thrift基础知识
Posted andywu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了thrift基础知识相关的知识,希望对你有一定的参考价值。
1. 架构图
图 1. 架构图
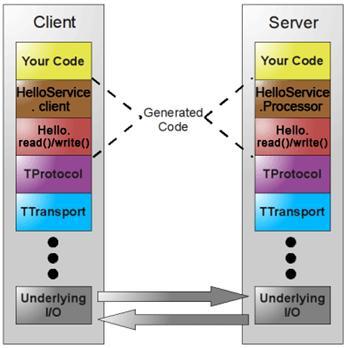
如图所示,图中黄色部分是用户实现的业务逻辑,褐色部分是根据 Thrift 定义的服务接口描述文件生成的客户端和服务器端代码框架,红色部分是根据 Thrift 文件生成代码实现数据的读写操作。红色部分以下是 Thrift 的传输体系、协议以及底层 I/O 通信,使用 Thrift 可以很方便的定义一个服务并且选择不同的传输协议和传输层而不用重新生成代码。
图 2. Server 端启动、服务时序图(查看大图)
{kind=link}
该图所示是 HelloServiceServer启动的过程以及服务被客户端调用时,服务器的响应过程。从图中我们可以看到,程序调用了 TThreadPoolServer 的 serve 方法后,server 进入阻塞监听状态,其阻塞在 TServerSocket 的 accept 方法上。当接收到来自客户端的消息后,服务器发起一个新线程处理这个消息请求,原线程再次进入阻塞状态。在新线程中,服务器通过 TBinaryProtocol 协议读取消息内容,调用 HelloServiceImpl 的 helloVoid 方法,并将结果写入 helloVoid_result 中传回客户端。
图 3. Client 端调用服务时序图(查看大图)
{kind=link}
该图所示是 HelloServiceClient 调用服务的过程以及接收到服务器端的返回值后处理结果的过程。从图中我们可以看到,程序调用了 Hello.Client 的 helloVoid 方法,在 helloVoid 方法中,通过 send_helloVoid 方法发送对服务的调用请求,通过 recv_helloVoid 方法接收服务处理请求后返回的结果。
2.thrift Type
base type
- bool: 布尔值 (true or false), one byte
- byte: 有符号字节
- i16: 16位有符号整型
- i32: 32位有符号整型
- i64: 64位有符号整型
- double: 64位浮点型
- string: 编码无关的文本
struct
- struct不能继承,但是可以嵌套,不能嵌套自己。
- 其成员都是有明确类型
- 成员是被正整数编号过的,其中的编号是不能重复的,这个是为了在传输过程中编码使用。
- 成员分割符可以是逗号(,)或是分号(;),而且可以混用,但是为了清晰期间,建议在定义中只使用一种,比如C++学习者可以就使用分号(;)。
- 字段会有optional和required之分,但是如果不指定则为无类型—可以不填充该值,但是在序列化传输的时候也会序列化进去,optional是不填充则部序列化,required是必须填充也必须序列化。
- 每个字段可以设置默认值
- 同一文件可以定义多个struct,也可以定义在不同的文件,进行include引入。
struct demo
Containers
- list<t>: 元素类型为t的有序表,容许元素重复。对应c++的vector,java的ArrayList或者其他语言的数组(官方文档说是ordered list不知道如何理解?排序的?c++的vector不排序
- set<t>:元素类型为t的无序表,不容许元素重复。对应c++中的set,java中的HashSet,python中的set,php中没有set,则转换为list类型了
- map<t,t>: 键类型为t,值类型为t的kv对,键不容许重复。对用c++中的map, Java的HashMap, PHP 对应 array, Python/Ruby 的dictionary。
Container demo
Enum
- 编译器默认从0开始赋值
- 可以赋予某个常量某个整数
- 允许常量是十六进制整数
- 末尾没有分号
- 给常量赋缺省值时,使用常量的全称
Enumeration demo
Exception
Exception demo
Services
services demo
Namespace
Namespace demo
Includes
Include demo
3.协议
- 传输层
下面内容转自 https://www.cnblogs.com/exceptioneye/p/4945073.html
一、Thrift介绍
Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎。其允许你定义一个简单的定义文件中的数据类型和服务接口。以作为输入文件,编译器生成代码用来方便地生成RPC客户端和服务器通信的无缝跨编程语言。
二、Thrift基础架构
Thrift是一个客户端和服务端的架构体系,数据通过socket传输;
具有自己内部定义的传输协议规范(TProtocol)和传输数据标准(TTransports);
通过IDL脚本对传输数据的数据结构(struct) 和传输数据的业务逻辑(service)根据不同的运行环境快速的构建相应的代码;
通过自己内部的序列化机制对传输的数据进行简化和压缩提高高并发、 大型系统中数据交互的性能。
三、Thrift网络服务模型
Thrif 提供网络模型:单线程、多线程、事件驱动。从另一个角度划分为:阻塞服务模型、非阻塞服务模型。
- 阻塞服务
TSimpleServer
TThreadPoolServer
- 非阻塞服务模型
TNonblockingServer
THsHaServer
TThreadedSelectorServer
1、TSimpleServer
