解决IE浏览器下载文件,文件名乱码问题(浏览器历史介绍)
Posted QGuo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决IE浏览器下载文件,文件名乱码问题(浏览器历史介绍)相关的知识,希望对你有一定的参考价值。
这个问题,CS开发模式总会遇到过。在此详细记录,以作技能储备。
先说段历史故事:
史前世界:1945~1994年 有一位美国科学家叫Vannevar Bush3在1945年虚构出来了一台名为Memex的桌面设备作为Web理念最早期的原型。这个Memex呢,用于在微缩胶卷上创建和标注跨文档链接,并按照这些链接而跳转切换到所引用的其他微缩胶卷上,使用方式大略类似于我们现在的书签和超链接。
他超级兴奋,认为这将革命性地改变知识管理和数据挖掘;
在当时,一直到20世纪90年代初期,挺多的人觉得这种想法非常的愚笨天真可笑。
20世纪60年代,诞生了IBM的GML(Generalized Markup Language,通用标记语言),它用可供机器读取识别的指令作为文档的标识符,以标志每段文本的功用,可以明确地指明“这里是文档的头部”,“这里是几个列表项目”诸如此类。
在此后经过20多年的发展,GML(一开始只是用在一些IBM笨重大型机的文本编辑器里)逐渐演变成SGML(Standard Generalized Markup Language,标准通用标记语言)。SGML语言更通用灵活,它把GML原来基于冒号和句号的笨拙语法,改成了我们熟悉的尖括号格式的语法。
又过10年之后,有两位科研人员,Tim Berners-Lee 和Dan Connolly 开始寻找新的跨域引用方案—这个方案必须非常简洁明了。他们草拟了html(HyperText Markup Language,超文本标记语言),Html是一套继承自SGML的精简版语言。随后他们又进而开发了HTTP协议(HyperText Transfer Protocol ,超文本传输协议)
他们研究工作的总成果就是这个诞生于 1991~1993之间由Tim Berners-Lee开发的World Wide Web 程序,这个最原始状态的浏览器可以解析HTML文件,还可以把用户提交的数据显示出来,并且只需要点击一下鼠标,就可以在不同页面之间切换浏览。
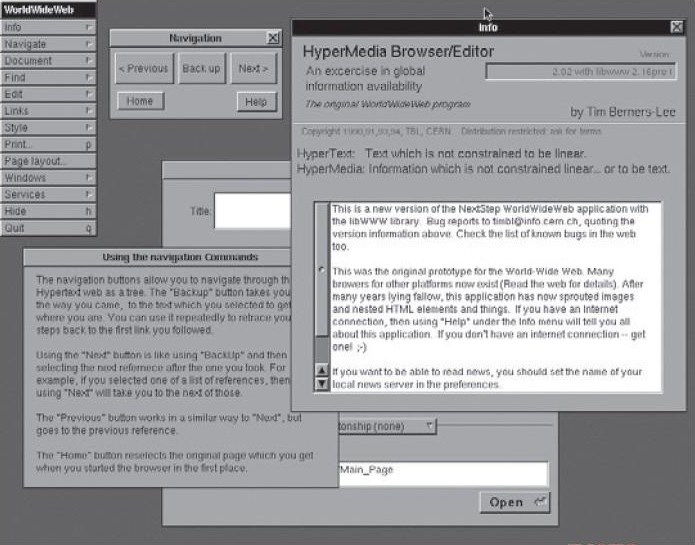
|
W3C 成立原因: 浏览器开发商之间的这场军备竞赛主要体现在各竞争产品都在非常快速地开发迭代,以及疯狂加入各种新功能,也就完全无法顾及产品是否符合规范标准,甚至来不及用正儿八经的文档记录下各种新代码新功能。对核心HTML特性的擅自调整包括各种蠢事(如闪烁的文字,这是Netscape的发明创造,但最终沦为笑柄)乃至一些著名的特性,如可更换字样(Typeface)或可以在所谓的框架(Frame)里嵌入外部文档。在各浏览器厂商的产品里,往往还内置对自家编程语言(如javascript和Visual Basic)支持,以及可在用户机器上执行跨平台Java或Flash小程序的插件,支持有用但颇诡异的各种HTTP扩展(如Cookie)。这一阶段的浏览器尽管囿于某些专利和商标上的原因,彼此间会有兼容性问题,但这些不兼容大都还比较表面。 随着Web的日益发展壮大和百花齐放,一种隐秘的恶疾悄然在浏览器引擎之间传播开来,尽管表面上还勉强维持着兼容性。这么做最开始的理由听上去还蛮合情合理的:如果浏览器A可以正常显示一个有问题的页面,而浏览器B却拒绝解析这个页面(无论基于何种原因),用户肯定会认为这是浏览器B有问题,而一股脑地选择貌似更强大的浏览器A。为了确保浏览器可以正确地显示任何网页,工程师的开发变得越来越复杂,也没有什么正式的文档来描述浏览器对于网站管理员胡乱提供的网页,是怎么进行主动猜测解析的,而在这些处理过程中往往会牺牲掉安全性,偶尔也会累及兼容性。遗憾的是,这样的变动往往又会进一步纵容各种不靠谱的网页设计观念,迫使其他浏览器开发商为免掉队,也只能亦步亦趋地跟进。当然,相关规范标准的细节缺失,更新也不及时,更是助长了这种恶疾的蔓延。 |
第一次浏览器大战:1995~1999年
网景导航者 Netscape Navigator:

