[编译原理]用BDD方式开发lisp解释器(编译器)|开发语言java|Groovy|Spock
Posted thinking different
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[编译原理]用BDD方式开发lisp解释器(编译器)|开发语言java|Groovy|Spock相关的知识,希望对你有一定的参考价值。
lisp是一门简单又强大的语言,其语法极其简单:
(+ 1 2 )
上面的意思 是:+是方法或函数,1 ,2 是参数,fn=1+2,即对1,2进行相加求值,结果是:3
双括号用来提醒解释器开始和结束。
之前在iteye写过一篇文章来简单介绍怎么写lisp的解释器:
http://gyc567.iteye.com/blog/2242960
同时也画了一张草图来说明:
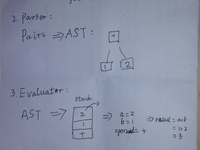
因为lexer(词法分析器)主要工作就是把程序的字符串表达式转化为tokens.(Pair),以下是百科对词法分析的说明:
词法分析是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
因为lisp的语法极其简单,词法分析可以认为就是把字符串“(+ 1 2 )”转化为Pair对象,这个Pair 有两个属性:first,rest,first用来记录“+”,rest用来记录另一个Pair,如下图:
Pair1 :
first-->"+"
rest-->Pair2
Pair2:
first-->"1"
rest-->"2"
所以这里主要关注parser,parser主要工作是把Pair对象转化为抽象语法树(AST),并对其他求值返回。
以上是关于[编译原理]用BDD方式开发lisp解释器(编译器)|开发语言java|Groovy|Spock的主要内容,如果未能解决你的问题,请参考以下文章