七字符编码文件处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了七字符编码文件处理相关的知识,希望对你有一定的参考价值。
先了解
文本编辑器存取文件原理
打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。 在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
python解释器执行py文件原理
一:python解释器启动,此时就相当于启动了一个文本编辑器 二:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) 三:python解释器解释执行刚刚加载到内存中test.py的代码( 在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码)
python解释器与文本编辑器的区别
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样 不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,是为了执行python代码、会识别python语法。
字符编码
字符编码就是代码翻译成计算机能执行的二进制文件的标准
计量单位
bit 比特位 1Bytes=8bit Bytes字节 1KB=1024Bytes 1MB=1024KB 1GB=1024MB 1TB=1024GB
编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
字符编码的发展
#阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符 ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了 #阶段二:为了满足中文和英文,中国人定制了GBK GBK:2Bytes代表一个中文字符,1Bytes表示一个英文字符 为了满足其他国家,各个国家纷纷定制了自己的编码 日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里 #阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。如何解决这个问题呢??? #!!!!!!!!!!!!非常重要!!!!!!!!!!!! 说白了乱码问题的本质就是不统一,如果我们能统一全世界,规定全世界只能使用一种文字符号,然后统一使用一种编码,那么乱码问题将不复存在, ps:就像当年秦始皇统一中国一样,书同文车同轨,所有的麻烦事全部解决 很明显,上述的假设是不可能成立的。很多地方或老的系统、应用软件仍会采用各种各样的编码,这是历史遗留问题。于是我们必须找出一种解决方案或者说编码方案,需要同时满足: #1、能够兼容万国字符 #2、与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码 这就是unicode(定长), 统一用2Bytes代表一个字符, 虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系,准确地说unicode并不是一种严格意义上的字符编码表 很明显对于通篇都是英文的文本来说,unicode的式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的) 于是产生了UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存
注:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
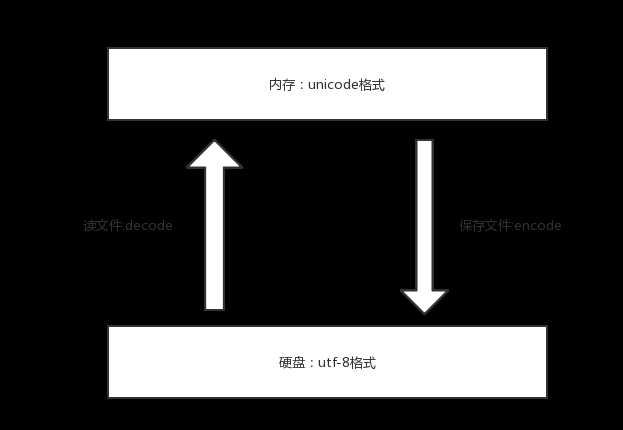
encode: 结果是Bytes
decode: 结果是unicode
python2与python3中字符串区别
python2中字符串有str和unicode两种类型,如下定义:
s1 = ‘asd‘ s2 = u‘aaaaaaa‘
python3中字符串有unicode和 Bytes两种类型,默认是unicode类型,所以只能encode,不能decode
注:python3中的unicode就是python2中的str
python3中x.encode(‘gbk‘) 就是python2中的str类型的值,而在python3是bytes类型,在python2中则是str类型
查看python2中源码发现,python2中字符串识别为Bytes,Bytes是unicode encode得来的,实际上pyhon2中字符串就是编码后的结果
文件处理
应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,比如文件处理
操作文件的流程:
1.打开文件,得到文件句柄并赋值给一个变量 2. 通过句柄对文件进行操作 3. 关闭文件
python中操作文件:
#1. 打开文件,得到文件句柄并赋值给一个变量 f=open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) #默认打开模式就为r #2. 通过句柄对文件进行操作 data=f.read() #3. 关闭文件 f.close()
打开文件:
文件句柄 = open(‘文件路径‘, ‘模式‘) 模式包括: r: 只读(默认模式,文件必须存在,不存在抛异常) w: 写模式(不可读,文件不存在就创建,存在会清空内容) a: 追加模式(不可读,文件不存在就创建,存在就在末尾追加内容) +: 读写(不能单独用) b: 二进制模式(不能单独用) 打开模式不同,返回的对象也不同: 文本模式(TextIOWrapper) 读二进制(rb)(BufferedReader) 写和追加二进制(wb,ab)(BuffereWriter) 读/写模式(含有 + 的)(BufferedRandom)
通常文件都是以文本模式打开,从文件读写以编码格式进行编码(默认是UTF-8)
若以二进制模式打开,数据以字节对象进行读写
f.open(‘text.txt‘,‘wb+‘) f.write(‘I love you‘) # 报错 f.write(b‘ I love you‘) # 以Bytes写
注意:
windows中的路径分隔符 \\ , 在open中的路径,可以在最前面加上 r ,表示原始字符串,那么 \\ 就不会转义
Bytes对象是0到127的不可修改整数序列,或者纯粹的ascii字符,用来存储二进制数据
创建Bytes对象:
1.在字符串前面加‘b‘
2.通过bytes()函数
bytes()函数必须提供编码,它的初始化器只是一个字符串
s = bytes(‘shuai‘,‘UTF-8‘)
转换:
字符串与字节是不兼容的,bytes转str必须进行解码,使用decode()
s = bytes(‘shuai‘,‘UTF-8‘) print(s) # b‘shuai‘ print(s.decode()) #shuai
修改文件:
文件存在硬盘,不存在修改,其实就是覆盖的操作
.swap 表示临时的文件
将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘
import os
with open(‘a.txt‘) as read_f,open(‘.a.txt.swap‘,‘w‘) as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace(‘2B‘,‘SB‘) #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove(‘a.txt‘)
os.rename(‘.a.txt.swap‘,‘a.txt‘)
将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os
with open(‘a.txt‘) as read_f,open(‘.a.txt.swap‘,‘w‘) as write_f:
for line in read_f:
line=line.replace(‘2B‘,‘SB‘)
write_f.write(line)
os.remove(‘a.txt‘)
os.rename(‘.a.txt.swap‘,‘a.txt‘)
循环读取文件:
f = open(r‘F:\\Python\\a.txt‘,‘r‘,encoding=‘utf-8‘)
l = f.readlines()
for i in range(len(l)):
print(l[i])
这种运用索引来循环,一下把文件内容都读到内存,如果内容过大,直接撑爆内存
for line in f:
print(line)
这种不依赖索引,读一行打印一行,同一时间内存只有一行内容
上下文with:
f = open(‘a,txt‘,‘r‘,encoding=‘utf-8)
f.close()
等同于
with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as f:
这里操作代码执行完后自动关闭文件
文件对象方法
file.close() 关闭文件。关闭后文件不能再进行读写操作。 f.closed() 用来判断文件是否关闭 file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 f.name() 查看文件名 f.encoding() 查看文件字符编码 f.readable() 查看文件是否可读 f.writable() 查看文件是否可写 file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。 file.next() 返回文件下一行。 file.read([size]) 从文件读取指定的字符数(如一个汉字一个字母),如果未给定或为负则读取所有。 file.readline([size]) 读取整行,包括 "\\n" 字符。 file.readlines([sizehint]) 读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 file.seek(offset[, from_what]) 设置文件当前光标位置,offset是移动的字节数(不是字符!!),from_what是光标是位置:0是文件开头(默认),1是当前位置,2是问末尾 file.tell() 返回文件光标当前所处位置。 file.truncate([size]) 截取文件,截取的字节通过size指定,从光标位置开始,写操作 file.write(str) 将字符串写入文件,没有返回值。 file.writelines([str]) 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
以上是关于七字符编码文件处理的主要内容,如果未能解决你的问题,请参考以下文章