TSimpleServer实现是非常的简单,循环监听新请求的到来并完成对请求的处理,是个单线程阻塞模型。由于是一次只能接收和处理一个socket连接,效率比较低,在实际开发过程中很少用到它。
2、TThreadPoolServer
ThreadPoolServer为解决了TSimpleServer不支持并发和多连接的问题, 引入了线程池。但仍然是多线程阻塞模式即实现的模型是One Thread Per Connection。
线程池采用能线程数可伸缩的模式,线程池中的队列采用同步队列(SynchronousQueue)。
ThreadPoolServer拆分了监听线程(accept)和处理客户端连接的工作线程(worker), 监听线程每接到一个客户端, 就投给线程池去处理。

import org.apache.thrift.TException;
import org.apache.thrift.TProcessor;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.server.TServer;
import org.apache.thrift.server.TThreadPoolServer;
import org.apache.thrift.transport.TServerSocket;
/**
* 注册服务端
* 线程池服务模型,使用标准的阻塞式IO,预先创建一组线程处理请求
*/
public class ThriftTThreadPoolServer {
// 注册端口
public static final int SERVER_PORT = 8080;
public static void main(String[] args) throws TException {
TProcessor tprocessor = new HelloWorld.Processor<HelloWorld.Iface>(new HelloWorldImpl());
// 阻塞IO
TServerSocket serverTransport = new TServerSocket(SERVER_PORT);
// 多线程服务模型
TThreadPoolServer.Args tArgs = new TThreadPoolServer.Args(serverTransport);
tArgs.processor(tprocessor);
// 客户端协议要一致
tArgs.protocolFactory(new TBinaryProtocol.Factory());
// 线程池服务模型,使用标准的阻塞式IO,预先创建一组线程处理请求。
TServer server = new TThreadPoolServer(tArgs);
System.out.println("Hello TThreadPoolServer....");
server.serve(); // 启动服务
}
}
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
/**
* 客户端调用
* 阻塞
*/
public class BlockClient {
public static final String SERVER_IP = "127.0.0.1";
public static final int SERVER_PORT = 8080;
public static final int TIMEOUT = 30000;
public static void main(String[] args) throws TException {
// 设置传输通道
TTransport transport = new TSocket(SERVER_IP, SERVER_PORT, TIMEOUT);
// 协议要和服务端一致
// 使用二进制协议
TProtocol protocol = new TBinaryProtocol(transport);
// 创建Client
HelloWorld.Client client = new HelloWorld.Client(protocol);
transport.open();
String result = client.sayHello("thrift");
System.out.println("result : " + result);
// 关闭资源
transport.close();
}
}
TThreadPoolServer模式优点:
线程池模式中,数据读取和业务处理都交由线程池完成,主线程只负责监听新连接,因此在并发量较大时新连接也能够被及时接受。线程池模式比较适合服务器端能预知最多有多少个客户端并发的情况,这时每个请求都能被业务线程池及时处理,性能也非常高。
TThreadPoolServer模式缺点:
线程池模式的处理能力受限于线程池的工作能力,当并发请求数大于线程池中的线程数时,新请求也只能排队等待。
3、TNonblockingServer
TNonblockingServer采用单线程非阻塞(NIO)的模式, 借助Channel/Selector机制, 采用IO事件模型来处理。所有的socket都被注册到selector中,在一个线程中通过seletor循环监控所有的socket,每次selector结束时,处理所有的处于就绪状态的socket,对于有数据到来的socket进行数据读取操作,对于有数据发送的socket则进行数据发送,对于监听socket则产生一个新业务socket并将其注册到selector中。
private void select() {
try {
selector.select(); // wait for io events.
