- 参考资料
- 0 Figures First
- 1 LeNet5
- 2 Dan Ciresan Net
- 3 AlexNet
- 4 VGG19
- 5 Network-in-network(NiN)
- 6 Inception V1-V3
参考资料
0 Figures First
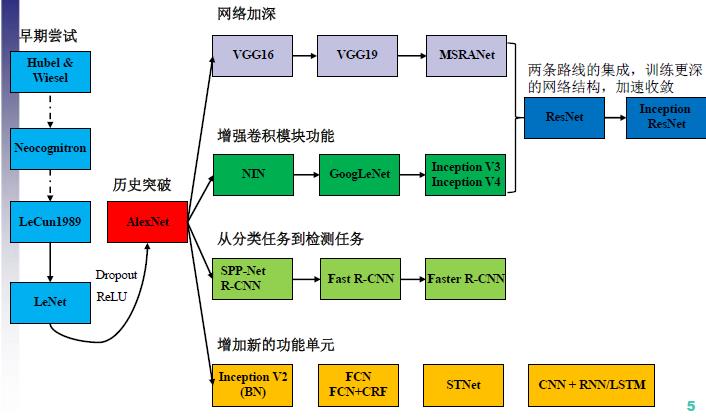
- CNN架构演变
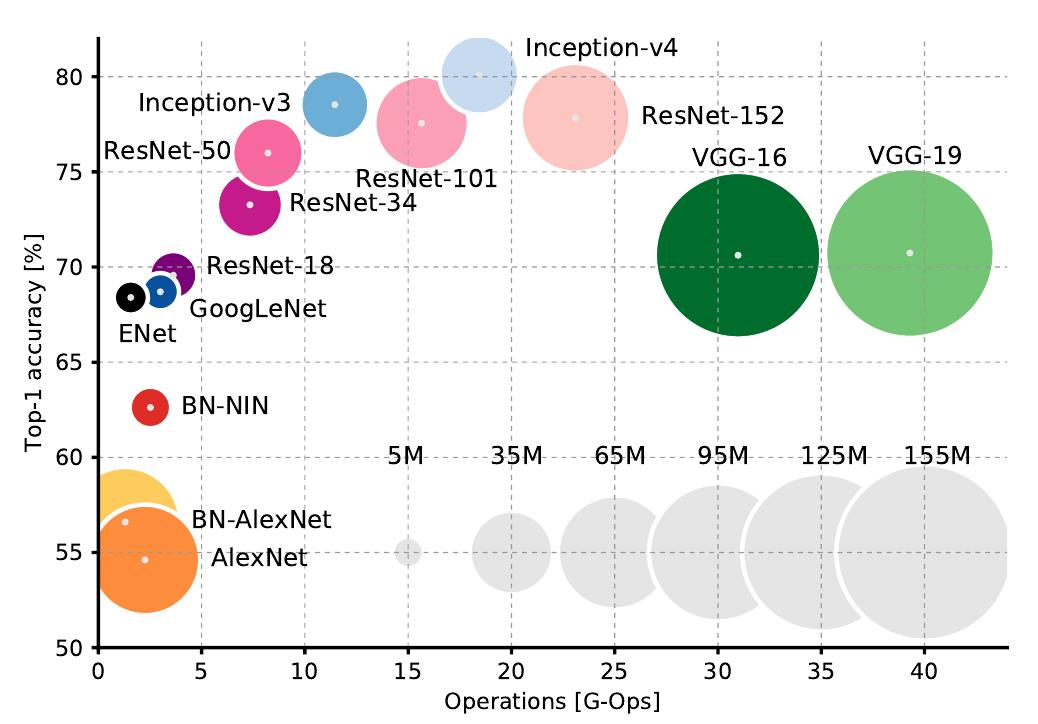
搬运一张图,总结的很好。 - Top1 vs operations, size ∝ parameters
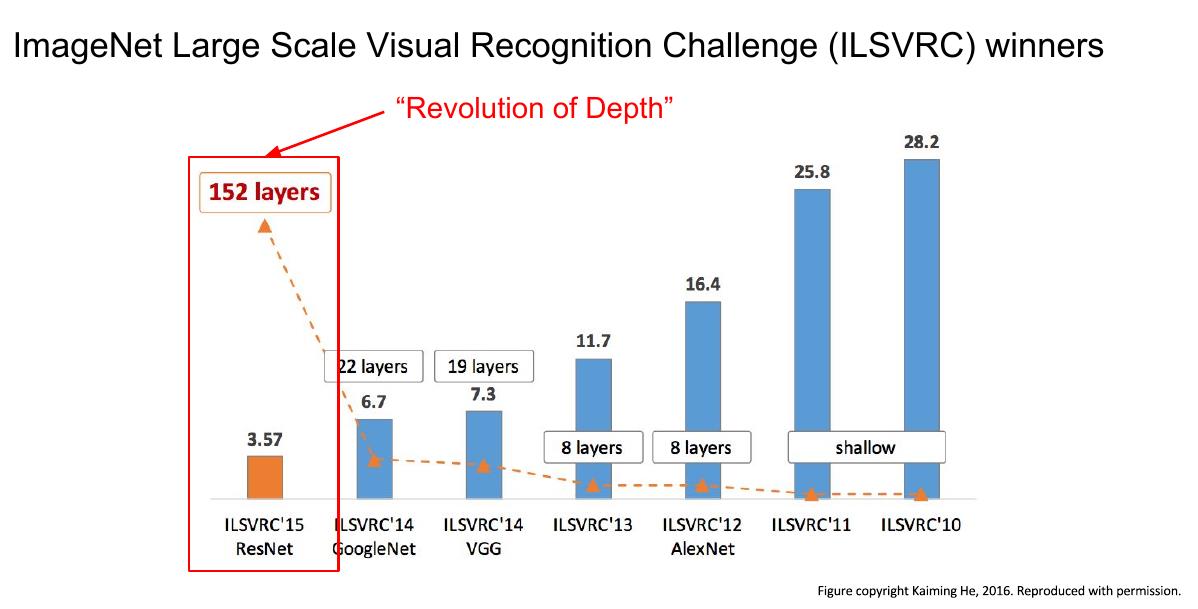
