Day 2
Posted Aline
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day 2相关的知识,希望对你有一定的参考价值。
模块
sys
import sys
print(sys.path) #输出相对路径
print(sys.argv) #输出绝对路径
os
import osos.system("ipconfig") #调用系统dos命令Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
数据运算
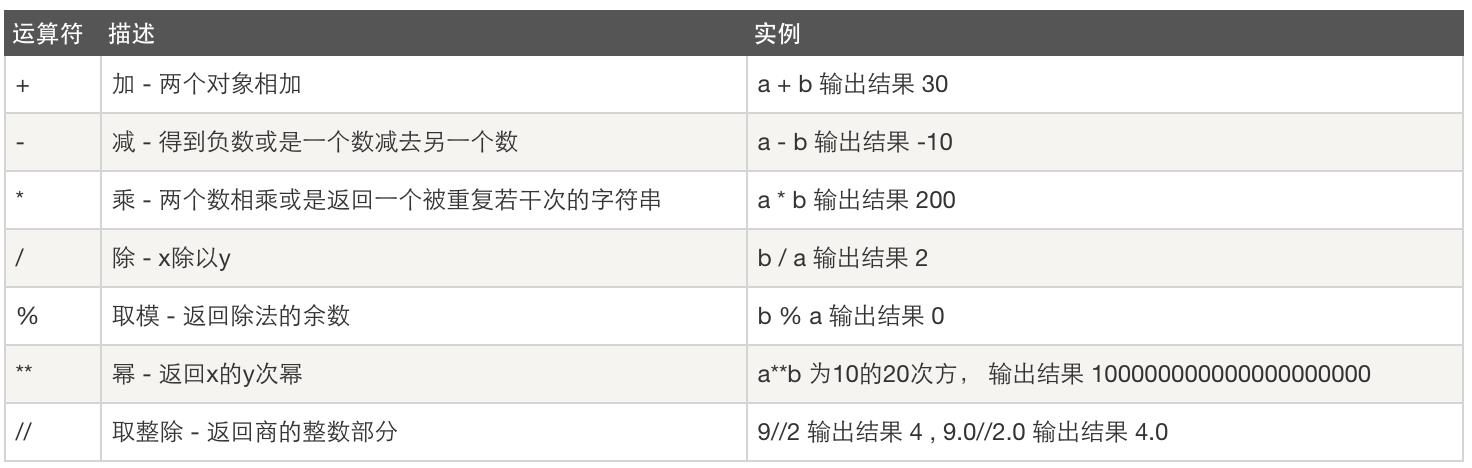
比较运算:

赋值运算:
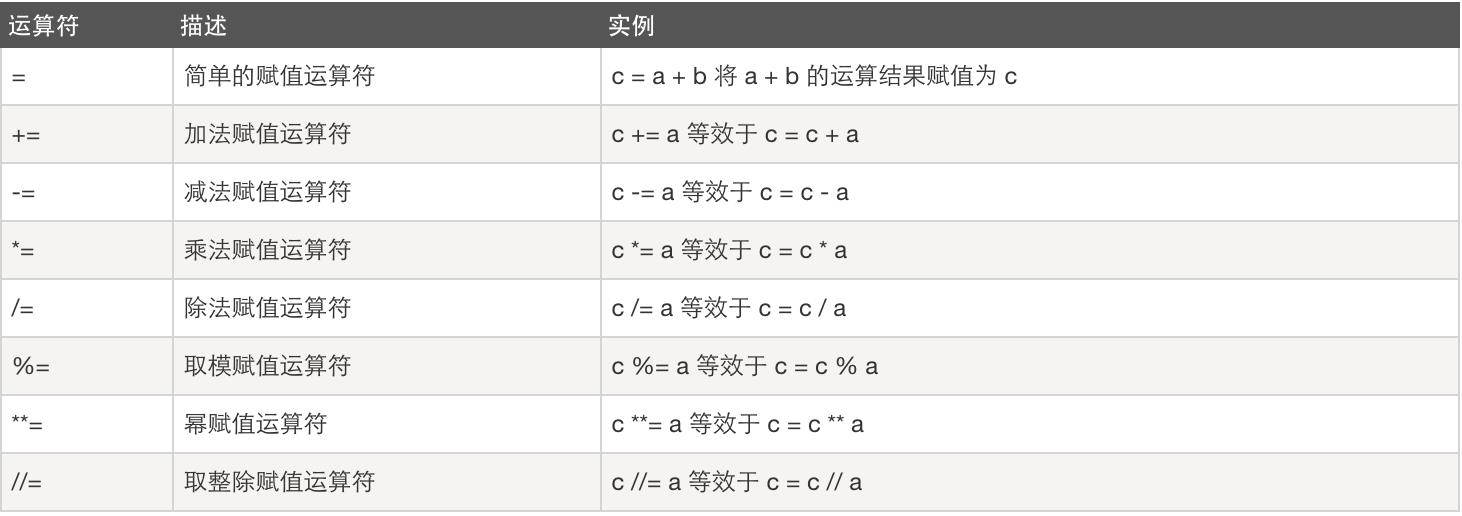
逻辑运算:

成员运算:

身份运算:

位运算:
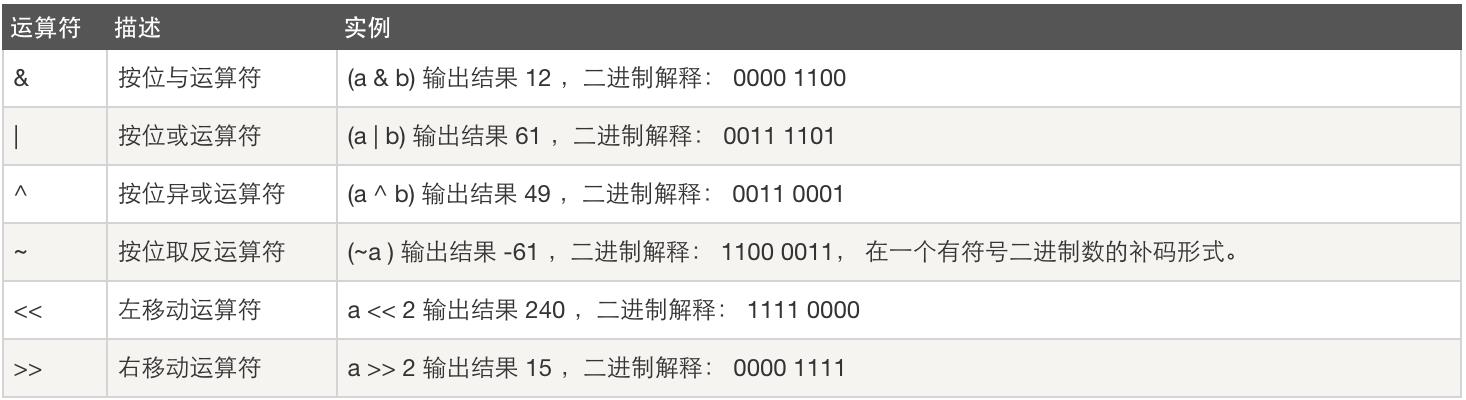


#!/usr/bin/python a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = 0 c = a & b; # 12 = 0000 1100 #与 c = a | b; # 61 = 0011 1101 #或 c = a ^ b; # 49 = 0011 0001 #相同为0,不同为1 #异或 c = ~a; # -61 = 1100 0011 #取反 c = a << 2; # 240 = 1111 0000 #左移 ,变大 c = a >> 2; # 15 = 0000 1111 #左移 变小
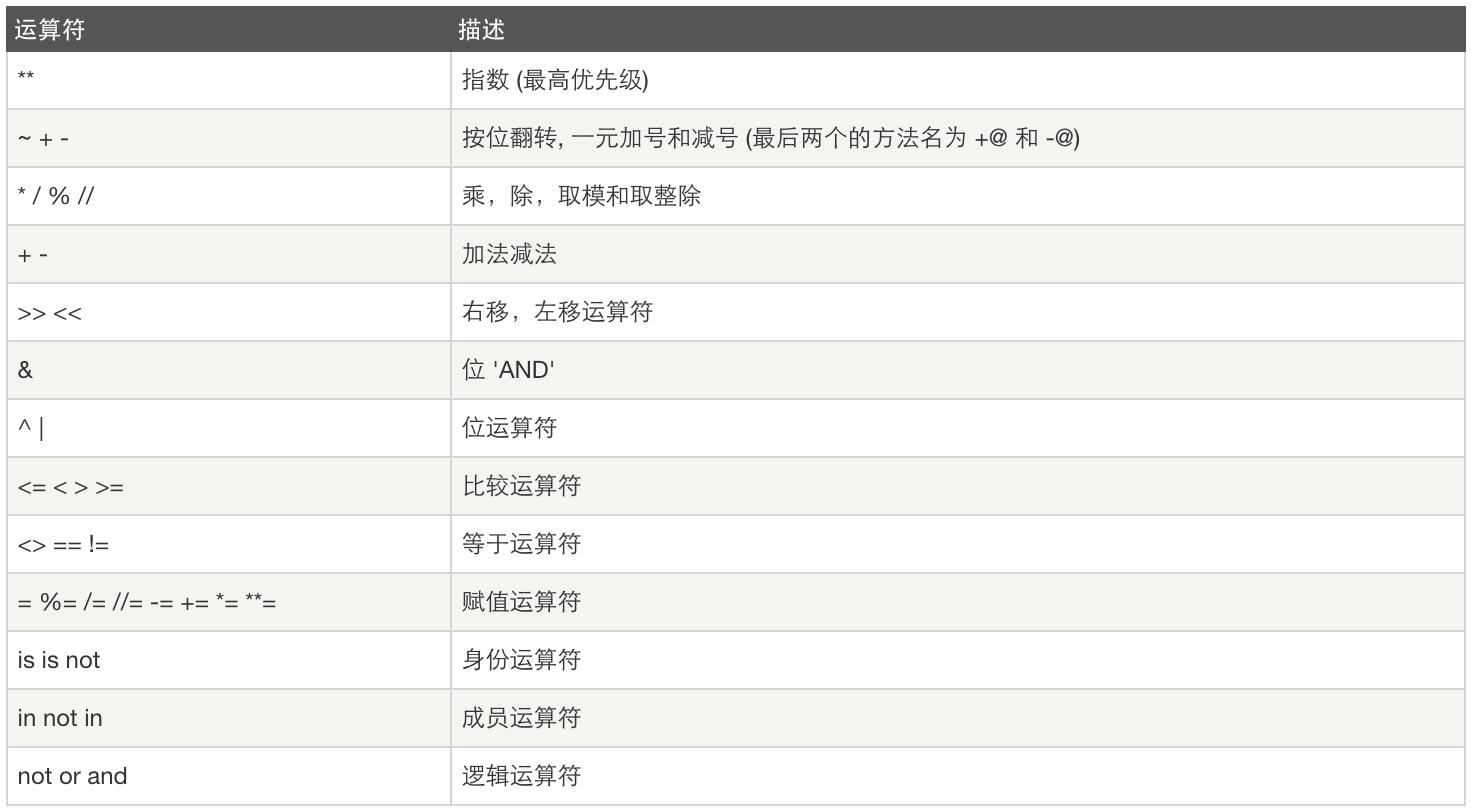
运算符优先级:
三元运算
result = 值1 if 条件 else 值2如果条件为假:result = 值2
1. 列表、元组操作
列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作
定义列表
names = [\'aaa\',"bbb",\'ccc\',\'1\',\'2\']>>> names[0] \'aaa\' >>> names[2] \'ccc\' >>> names[-1] 2 >>> names[-2] #倒着取 1
切片
>>> names = ["aaa","bbb","ccc","ddd","eee"] >>> names[1:3] #取下标1至下标3之间的数字,包括1,不包括3 ["bbb","ccc"] >>> names[1:-1] #取下标1至-1的值,不包括-1 ["aaa","bbb","ccc","ddd"] >>> names[0:3] ["aaa","bbb","ccc"] >>> names[:3] #如果是从头开始取,0可以忽略 ["aaa","bbb","ccc"] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 ["ddd","eee"] >>> names[3:-1] #这样-1就不会被包含了 ["ddd"] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 ["aaa","ccc","eee"] >>> names[::2] #和上句一样 ["aaa","ccc","eee"]