// process the io events we received
Iterator<SelectionKey> selectedKeys = selector.selectedKeys().iterator();
while (!stopped_ && selectedKeys.hasNext()) {
SelectionKey key = selectedKeys.next();
selectedKeys.remove();
if (key.isAcceptable()) {
handleAccept(); // deal with accept
} else if (key.isReadable()) {
handleRead(key); // deal with reads
} else if (key.isWritable()) {
handleWrite(key); // deal with writes
}
}
} catch (IOException e) {
}
}
select代码里对accept/read/write等IO事件进行监控和处理, 唯一可惜的这个单线程处理. 当遇到handler里有阻塞的操作时, 会导致整个服务被阻塞住。
import org.apache.thrift.TException;
import org.apache.thrift.TProcessor;
import org.apache.thrift.protocol.TCompactProtocol;
import org.apache.thrift.server.TNonblockingServer;
import org.apache.thrift.server.TServer;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TNonblockingServerSocket;
/**
* 注册服务端
* 使用非阻塞式IO,服务端和客户端需要指定 TFramedTransport 数据传输的方式
*/
public class ThriftTNonblockingServer {
// 注册端口
public static final int SERVER_PORT = 8080;
public static void main(String[] args) throws TException {
// 处理器
TProcessor tprocessor = new HelloWorld.Processor<HelloWorld.Iface>(new HelloWorldImpl());
// 传输通道 - 非阻塞方式
TNonblockingServerSocket serverTransport = new TNonblockingServerSocket(SERVER_PORT);
// 异步IO,需要使用TFramedTransport,它将分块缓存读取。
TNonblockingServer.Args tArgs = new TNonblockingServer.Args(serverTransport);
tArgs.processor(tprocessor);
tArgs.transportFactory(new TFramedTransport.Factory());
// 使用高密度二进制协议
tArgs.protocolFactory(new TCompactProtocol.Factory());
// 使用非阻塞式IO,服务端和客户端需要指定TFramedTransport数据传输的方式
TServer server = new TNonblockingServer(tArgs);
System.out.println("Hello TNonblockingServer....");
server.serve(); // 启动服务
}
}
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TCompactProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
/**
* 客户端调用
* 非阻塞
*/
public class NonblockingClient {
public static final String SERVER_IP = "127.0.0.1";
public static final int SERVER_PORT = 8080;
public static final int TIMEOUT = 30000;
public static void main(String[] args) throws TException {
// 设置传输通道,对于非阻塞服务,需要使用TFramedTransport,它将数据分块发送
TTransport transport = new TFramedTransport(new TSocket(SERVER_IP, SERVER_PORT, TIMEOUT));
// 协议要和服务端一致
//HelloTNonblockingServer
// 使用高密度二进制协议
TProtocol protocol = new TCompactProtocol(transport);
// 使用二进制协议
//TProtocol protocol = new TBinaryProtocol(transport);
HelloWorld.Client client = new HelloWorld.Client(protocol);
transport.open();
String result = client.sayHello("jack");
System.out.println("result : " + result);
// 关闭资源
transport.close();
}
}
TNonblockingServer模式优点:
相比于TSimpleServer效率提升主要体现在IO多路复用上,TNonblockingServer采用非阻塞IO,同时监控多个socket的状态变化;
TNonblockingServer模式缺点:
TNonblockingServer模式在业务处理上还是采用单线程顺序来完成,在业务处理比较复杂、耗时的时候,例如某些接口函数需要读取数据库执行时间较长,此时该模式效率也不高,因为多个调用请求任务依然是顺序一个接一个执行。
4、THsHaServer
