scrapy爬虫框架
Posted 宁信
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy爬虫框架相关的知识,希望对你有一定的参考价值。
Scrapy不是一个函数功能库,而是一个爬虫框架。
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
1.scrapy爬虫框架结构
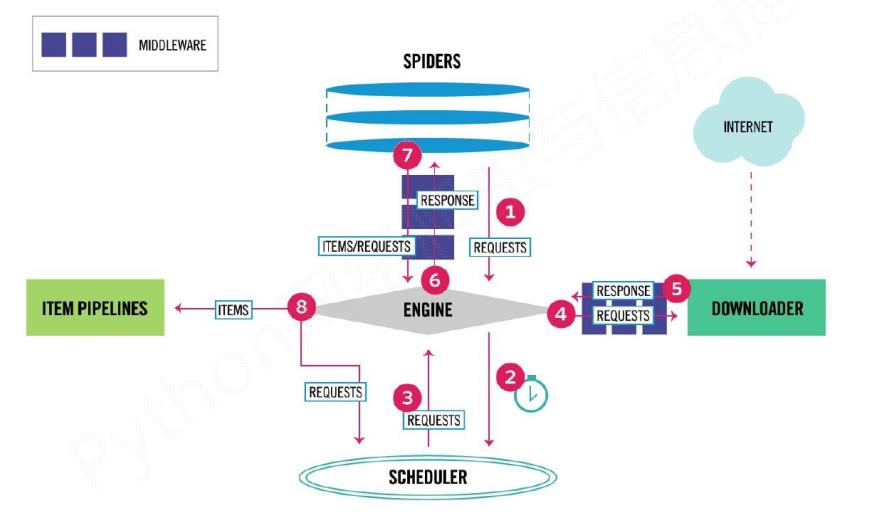
数据流向步骤1:
1 Engine从Spider处获得爬取请求(Request)
2 Engine将爬取请求转发给Scheduler,用于调度
数据流向步骤2:
3 Engine从Scheduler处获得下一个要爬取的请求
4 Engine将爬取请求通过中间件发送给Downloader
5 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6 Engine将收到的响应通过中间件发送给Spider处理
数据流向步骤3:
7 Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8 Engine将爬取项发送给Item Pipeline(框架出口)
9 Engine将爬取请求发送给Scheduler
Engine控制各模块数据流,不间断从Scheduler处
获得爬取请求,直至请求为空
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
engine、scheduler、Downloader是已有实现,spiders和pipline需要编写。
Engine
(1) 控制所有模块之间的数据流
(2) 根据条件触发事件
Downloader
根据请求下载网页
Scheduler
对所有爬取请求进行调度管理
Downloader Middleware
目的:实施Engine、 Scheduler和Downloader之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
用户可以编写配置代码
Spider
(1) 解析Downloader返回的响应(Response)
(2) 产生爬取项(scraped item)
(3) 产生额外的爬取请求(Request)
用户可以编写配置代码
Item Pipelines
(1) 以流水线方式处理Spider产生的爬取项
(2) 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
(3) 可能操作包括:清理、检验和查重爬取项中的html数据、将数据存储到数据库
需要用户编写配置代码
Spider Middleware
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
2.scrapy常用命令
startproject 创建一个新工程 scrapy startproject <name> [dir] genspider 创建一个爬虫 scrapy genspider [options] <name> <domain> settings 获得爬虫配置信息 scrapy settings [options] crawl 运行一个爬虫 scrapy crawl <spider> list 列出工程中所有爬虫 scrapy list shell 启动URL调试命令行 scrapy shell [url]
3.创建scrapy
应用Scrapy爬虫框架主要是编写配置型代码
步骤1:建立一个Scrapy爬虫工程
选取一个目录(D:\\,然后执行如下命令
scrapy startproject <name> [dir]
生成的目录结构



# -*- coding: utf-8 -*- import scrapy import sys import io from scrapy.http import Request from scrapy.selector import Selector, HtmlXPathSelector from ..items import ChoutiItem sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=\'gb18030\') class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com"] start_urls = [\'http://dig.chouti.com/\'] visited_urls =set() # def start_requests(self): # for url in self.start_urls: # yield Request(url,callback=self.parse) def parse(self, response): # content = str(response.body,encoding=\'utf-8\') # 找到文档中所有A标签 # hxs = Selector(response=response).xpath(\'//a\') # 标签对象列表 # for i in hxs: # print(i) # 标签对象 # 对象转换为字符串 # hxs = Selector(response=response).xpath(\'//div[@id="content-list"]/div[@class="item"]\').extract() # 标签对象列表 # hxs = Selector(response=response).xpath(\'//div[@id="content-list"]/div[@class="item"]\') # 标签对象列表 # for obj in hxs: # a = obj.xpath(\'.//a[@class="show-content"]/text()\').extract_first() # print(a.strip()) # 选择器: """ // 表示子孙中 .// 当前对象的子孙中 / 儿子 /div 儿子中的div标签 /div[@id="i1"] 儿子中的div标签且id=i1 /div[@id="i1"] 儿子中的div标签且id=i1 obj.extract() # 列表中的每一个对象转换字符串 =》 [] obj.extract_first() # 列表中的每一个对象转换字符串 => 列表第一个元素 //div/text() 获取某个标签的文本 """ # 获取当前页的所有页码 # hxs = Selector(response=response).xpath(\'//div[@id="dig_lcpage"]//a/text()\') # hxs0 = Selector(response=response).xpath(\'//div[@id="dig_lcpage"]//a/@href\').extract() # for item in hxs0: # if item in self.visited_urls: # print(\'已经存在\', item) # else: # self.visited_urls.add(item) # print(item) # hxs2 = Selector(response=response).xpath(\'//div[@id="dig_lcpage"]//a/@href\').extract() # hxs2 = Selector(response=response).xpath(\'//a[starts-with(@href, "/all/hot/recent/")]/@href\').extract() # hxs2 = Selector(response=response).xpath(\'//a[re:test(@href, "/all/hot/recent/\\d+")]/@href\').extract() # for url in hxs2: # md5_url = self.md5(url) # if md5_url in self.visited_urls: # pass # # print(\'已经存在\', url) # else: # self.visited_urls.add(md5_url) # print(url) # url = "http://dig.chouti.com%s" %url # # 将新要访问的url添加到调度器 # yield Request(url=url,callback=self.parse) # # a/@href 获取属性 # # //a[starts-with(@href, "/all/hot/recent/")]/@href\' 已xx开始 # # //a[re:test(@href, "/all/hot/recent/\\d+")] 正则 # # yield Request(url=url,callback=self.parse) # 将新要访问的url添加到调度器 # # 重写start_requests,指定最开始处理请求的方法 # # # def show(self,response): # # print(response.text) # # def md5(self, url): # import hashlib # obj = hashlib.md5() # obj.update(bytes(url, encoding=\'utf-8\')) # return obj.hexdigest() # hxs = HtmlXPathSelector(response) # response hxs1 = Selector(response=response).xpath(\'//div[@id="content-list"]/div[@class="item"]\') # 标签对象列表 for obj in hxs1: title = obj.xpath(\'.//a[@class="show-content color-chag"]/text()\').extract_first().strip() href = obj.xpath(\'.//a[@class="show-content color-chag"]/@href\').extract_first().strip() # print(title) # print(href) item_obj = ChoutiItem(title=title,href=href) # 将item对象传递给pipeline yield item_obj
parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
配置产生的spider爬虫:(1)初始URL地址 (2)获取页面后的解析方式
yield 生成器
生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值,生成器是一个不断产生值的函数
生成器相比一次列出所有内容的优势:
1)更节省存储空间
2)响应更迅速
3)使用更灵活
4.scrapy数据类型
request类:
class scrapy.http.Request()
Request对象表示一个HTTP请求
由Spider生成,由Downloader执行
属性或方法 说明 .url Request对应的请求URL地址 .method 对应的请求方法,\'GET\' \'POST\'等 .headers 字典类型风格的请求头 .body 请求内容主体,字符串类型 .meta 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 .copy() 复制该请求
response类:
class scrapy.http.Response()
Response对象表示一个HTTP响应
由Downloader生成,由Spider处理
属性或方法 说明
.url Response对应的URL地址
.status HTTP状态码,默认是200
.headers Response对应的头部信息
.body Response对应的内容信息,字符串类型
.flags 一组标记
.request 产生Response类型对应的Request对象
.copy() 复制该响应
Item类
class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
Scrapy爬虫支持多种HTML信息爬取方法:
• Beautiful Soup
• lxml
• re
• XPath Selector
• CSS Selector
settings.py配置并发连接选项
选项 说明
CONCURRENT_REQUESTS Downloader最大并发请求下载数量,默认32
CONCURRENT_ITEMS Item Pipeline最大并发ITEM处理数量,默认100
CONCURRENT_REQUESTS_PER_DOMAIN 每个目标域名最大的并发请求数量,默认8
CONCURRENT_REQUESTS_PER_IP 每个目标IP最大的并发请求数量,默认0,非0有效
5.格式化处理
import scrapy import sys import io from scrapy.http import Request from scrapy.selector import Selector, HtmlXPathSelector from ..items import ChoutiItem sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=\'gb18030\') class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com"] start_urls = [\'http://dig.chouti.com/\'] visited_urls =set() hxs1 = Selector(response=response).xpath(\'//div[@id="content-list"]/div[@class="item"]\') # 标签对象列表 for obj in hxs1: title = obj.xpath(\'.//a[@class="show-content"]/text()\').extract_first().strip() href = obj.xpath(\'.//a[@class="show-content"]/@href\').extract_first().strip() item_obj = ChoutiItem(title=title,href=href) # 将item对象传递给pipeline yield item_obj