追加
>>> names names = ["aaa","bbb","ccc","ddd","eee"]
>>> names.append("通过追加方法加入的") #默认是追加到最后
>>> names
["aaa","bbb","ccc","ddd","eee","通过追加方法加入的"]
删除
names = ["aaa","bbb","ccc","ddd","eee"] del names #删除整个列表 del names[0] #删除下标为0的元素 names.pop() #默认删除最后一个元素 names.pop(\'aaa\') #删除指定元素 names.renove("bbb") #删除指定元素
插入
names = ["aaa","bbb","ccc","ddd","eee"] names[2]=1 print(names) names = ["aaa","bbb",1,"ddd","eee"]
names.insert(\'插入的\') #默认加入最后一个 names.nisert(0,"强制插入第一个") #从指定位置插入
扩展
>>> names [\'Alex\', \'Tenglan\', \'Rain\', \'Tom\', \'Amy\'] >>> b = [1,2,3] >>> names.extend(b) >>> names [\'Alex\', \'Tenglan\', \'Rain\', \'Tom\', \'Amy\', 1, 2, 3]
列表的复制
>>> names [\'Alex\', \'Tenglan\', \'Rain\', \'Tom\', \'Amy\', 1, 2, 3] >>> name_copy = names.copy() >>> name_copy [\'Alex\', \'Tenglan\', \'Rain\', \'Tom\', \'Amy\', 1, 2, 3]
通过导入copy模块拷贝
import copy
list1=[1,2,3,4,[1,2,3]]
list2=copy.copy(list1) #浅拷贝
list3=copy.deepcopy(list1) #深拷贝
list1[1]=0
list1[4][0]=0
print(list2)
print(list3)
#[1, 2, 3, 4, [0, 2, 3]]
#[1, 0, 3, 4, [0, 2, 3]]
统计列表中相同的元素
>>> list1=[1,2,3,4,1,3,6,7] >>> print(list1.count(1)) 2
排序,翻转
>>> list1=[1,2,3,4,1,3,6,7] >>> list1.sort() #排序 >>> print(list1) [1, 1, 2, 3, 3, 4, 6, 7] >>> list1.append(\'aaa\') >>> print(list1) [1, 1, 2, 3, 3, 4, 6, 7, \'aaa\'] >>> list1.sort() Traceback (most recent call last): File "<stdin>", line 1, in <module> #不同数据类型不能一起比较 TypeError: \'<\' not supported between instances of \'str\' and \'int\' >>> list1.pop() \'aaa\' >>> list1.reverse() #翻转 >>> print(list1) [7, 6, 4, 3, 3, 2, 1, 1]