上图是精度(Top1)与运算量的比较,详细分析在这里。 - ImageNet比赛获奖网络
这是何凯明大神的成果,参考文献还没找到。
1 LeNet5
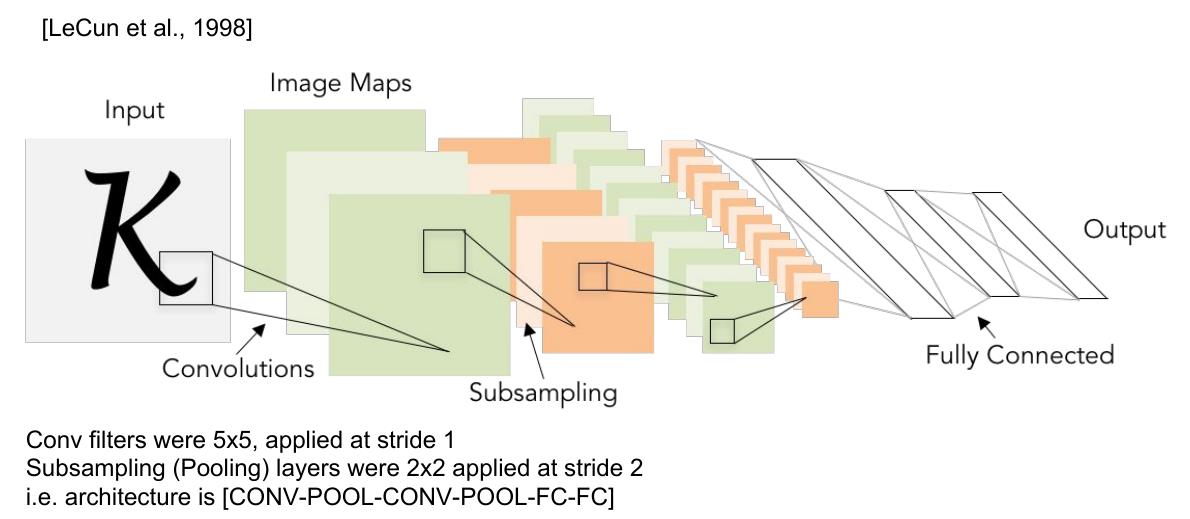
第一个卷积神经网络,1994年由Yann LeCun基于1988年以来的工作提出,并命名为LeNet5。
贡献
- 在神经网络中引入卷积层
- 引入下采样
卷积+池化(下采样)+非线性激活的组合是CNN的典型特征- 使用MPL作为分类器
虽然是一个只有5层的小网络,但却是当之无愧的开创性工作。卷积使得神经网络可以共享权值,一方面减少了参数,另一方面可以学习图像不同位置的局部特征.