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ChoutiItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() href = scrapy.Field()
class Day96Pipeline(object): def process_item(self, item, spider): print(spider, item) # if spider.name == \'chouti\' tpl = "%s\\n%s\\n\\n" %(item[\'title\'],item[\'href\']) f = open(\'news.json\', \'a\') f.write(tpl) f.close()
ITEM_PIPELINES = { # \'day96.pipelines.Day96Pipeline\': 300, # \'day96.pipelines.Day96Pipeline\': 300, \'day96.pipelines.Day96Pipeline\': 300, }
自定义pipeline
from scrapy.exceptions import DropItem class Day96Pipeline(object): def __init__(self,conn_str): self.conn_str = conn_str @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ conn_str = crawler.settings.get(\'DB\') return cls(conn_str) def open_spider(self,spider): """ 爬虫开始执行时,调用 :param spider: :return: """ self.conn = open(self.conn_str, \'a\') def close_spider(self,spider): """ 爬虫关闭时,被调用 :param spider: :return: """ self.conn.close() def process_item(self, item, spider): """ 每当数据需要持久化时,就会被调用 :param item: :param spider: :return: """ # if spider.name == \'chouti\' tpl = "%s\\n%s\\n\\n" %(item[\'title\'],item[\'href\']) self.conn.write(tpl) # 交给下一个pipeline处理 return item # 丢弃item,不交给 # raise DropItem()
6.cookies
from scrapy.http.cookies import CookieJar cookie_obj = CookieJar() cookie_obj.extract_cookies(response,response.request) print(cookie_obj._cookies)
# -*- coding: utf-8 -*- import scrapy import sys import io from scrapy.http import Request from scrapy.selector import Selector, HtmlXPathSelector from ..items import ChoutiItem sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=\'gb18030\') from scrapy.http.cookies import CookieJar class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com",] start_urls = [\'http://dig.chouti.com/\'] cookie_dict = None def parse(self, response): print("spider.reponse",response) cookie_obj = CookieJar() cookie_obj.extract_cookies(response,response.request) self.cookie_dict = cookie_obj._cookies # 带上用户名密码+cookie yield Request( url="http://dig.chouti.com/login", method=\'POST\', body = "phone=8615131255089&password=woshiniba&oneMonth=1", headers={\'Content-Type\': "application/x-www-form-urlencoded; charset=UTF-8"}, cookies=cookie_obj._cookies, callback=self.check_login ) def check_login(self,response): print(response.text) yield Request(url="http://dig.chouti.com/",callback=self.good) def good(self,response): id_list = Selector(response=response).xpath(\'//div[@share-linkid]/@share-linkid\').extract() for nid in id_list: print(nid) url = "http://dig.chouti.com/link/vote?linksId=%s" % nid yield Request( url=url, method="POST", cookies=self.cookie_dict, callback=self.show ) page_urls = Selector(response=response).xpath(\'//div[@id="dig_lcpage"]//a/@href\').extract() for page in page_urls: url = "http://dig.chouti.com%s" % page yield Request(url=url,callback=self.good) def show(self,response): print(response.text)
7.自定义扩展