获取下标
[7, 6, 4, 3, 3, 2, 1, 1] >>> list1.index(4) 2 >>> list1.index(3) 3
元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
它只有2个方法,一个是count,一个是index
字符串操作
特点:不可修改,通常修改了,是重新生成了一个新的,不是在原有基础上修改的
name.capitalize() 首字母大写 name.casefold() 大写全部变小写 name.center(50,"-") 输出 \'---------------------Alex Li----------------------\' name.count(\'lex\') 统计 lex出现次数 name.encode() 将字符串编码成bytes格式 name.endswith("Li") 判断字符串是否以 Li结尾 "Alex\\tLi".expandtabs(10) 输出\'Alex Li\', 将\\t转换成多长的空格 name.find(\'A\') 查找A,找到返回其索引, 找不到返回-1 format : >>> msg = "my name is {}, and age is {}" >>> msg.format("alex",22) \'my name is alex, and age is 22\' >>> msg = "my name is {1}, and age is {0}" >>> msg.format("alex",22) \'my name is 22, and age is alex\' >>> msg = "my name is {name}, and age is {age}" >>> msg.format(age=22,name="ale") \'my name is ale, and age is 22\' format_map >>> msg.format_map({\'name\':\'alex\',\'age\':22}) \'my name is alex, and age is 22\' msg.index(\'a\') 返回a所在字符串的索引 \'9aA\'.isalnum() True \'9\'.isdigit() 是否整数 name.isnumeric name.isprintable name.isspace name.istitle name.isupper "|".join([\'alex\',\'jack\',\'rain\']) \'alex|jack|rain\' maketrans >>> intab = "aeiou" #This is the string having actual characters. >>> outtab = "12345" #This is the string having corresponding mapping character >>> trantab = str.maketrans(intab, outtab) >>> >>> str = "this is string example....wow!!!" >>> str.translate(trantab) \'th3s 3s str3ng 2x1mpl2....w4w!!!