THsHaServer类是TNonblockingServer类的子类,为解决TNonblockingServer的缺点, THsHa引入了线程池去处理, 其模型把读写任务放到线程池去处理即多线程非阻塞模式。HsHa是: Half-sync/Half-async的处理模式, Half-aysnc是在处理IO事件上(accept/read/write io), Half-sync用于handler对rpc的同步处理上。因此可以认为THsHaServer半同步半异步。
THsHaServer的优点:
与TNonblockingServer模式相比,THsHaServer在完成数据读取之后,将业务处理过程交由一个线程池来完成,主线程直接返回进行下一次循环操作,效率大大提升;
THsHaServer的缺点:
主线程需要完成对所有socket的监听以及数据读写的工作,当并发请求数较大时,且发送数据量较多时,监听socket上新连接请求不能被及时接受。
5、TThreadedSelectorServer
TThreadedSelectorServer是大家广泛采用的服务模型,其多线程服务器端使用非堵塞式I/O模型,是对TNonblockingServer的扩充, 其分离了Accept和Read/Write的Selector线程, 同时引入Worker工作线程池。
(1)一个AcceptThread线程对象,专门用于处理监听socket上的新连接;
(2)若干个SelectorThread对象专门用于处理业务socket的网络I/O操作,所有网络数据的读写均是有这些线程来完成;
(3)一个负载均衡器SelectorThreadLoadBalancer对象,主要用于AcceptThread线程接收到一个新socket连接请求时,决定将这个新连接请求分配给哪个SelectorThread线程。
(4)一个ExecutorService类型的工作线程池,在SelectorThread线程中,监听到有业务socket中有调用请求过来,则将请求读取之后,交个ExecutorService线程池中的线程完成此次调用的具体执行
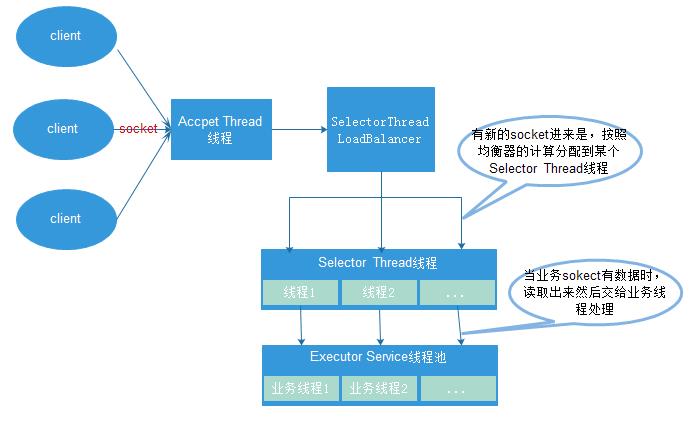
MainReactor就是Accept线程, 用于监听客户端连接, SubReactor采用IO事件线程(多个), 主要负责对所有客户端的IO读写事件进行处理. 而Worker工作线程主要用于处理每个rpc请求的handler回调处理(这部分是同步的)。因此其也是Half-Sync/Half-Async(半异步-半同步)的 。
TThreadedSelectorServer模式对于大部分应用场景性能都不会差,因为其有一个专门的线程AcceptThread用于处理新连接请求,因此能够及时响应大量并发连接请求;另外它将网络I/O操作分散到多个SelectorThread线程中来完成,因此能够快速对网络I/O进行读写操作,能够很好地应对网络I/O较多的情况。
import org.apache.thrift.TException;
import org.apache.thrift.TProcessor;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.server.TServer;
import org.apache.thrift.server.TThreadedSelectorServer;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TNonblockingServerSocket;
/**
* TFramedTransport 数据传输的方式
*/
public class ThriftTThreadedSelectorServer {
// 注册端口
public static final int SERVER_PORT = 8080;
public static void main(String[] args) throws TException {
TProcessor tprocessor = new HelloWorld.Processor<HelloWorld.Iface>(new HelloWorldImpl());
TThreadedSelectorServer.Args tArgs = new TThreadedSelectorServer.Args(serverTransport);
tArgs.processor(tprocessor);
tArgs.transportFactory(new TFramedTransport.Factory());
// 二进制协议
tArgs.protocolFactory(new TBinaryProtocol.Factory());
TServer server = new TThreadedSelectorServer(tArgs);
System.out.println("Hello TThreadedSelectorServer....");
server.serve(); // 启动服务
}
}
四、Thrift序列化机制
Thrift提供了可扩展序列化机制, 不但兼容性好而且压缩率高。
thrift 数据格式描述
thrift的向后兼容性(Version)借助属性标识(数字编号id + 属性类型type)来实现, 可以理解为在序列化后(属性数据存储由 field_name:field_value => id+type:field_value)
我们定义IDL文件形如
namespace java stu.thrift;
struct User {
1: required string name
2: required string address
}
是不是和我们使用序列化的数据xml/json有了很大的差别,那么我们来比较是常见的数据传输格式
| 数据传输格式 | 类型 | 优点 | 缺点 |
| Xml | 文本 |
1、良好的可读性 2、序列化的数据包含完整的结构 3、调整不同属性的顺序对序列化/反序列化不影响 |
1、数据传输量大 2、不支持二进制数据类型 |
| Json | 文本 |
1、良好的可读性 2、调整不同属性的顺序对序列化/反序列化不影响 |
1、丢弃了类型信息, 比如"price":100, 对price类型是int/double解析有二义性 2、不支持二进制数据类型 |
| Thrift | 二进制 | 高效 |
1、不宜读 2、向后兼容有一定的约定限制,采用id递增的方式标识并以optional修饰来添加 |
| Google Protobuf | 二进制 | 高效 |
1、不宜读 2、向后兼容有一定的约定限制 |
由于本人经验有限,文章中难免会有错误,请浏览文章的您指正或有不同的观点共同探讨!
以上是关于thrift基础知识的主要内容,如果未能解决你的问题,请参考以下文章