1994公布0.9版,修改后发布1.0版本;
1996年网景的占有率达到70%的高峰。

1995年发布IE1;
1996年,Windows操作系统绑定安装了IE浏览器,开始占领市场;
2002年IE拥有了95%的市场份额。
IE完胜。
Netscape Navigator退出市场
同时垄断也滋生了自满,微软处于无敌地位之后就完全缺乏动力去改进自己的浏览器。
虽然有很多漏洞和安全问题,但其他势单力孤的浏览器厂商难带来什么翻天覆地的变化。
另一方面,缓慢的开发进展使W3C得以追上浏览器的实际状况,并认真探索未来Web的一些新概念。
XMLHttpRequest微软推出的一个颇不起眼的专有API,没想到现在却如此的大放异彩。
第二次浏览器大战:2004年至今
2004年,浏览器舞台上出现了一位新选手:

Mozilla Firefox(原网景公司Navigator浏览器的后裔,由开源社区开发)它针对的正是IE糟糕的安全性和与标准的不兼容性。在获得IT专栏作家和安全专家的普遍肯定后,Firefox 很快获得了20%的市场份额。尽管这位后来者很快也被证明和微软浏览器一样,受到各种安全漏洞困扰,但由于Firefox的开源特性,以及无需迎合顽固的企业用户,使它的问题修复较为迅速及时。
| 注意:为什么浏览器开发领域里的竞争如此激烈呢?严格来说,浏览器的市场份额并没有办法直接转化成金钱收入。但专家们认为这关乎权势地位:因为可以通过浏览器来捆绑、推销或边缘化某个在线服务(即使像默认搜索引擎这么简单的服务),也就是说谁控制了浏览器,谁就控制了互联网。注意 为什么浏览器开发领域里的竞争如此激烈呢?严格来说,浏览器的市场份额并没有办法直接转化成金钱收入。但专家们认为这关乎权势地位:因为可以通过浏览器来捆绑、推销或边缘化某个在线服务(即使像默认搜索引擎这么简单的服务),也就是说谁控制了浏览器,谁就控制了互联网。 这些事实连同突然杀入市场的苹果公司浏览器Safari和Opera浏览器在智能手机领域的步步领先,一定使微软的高层深觉头痛不已。他们已经错失了20世纪90年代互联网第一波高潮;当然他们不想再犯同样的错误。微软重新加大了对IE浏览器的投入,发布了有极大提升和在某些方面来说更安全的版本,从IE7、8迅速迭代到了IE9。 好像还嫌事情不够混乱,由于对W3C理事会在创新性上的不满,一群参与者创建了一个全新的标准组织,叫网页超文本技术工作小组(Web Hypertext Application Technology Working Group,WHATWG)来主导HTML5协议的开发,这是对现有标准的第一次整体性和把安全也考虑进去的修订,但据报道,他们经常由于专利纷争而没法和微软达成一致(所以HTML5在IE中存在不兼容)。 |
再说个历史问题。
首先,根据 HTTP 1.1 协议规范( RFC 2616 Section 4 ), HTTP 消息格式其实是基于古老的 ARPA INTERNET TEXT MESSAGES ( RFC 822 Section 3 ),根据其规定,消息只能是 ASCII 编码的。 RFC 2616 Section 2.2 又一次强调, TEXT 中若要使用其他字符集,必须使用 RFC 2047 的规则将字符串编码为 ASCII 码(事实上这个规则原本是针对 MIME 的扩展,使用的是 base64 编码,格式与百分号编码有很大不同)。总而言之,按照标准, HTTP Header 中的文本数据必须是 ASCII 编码的。
filename="TEXT" ;这是 RFC 2616 标准,TEXT必须是 ASCII 字符且被认为就是“原文” filename*=charset\'lang\'encoded-text ;这是按照 RFC 2047 扩展后的,注意格式上的细微区别,采用 base64 编码(编码结果也是 ASCII 字符)然而,事实上在1999年 HTTP 1.1 标准推出之时, Content-Dispostion 这个 Header 尚不是正式标准的一部分,只不过是因为被广泛使用而从 MIME 标准中直接借用过来了而已( RFC 2616 Section 19.5.1 )。因而几乎没有浏览器去支持 Content-Disposition 的多语言编码特性这样一个“扩展特性的扩展特性”(事实上, HTTP 1.1 草案中建议的使用 RFC 2047 来进行多语言编码的特性从未被主流浏览器支持过)。 可是这个问题却的确是现实需要的,所以浏览器就各自想出了一些办法:
- IE支持两种格式的混合版:filename="encoded_text" (这里采用的是百分号编码)。本来按照 RFC 2616 ,引号内的部分应当直接被当作内容,就算它“看起来像是编码后的字符串”;可是IE却会“自动”对这样的文件名进行解码——前提是该文件名必须有一个不会被编码的后缀名(即正常的英文字母后缀名)!
- 其他一些浏览器则支持一种更为粗暴的方式——允许在 filename="TEXT" 中直接使用 UTF-8 编码的字符串!