\' msg.partition(\'is\') 输出 (\'my name \', \'is\', \' {name}, and age is {age}\') >>> "alex li, chinese name is lijie".replace("li","LI",1) \'alex LI, chinese name is lijie\' msg.swapcase 大小写互换 >>> msg.zfill(40) \'00000my name is {name}, and age is {age}\' >>> n4.ljust(40,"-") \'Hello 2orld-----------------------------\' >>> n4.rjust(40,"-") \'-----------------------------Hello 2orld\' >>> b="ddefdsdff_哈哈" >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 True
字典操作
语法:
info = {
\'stu1101\': "TengLan Wu",
\'stu1102\': "LongZe Luola",
\'stu1103\': "XiaoZe Maliya",
}
字典的特性:
- dict是无序的,so无下标
- key必须是唯一的,so 天生去重
info = { \'s1\': "zhangsan", \'s2\': "lisi", \'s3\': "wangwu", } info[\'s4\']=\'张三\' print(info) #{\'s1\': \'zhangsan\', \'s2\': \'lisi\', \'s3\': \'wangwu\', \'s4\': \'张三\'} info[\'s3\']=\'haha\' print(info) #{\'s1\': \'zhangsan\', \'s2\': \'lisi\', \'s3\': \'haha\', \'s4\': \'张三\'} #info.clear() #删除整个字典 #copy() info2=info.copy() #浅拷贝 #fromkeys print(dict.fromkeys([3,2,1],\'hehe\')) #通过一个列表生成默认dict ,不常用 #get 获取key的值,有返回value,否返回none print(info.get("s3")) #item 将字典转成列表,元素以元组方式存储 print(info.items()) #dict_items([(\'s1\', \'zhangsan\'), (\'s2\', \'lisi\'), (\'s3\', \'haha\'), (\'s4\', \'张三\')]) #获取字典中所有key