引入下采样是因为图像特征的相对位置比其精确位置更重要,而后来的网络更多采用最大池化。
2 Dan Ciresan Net
2010年,Dan Claudiu Ciresan和Jurgen Schmidhuber实现了第一个GPU神经网络。
3 AlexNet
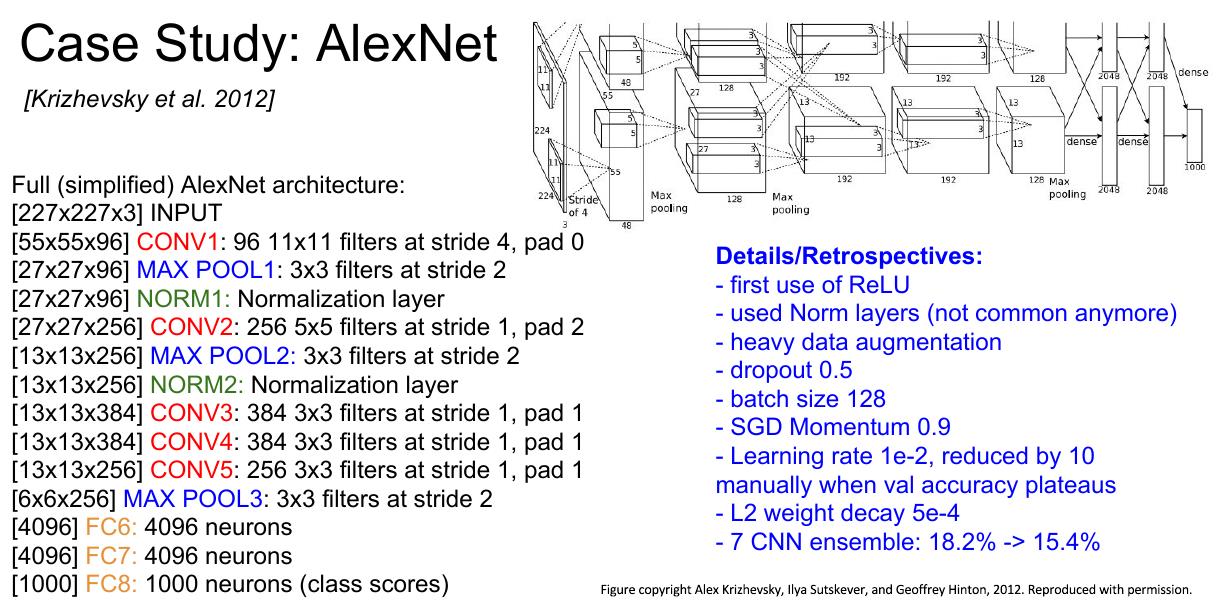
AlexNet是2012年ImageNet比赛的冠军,第一个基于CNN的ImageNet冠军,网络比LeNet5更深(8层)。
贡献
- 使用ReLU作为非线性激活函数
- 数据扩增
- 使用最大池化
- 使用dropout避免过拟合
- 使用GPU减少训练时间
从直觉来说,最大池化获得的是每个池化位置的最具代表性特征,最后输出整个图像各个区域的典型特征,这样做可以在避免重复的同时保留足够的特征用于分类,所以池化可以避免过拟合。
图像分类的样本都是将分类对象置于中心的,虽然池化考虑到了特征的相对空间关系,但是物体有太大的平移或旋转时分类效果难以保证,所以有时候训练时需要做数据扩增。在物体检测和分割等任务中还需要设计特殊的网络结构来探测不同位置的感兴趣对象。
从AlexNet之后,深度学习就变成了一种叫做"解决任务的更大规模的神经网络"的技术。^_~
4 VGG19

VGG是2014年的ImageNet分类的亚军,物体检测冠军,使用了更小的卷积核(3x3),并且连续多层组合使用。
贡献
- 更深
- 连续多个3x3的卷积层
VGG论文的一个主要结论就是深度的增加有益于精度的提升,这个结论堪称经典。
连续3个3x3的卷积层(步长1)能获得和一个7x7的卷积层等效的感知域(receptive fields),而深度的增加在增加网络的非线性时减少了参数(3*3^2 vs 7^2)。从VGG之后,大家都倾向于使用连续多个更小的卷积层,甚至分解卷积核(Depthwise Convolution)。
