Beautiful Soup中的find,find_all
Posted 做梦当财神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Beautiful Soup中的find,find_all相关的知识,希望对你有一定的参考价值。
1.一般来说,为了找到BeautifulSoup对象内任何第一个标签入口,使用find()方法。

以上代码是一个生态金字塔的简单展示,为了找到第一生产者,第一消费者或第二消费者,可以使用Beautiful Soup。
找到第一生产者:
生产者在第一个<url>标签里,因为生产者在整个html文档中第一个<url>标签中出现,所以可以使用find()方法找到第一生产者,在ecologicalpyramid.py
中写入下面一段代码,使用ecologicalpyramid.html文件创建BeautifulSoup对象。
from bs4 import BeautifulSoup with open(\'ecologicalpyramid.html\', \'r\') as ecological_pyramid: # ecological 生态系统 pyramid 金字塔 soup = BeautifulSoup(ecological_pyramid) producer_entries = soup.find(\'ul\') print(producer_entries.li.div.string)
输出结果:plants
2.find()
find函数:
find(name, attrs, recursive, text, **wargs) # recursive 递归的,循环的
这些参数相当于过滤器一样可以进行筛选处理。不同的参数过滤可以应用到以下情况:
- 查找标签,基于name参数
- 查找文本,基于text参数
- 基于正则表达式的查找
- 查找标签的属性,基于attrs参数
- 基于函数的查找
通过标签查找:
可以传递任何标签的名字来查找到它第一次出现的地方。找到后,find函数返回一个BeautifulSoup的标签对象。
from bs4 import BeautifulSoup with open(\'ecologicalpyramid.html\', \'r\') as ecological_pyramid: soup = BeautifulSoup(ecological_pyramid, \'html\') producer_entries = soup.find(\'ul\') print(type(producer_entries))
输出结果: <class \'bs4.element.Tag\'>
通过文本查找:
直接字符串的话,查找的是标签。如果想要查找文本的话,则需要用到text参数。如下所示:
from bs4 import BeautifulSoup with open(\'ecologicalpyramid.html\', \'r\') as ecological_pyramid: soup = BeautifulSoup(ecological_pyramid, \'html\') producer_string = soup.find(text = \'plants\') print(plants_string)
输出:plants
通过正则表达式查找:
有以下html代码:
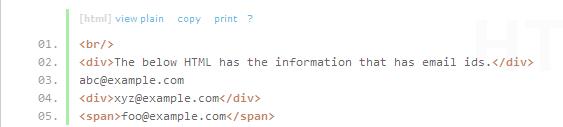
想找出第一个邮箱地址,但是第一个邮箱地址没有标签包含,所以通过其他方式很难找到。但是可以将邮箱地址进行正则表达式处理。
import re from bs4 import BeautifulSoup email_id_example = """<br/> <div>The below HTML has the information that has email ids.</div> abc@example.com <div>xyz@example.com</div> <span>foo@example.com</span> """ soup = BeautifulSoup(email_id_example) emailid_regexp = re.compile("\\w+@\\w+\\.\\w+") # regexp 表达式对象 first_email_id = soup.find(text=emailid_regexp) print(first_email_id)
输出结果:abc@example.com
通过标签属性进行查找:
上面html代码,其中第一个消费者在ul标签里面且id属性为priaryconsumer(priary consumer一次消费者,初级消费者)。
from bs4 import BeautifulSoup with open(\'ecologicalpyramid.html\', \'r\') as ecological_pyramid: soup = BeautifulSoup(eccological_pyramid, \'html\') primary_consumer = soup.find(id=\'primaryconsumers\') print(primary_consumer.li.div.string)
输出结果:deer
基于定制属性查找:
通过标签属性查找的方式适用大多数标签属性,包括id,style,title,但有 “-”,Class标签属性例外。
比如html5标签中的data-custom属性,如果我们这样
customattr = """<p data-custom=\'custom\'>custo attribute example</p> """ customsoup = BeautifulSoup(customattr, \'lxml\') customSoup.find(data-custom="custom")
那么则会报错。原因是在python中变量不能含有"-"这个字符,而我们传递的data-custom有这个字符。
解决办法是在attrs属性用字典进行传递参数。
using_attrs = customsoup.find(attrs={\'data-custom\':\'custom\'})
print(using_attrs)
基于css类的查找:
class是python的保留关键字,所以无法使用class这个关键字。
第一种方法:在attrs属性用字典进行传递参数
css_class = soup.find(attrs={\'class\':\'primaryconsumers\'})
print(css_class)
第二种方法:BeautifulSoup中的特别关键字参数class_。
css_class = soup.find(class_ = \'primaryconsumers\')
基于定义的函数进行查找:
可以传递函数到find()来基于函数定义的条件查找。函数必须返回True或False。
def is_secondary_consumers(tag): return tag.has_attr(\'id\') and tag.get(\'id\') == \'secondaryconsumers\'
secondary_consumer = soup.find(is_secondary_consumers) print(secondary_consumer.li.div.string)
输出:fox
将方法进行组合后进行查找:
可以用其中任何方法进行组合进行查找,比如同时基于标签名和id号。
3.find_all查找
find()查找第一个匹配结果出现的地方,find_all()找到所有匹配结果出现的地方。
查找所有3级消费者:
all_tertiaryconsumers = soup.find_all(class_ = \'tertiaryconsumerslist\') # tertiary第三的
其中all_tertiaryconsumers的类型是列表。
所以对其列表进行迭代,循环输出三级消费者的名字。
for tertiaryconsumer in all_tertiaryconsumers: print(tertiaryconsumer.div.string)
输出结果:
lion
tiger
find_all()的参数:
find_all(name, attrs, recursive, text, limit, **kwargs)
limit参数可以限制得到的结果的数目。
参照前面的邮件地址例子,得到所有邮件地址:
email_ids = soup.find_all(text=emailid_regexp) print(email_ids)
输出结果:[u\'abc@example.com\',u\'xyz@example.com\',u\'foo@example.com\']
使用limit参数:
email_ids_limited = soup.find_all(text=emailid_regexp, limit = 2) print(email_ids_limited)
限制得到两个结果,所以输出结果:[u\'abc@example.com\',u\'xyz@example.com\']
可以向find函数传递True或False参数,如果传递True给find_all(),则返回soup对象的所有标签。对于find()来说,则返回soup对象的第一个标签。
all_texts = soup.find_all(text=True) print(all_texts)
输出结果:

同样,可以在传递text参数时传递一个字符串列表,那么find_all()会找到挨个在列表中定义过的字符串。
all_texts_in_list = soup.find_all(text=[\'plants\', \'algae\']) print(all_texts_in_list)
输出结果:
[u\'plants\', u\'alage\']
这个同样适用于查找标签,标签属性,定制属性和CSS类。如:
div_li_tags = soup.find_all([\'div\', \'li\'])
并且find()和find_all()都会查找一个对象所有后辈们,不过可以通过recursive参数控制。(recursive回归,递归)
如果recursive=False,只会找到该对象的最近后代。
通过标签之间的关系进行查找
查找父标签
通过find_parents()或find_parent()。它们之间的不同类似于find()和find_all()的区别。
find_parents()返回全部的相匹配的父标签,而find_parent()返回最近一个父标签。适用于find()的方法同样适用于这两个方法。
在第一消费者例子中,可以找到离Primaryconsumer最近的ul父标签。
primaryconsumers = soup.find_all(class_ = \'primaryconsumerlist\') primaryconsumer = primaryconsumers[0] parent_ul = primaryconsumer.find_parents(\'ul\') print(parent_ul)
一个简单的找到一个标签的父标签的方法是使用find_parent()却不带任何参数。
immediateprimary_consumer_parent = primary_consumer.find_parent()
查找同胞
标签在同一个等级,这些标签是同胞关系,比如参照上面金子塔例子,所有的ul标签就是同胞的关系。上面的ul标签下的producers,primaryconsumers,,
secondaryconsumers,teriaryconsumers就是同胞关系。
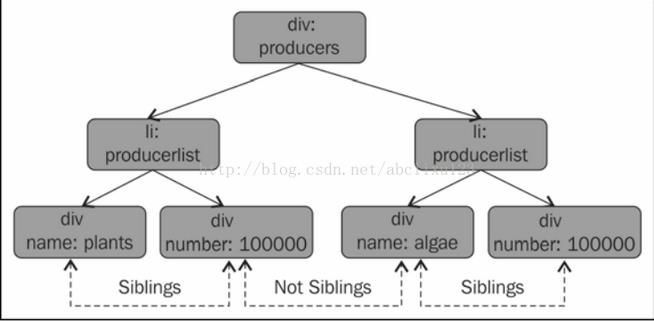
div下的plants和algae不是同胞关系,但是plants和临近的number是同胞关系。
Beautiful Soup自带查找同胞的方法。
比如find_next_siblings()和find_next_sibling()查找对象下面的同胞。(sibling兄弟姐妹)
producers = soup.find(id = \'producers\') next_siblings = producers.find_next_siblings() print(next_siblings)
输出结果将会输出与之临近的下面的所有同胞html代码。
查找下一个
对每一个标签来说,下一个元素可能会是定位字符串,标签对象或者其他BeautifulSoup对象,我们定义下一个元素为当前元素最靠近的元素 。
这不用于同胞定义,我们有方法可以找到我们想要标签的下一个其他元素对象。find_all_next()找到与当前元素最靠近的所有对象。而find_next()找到离当前元素最接近的对象。
比如,找到在第一个div标签后的所有li标签
first_div = soup.div all_li_tags = first_div.find_all_next(\'li\')

查找上一个
与查找下一个相反的是查找前一个,用find_previous()和find_all_previous()。
以上是关于Beautiful Soup中的find,find_all的主要内容,如果未能解决你的问题,请参考以下文章