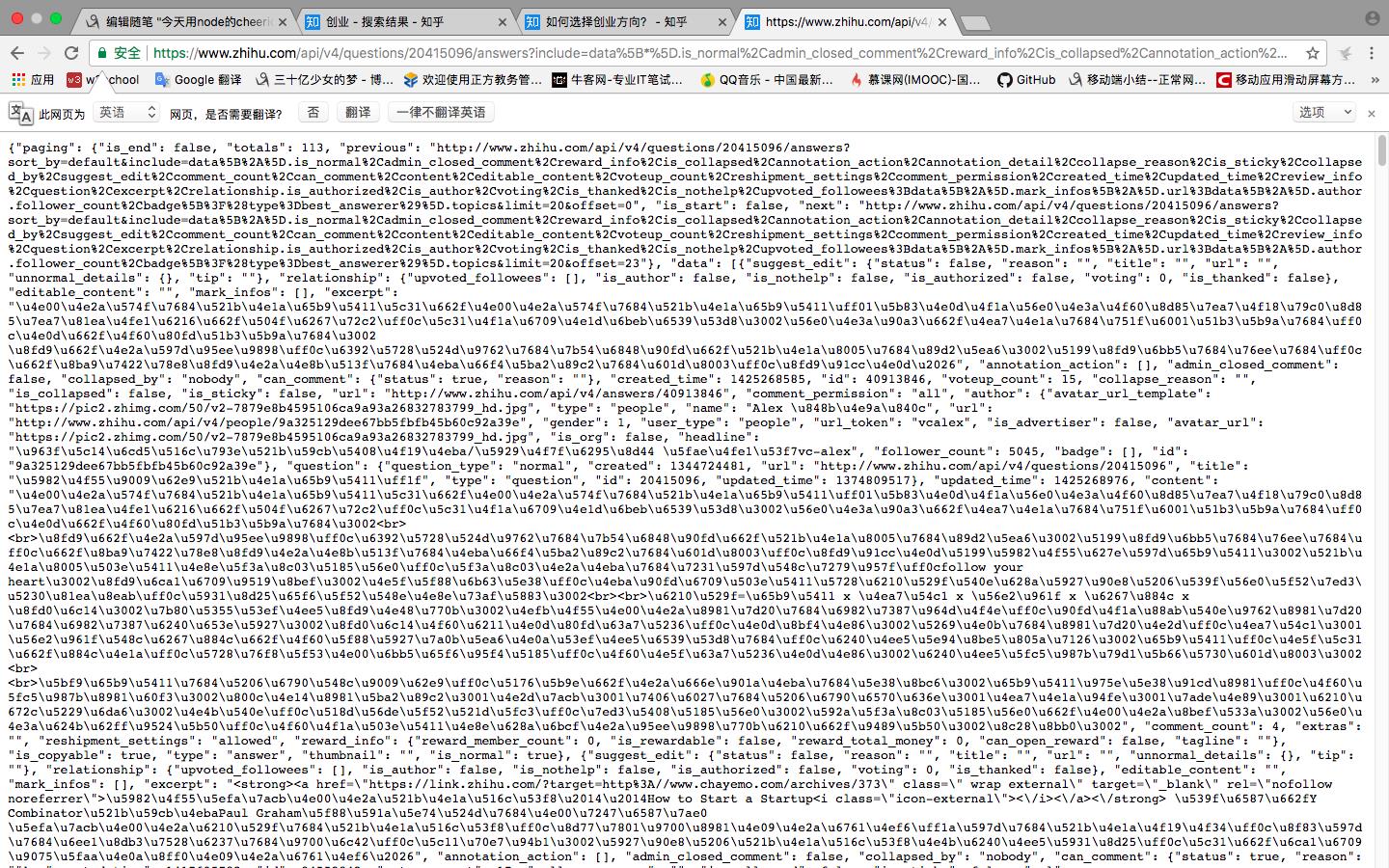
标准结局,结果又是一堆乱七八糟的东西,但是静下心来仔细分析,可以看到结果其实是一个json格式的数据,并且做了unicode编码,所以我们要做的就是把这些结果解码,之后用JSON.parse()方法把这个json字符串转换为json对象,然后就是对这个json对象进行一顿操作,最后分析出来。我们需要的内容就在这里面,把我们需要的内容拿到之后保存在txt文档中。
这样爬虫基本上就算完成了。效果如下图:

踩坑总结:
1.正则表达式转意字符,例: 我们要匹配 " 这个符号,正则表达式中需要在该符号之前加上转意字符\\
2.刚开始url请求更多答案的时候,服务器是返回100状态给我的,经过各种分析,最后发现是有登陆信息才能请求所有答案,所以我用node请求答案的时候需要做的一件事就是假装我是浏览器,并且我已经登陆了,嘻嘻嘻,这无非就是在请求头上做手脚。比如修改UA,添加一些对应的cookie,authorization等等
为了造福人民,我已经把源码在git开源了,点击这里,如能star,必将以身相许,嘻嘻嘻
以上是关于今天用node的cheerio模块做了个某乎的爬虫的主要内容,如果未能解决你的问题,请参考以下文章