我的物联网项目前期线上事故
Posted 心灵之火
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我的物联网项目前期线上事故相关的知识,希望对你有一定的参考价值。
一 MQTT连接数报警
项目上线一个月左右,投放出去的摇摇车数量大概在200量左右,平均每天在线数(听说有些商家精打细算,有小孩需要坐车了才插电,平时都不插电,还有些干脆一直仍在角落懒的管)也就维持在100左右,当时在阿里云购买的MQTT配置是连接数上限2000(MQTT是按连接数购买的),像目前的摇摇车投放数用当时的配置绰绰有余了,连续一个月以来,都是正常化(现在想来,当初的推广策略不成熟,每天投放的摇摇车数量也是要么一天3,4台,要么连续好几天才推广3,4台),所以问题并没有暴露出来,不过出来混迟早要还的。
有天下午快下班的时候,突然MQTT不断报警,手机上5秒一次收到报警短信,提示MQTT连接数已经超标(用阿里云的产品感觉这块的预警功提示的还是蛮及时),因为当初也有一些摇摇车在做测试,频繁的使用到MQTT,所以当时也没太在意,叫测试人员先停一下在做测试(这个里面很尴尬,摇摇车扫码启动用到的测试环境和线上环境是同一个MQTT,这个后面再详情描述原因)以为过一会连接数会释放下去,但是手机收到报警短信越来越猛,当时第一时间想到的整体事故点应该在MQTT业务应用层这一端(手机扫码是通过http请求到MQTT应用层,MQTT应用层再扔消息到阿里云MQTT服务器),当初是2台MQTT应用层在做负载均衡集群,我登录2台服务器,分别用top命令查看两台服务器一台CPU在80%左右,另外一台CPU在60%左右,顿时觉得很诧异,这么点摇摇车数据请求不至于导致应用服务器承受不了,当时第一时间想到的是看看TCP的目前的连接数,结果一查吓了跳(使用命令:netstat -natp|awk ‘{print $7}‘ |sort|uniq -c|sort -rn),两台服务器的当前连接数都接近快1W多,还在持续上升(因为当时投放出去的摇摇车还在不断有人在使用消费),这个时候基本定位问题:手机扫码发送http请求到MQTT应用层,MQTT应用层每次仍消息到阿里云MQTT服务器,都需要建立连接。所以问题很有可能是没有释放连接,由于当初的代码逻辑比较简单,所以直接找到写这个代码的开发人员,一起喵了眼代码,果然如此,修改代码后,重新发包一切正常,手机报警短信立马停了。
public void sendMsgMqtt(String productId, String deviceId, String scontent, String topic){
String subTopic = getSubTopic(productId, deviceId, topic);
String clientId = getClientId();
MemoryPersistence persistence = new MemoryPersistence();
try {
final MqttClient sampleClient = new MqttClient(GlobalConstant.BROKER, clientId, persistence);
final MqttConnectOptions connOpts = getConnOpts(clientId);
log.info("Coin Connecting to broker: " + GlobalConstant.BROKER);
sampleClient.setCallback(new MqttCallback() {
public void connectionLost(Throwable throwable) {
log.info("mqtt connection lost");
throwable.printStackTrace();
while(!sampleClient.isConnected()){
try {
sampleClient.connect(connOpts);
} catch (MqttException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void messageArrived(String topic, MqttMessage mqttMessage) throws Exception {
log.info("coin messageArrived:" + topic + "------" + new String(mqttMessage.getPayload()));
}
public void deliveryComplete(IMqttDeliveryToken iMqttDeliveryToken) {
log.info("coin deliveryComplete:" + iMqttDeliveryToken.getMessageId());
}
});
sampleClient.connect(connOpts);
try{
scontent = scontent.replace("[", "").replace("]", "");