print(info.keys()) #dict_keys([\'s1\', \'s2\', \'s3\', \'s4\']) #获取字典中所有value print(info.values()) #dict_values([\'zhangsan\', \'lisi\', \'haha\', \'张三\']) #删除指定值 print(info.pop(\'s1\')) #zhangsan # 随机删除 print(info.popitem()) #setdefault 若key存在,保持值不变,若不存在,添加到字典 info.setdefault(\'s5\',\'hehe\') info.setdefault(\'s2\',\'hehe\') #update 将一个字典添加到另一个字典中 a={8:7,9:5} info.update(a) print(info) #{\'s2\': \'lisi\', \'s3\': \'haha\', \'s4\': \'张三\', \'s5\': \'hehe\', 8: 7, 9: 5}
修改key:
dict1={\'name\':\'aaa\',\'age\':\'23\'}
dict1[\'Name\']=dict1.pop(\'name\')
print(dict1)
#{\'age\': \'23\', \'Name\': \'aaa\'}
循环dict
for key in info: print(key,info[key])
集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
1 >>> a={1,2,3,4,3,6,8,9,1} 2 >>> b={9,0,76,45,3,1,56} 3 >>> print(a.intersection(b)) 交集,返回两个共有的 4 {1, 3, 9} 5 >>> print(a.union(b)) 并集,返回两个集合的值,重复会自动删除 6 {0, 1, 2, 3, 4, 6, 8, 9, 76, 45, 56} 差集 在a不在b 7 >>> print(a.difference(b)) 8 {8, 2, 4, 6} 9 >>> print(b.difference(a)) 10 {0, 56, 76, 45} 11 >>> c={1, 3, 9} 12 >>> print(a.issuperset(c)) 父集 13 True 14 >>> print(c.issubset(a)) 子集 15 True 16 >>> print(c.issubset(b)) 17 True 18 >>> print(a.issubset(c)) 19 False
>>> print(a.symmetric_difference(b)) 对称差集,删除两个集合同时有的
{0, 2, 4, 6, 8, 76, 45, 56}
>>> print(b.symmetric_difference(a))
{0, 2, 4, 6, 8, 76, 45, 56}
set2.add(\'aaaa\') #添加
set3.update([34,45,56]) #添加多个
print(set3) set1.clear() #删除所有
以上是关于Day 2的主要内容,如果未能解决你的问题,请参考以下文章