但是,VGG简单的堆叠卷积层,而且卷积核太深(最多达512),特征太多,导致其参数猛增,搜索空间太大,正则化困难,因而其精度也并不是最高的,在推理时也相当耗时,和GoogLeNet相比性价比十分之低。
5 Network-in-network(NiN)
NiN发表于13年底,它洞察到使用1x1卷积可以为卷积层的特征提供更强的组合能力,一个简单但是真的超赞的想法。
1x1卷积用于在空间上对卷积之后的特征进行组合,高效的利用了少量参数,将其共享到该特征的所有像素,最后得到更加power的特征。
6 Inception V1-V3
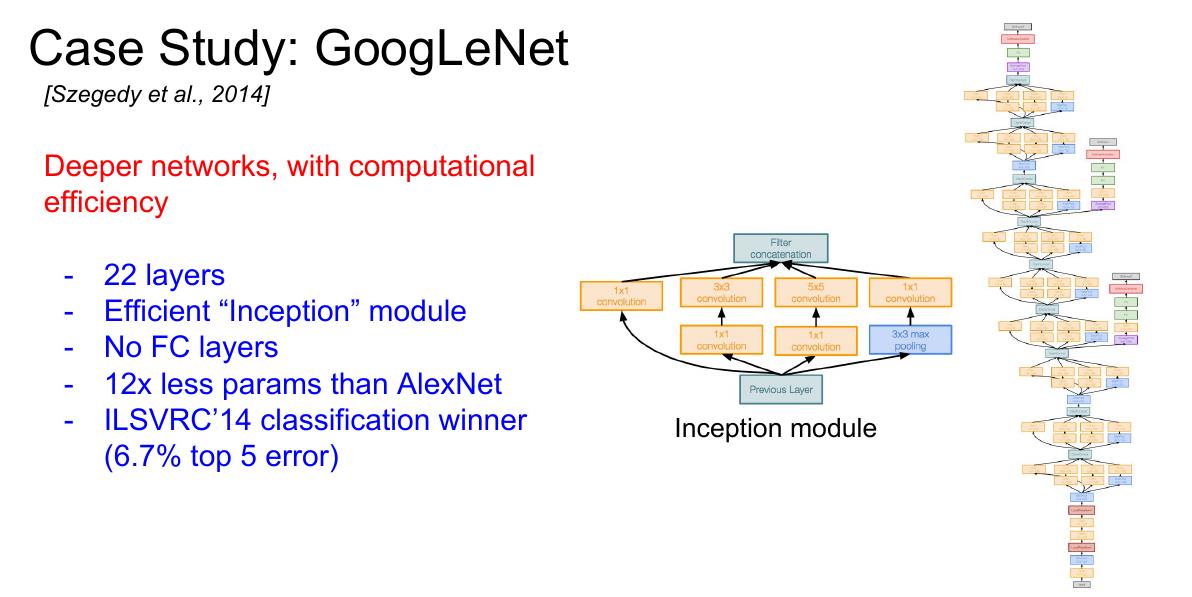
GoogLeNet是2014年的ImageNet图像分类的冠军,比VGG19多3层,而其参数却只有AlexNet的1/12,同时获得了当时state-of-the-art的结果。
贡献
- Inception模块
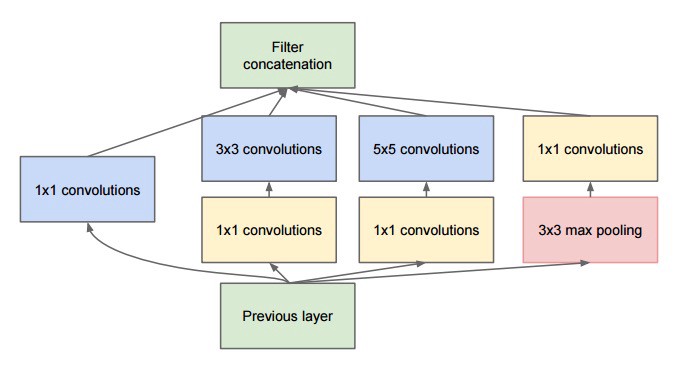
Inception模块使用1x1的卷积(bottleneck layer)减少了特征数量,同时,分类器部分只保留了必要的一个全连接层,极大的降低了运算数量。Inception模块是GoogLeNet以更深的网络和更高的计算效率取得更好的结果的主要原因。
此后,Inception模块不断改进,产生了Inception-2和Inception-3。 - Inception-v2
Inception-2使用了Batch Normalization。 - Inception-v3
Inception-3有两方面改进,一是像VGG一样,使用了连续的3x3卷积核代替更大的卷积核;另一方面进一步使用了Depthwise Convolution分解卷积。