final MqttMessage message = new MqttMessage(scontent.getBytes());
message.setQos(1);
log.info("pushed at "+new Date()+" "+ scontent);
sampleClient.publish(subTopic, message);
log.info("-------send end---------");
}catch(Exception ex){
ex.printStackTrace();
}finally{
sampleClient.disconnect();
log.info("-------client disConnect()---------");
}
}catch(Exception ex){
ex.printStackTrace();
}
}二 数据库CPU100%
必须要先说下,创业项目初期,当初的业务都是很不清晰的,基本属于那种摸着石头过河,走一步算一步,再回头想想甚至看看市场的反应,然后再修改,所以这个阶段更多的是检验模式,优化业务,当然资金也有限,而且要求开发迭代要求迅速,所以数据库当初没有做集群,就是一台,玩单机,也正是因为玩单机,所以一些在集群环境下没有这么快爆发出来的问题很容易在单机里面爆发出来。
晚上大概7点左右(晚点7点到9点是摇摇车的使用高峰,白天一般订单数据较少,到了晚上数据成倍的增涨),收到反馈,说平台系统打开很慢很慢,而且手机也不断收到MQTT短信预警,说堆积了大量未消费的订单,第一时间的反应迅速登录云数据库管理平台看到数据库CPU这项指标严重标红,并显示使用率达到100%。当初数据库用的是通用型4核8G的,订单表数据将近40W,打开数据库性能管理界面查看(如果没有这种管理界面,也可以通过命令show processlist来查看正在执行的SQL和explain来分析执行计划查看慢SQL),发现积累了大量的慢SQL,有些SQL的平均执行时间超过将近1分钟,很明显做了数据库的全局扫描,再加上这段时间的高峰时期,慢SQL堆积,导致CPU资源顺序消耗完。
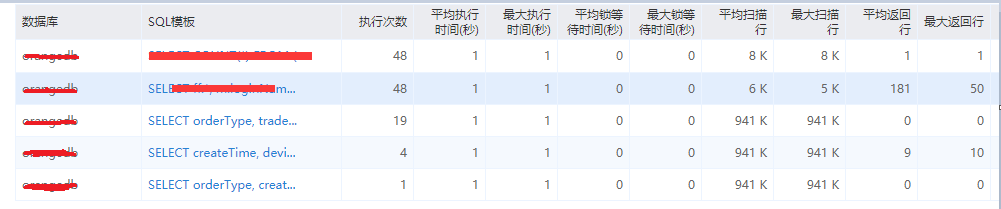
当时也正是业务的使用的高峰期,再加上客户投诉和上面很多人在盯着这个事情,所以我这边要在短时间内恢复数据库的正常,当初有几种选择可以迅速恢复,将数据库切换到备数据库(数据库是高可用的)或者kill掉一些慢SQL(通过show processlist查看state为Sending data的列,然后kill id),这些都有可能会影响到现在正在使用的业务,万不得已的情况的不会第一时间去做。我看了下排在前面的几条慢SQL,其中有些是第一时间可以迅速处理的,比如优化索引,我抱着试试的方法,将之前有些索引重新优化了下(后面会详细描述),过了几分钟,CPU的使用率慢慢的降了下来(没有优化索引之前大概3秒执行一个记录,优化索引后1秒可以执行上千个记录),业务正常了,给我后面做数据库的优化有了大把时间思考,所以这次事件给我最大的感触就是切勿头脑发热,需要冷静最小化处理问题。
这次SQL优化也总结了些经验并做了相关优化如下:
1.添加索引和优化索引,特别小心索引隐式转换
一个表里面如果只是设置了主键,然后其它索引一律不建不管,简单业务如只涉及到按照主键查询的业务是没问题,但是设计到其它字段的查询,在数据量稍大又加上业务高峰期,这种导致表全局查询的SQL肯定会积累大量慢SQL,最终导致CPU持续上升,如果有条件的话,测试最好做一些大数据量的压力测试是可以测试出来的,另外,建立了索引,也要注意到索引失效这种情况。如:select *from order where phone=13772556391; 平时写代码粗心大意,不仔细检查再加上压力测试没测试到位,在高并发数据量稍微大点的业务场景里面搞不好就出问题。数据库表phone字段用的字符串类型,但是这个SQL里面没有加上引号,所以像这种情况下,索引是无效的。
2.分页查询优化
select * from orderwhere oid=100 limit 100000,5000,这种普通limit M,N的翻页写法,在越往后翻页的过程中速度越慢,原因mysql会读取表中的前M+N条数据,M越大,性能就越差。像这种SQL如果只是平时查询看看记录,感觉不到异常,就算稍微慢点,也忍了,但是在我刚才说的业务场景里面,也会导致慢SQL查询积累。优化写法:select t1.* from order t1,(select id from order oid=100 limit 100000,5000) t2 where t1.id=t2.id,这种效率会高很好。
3.分表
虽然做了上面的优化,执行效率比之前高了很多台阶,但是单表达的压力依然存在。订单表当时没有做分表,尽管目前的条件没有用分片集群,但是为解决燃眉之需也需要做物理分表(随着投放出去的摇摇车越来越多,当时每天订单大约1万到2万)。
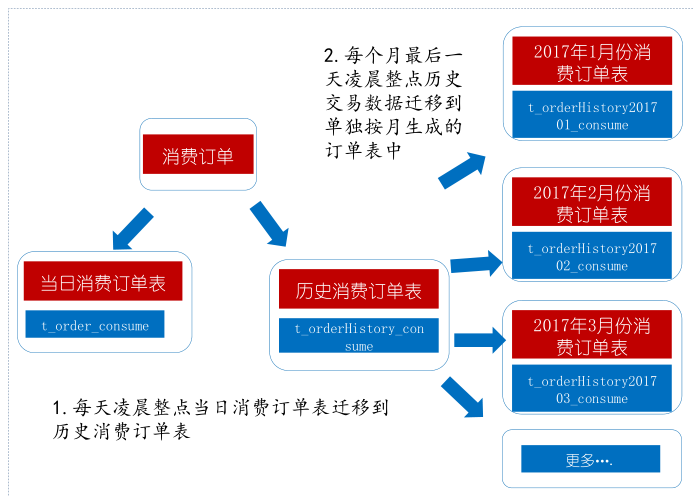
SQL优化是一个长期的过程,最好是结合具体业务场景来做优化效率会更好一些,后面我会继续罗列在这个项目实战中出现的一些关于SQL的坑和做的相关优化。
以上是关于我的物联网项目前期线上事故的主要内容,如果未能解决你的问题,请参考以下文章