130242014023+李甘露美+第3次实验
Posted lglmlg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了130242014023+李甘露美+第3次实验相关的知识,希望对你有一定的参考价值。
一、实验目的
1.理解不同体系结构风格的具体内涵。
2.学习体系结构风格的具体实践。
二、实验环境
硬件: 联想笔记本电脑
软件:Java或任何一种自己熟悉的语言
三、实验内容
“上下文关键字”KWIC(Key Word in Context,文本中的关键字)检索系统接受有序的行集合:每一行是单词的有序集合;每一个单词又是字母的有序集合。通过重复地删除航中第一个单词,并把它插入行尾,每一行可以被“循环地移动”。KWIC检索系统以字母表的顺序输出一个所有行循环移动的列表。
四、实验步骤:
尝试用不同的策略实现这个系统。选择2-3种体系结构风格来实现。
在这里,我选择的是管道-过滤器风格和主程序-子程序风格。
一、管道/过滤器的风格
1、体系结构图:

其中实现表示管道,虚线表示系统输入/输出。
2、简述体系结构各部件的主要功能,实现思想。
这种风格的构件是过滤器,连接件是管道,各个过滤器之间通过管道进行连接。这种情况有4种过滤器:输入、移动、按字母排序、输出。每一个过滤器处理数据,并把它发送到下一个过滤器。控制是分布式的,只要有数据通过,过滤器就会处理。过滤器间的数据共享严格地局限于管道中传输的数据。
3.列出主要代码
1 //循环移动 2 /** 3 * 第一行数据到来后开始运作 4 * 把原始数据行循环移位,将原始行和新的移位后的行输出给下一模块 5 * @author 12know 6 * @version 1.0 2009年1月14日 7 */ 8 public class CircularShift extends Filter { 9 10 private static final String ignore = "a#$an#$and#$as#$is#$the#$of#$"; //一些噪音词汇 11 12 public CircularShift(Pipe input, Pipe output) { 13 super(input, output); 14 } 15 16 /** 17 * 18 */ 19 @Override 20 protected void transform() { 21 try { 22 CharArrayWriter writer= new CharArrayWriter(); //缓冲当前行 23 int c = -1; 24 while((c = input.read()) != -1) { 25 if(c == 10) { //回车,表示writer中取得了一行数据 26 String curLine = writer.toString();//存储从输入管道中取得的当前行 27 String[] words = curLine.split(" +|\\t+"); //将当前行分解成多个单词 28 for(int i = 0; i < words.length; i++) { 29 if(ignore.indexOf((words[i] + "#$").toLowerCase()) != -1)//去掉噪音词汇打头的行 30 continue; 31 String shift = ""; 32 for(int j = i; j < (words.length + i); j++) { 33 shift += words[j % words.length]; 34 if (j < (words.length + i - 1)) 35 shift += " "; 36 } 37 shift += "\\r\\n"; 38 output.write(shift); 39 writer.reset(); 40 } 41 } else 42 writer.write(c); 43 } 44 input.closeReader(); 45 output.closeWriter(); 46 47 } catch (IOException e) { 48 e.printStackTrace(); 49 } 50 } 51 52 }
1 //按照字母表排序 2 public class Alphabetizer extends Filter { 3 4 public Alphabetizer(Pipe input, Pipe output) { 5 super(input, output); 6 } 7 8 /** 9 * 10 */ 11 @Override 12 protected void transform() { 13 List<String> lines = new ArrayList<String>(); 14 CharArrayWriter writer = new CharArrayWriter(); 15 try { 16 int c = -1; 17 while((c = input.read()) != -1) { 18 writer.write(c); 19 // System.out.print((char) c); 20 if(c == 10) { 21 String curLine = writer.toString(); 22 lines.add(curLine); 23 writer.reset(); 24 } 25 } 26 27 28 sort(lines); 29 30 for(String s : lines) { 31 output.write(s); 32 } 33 34 input.closeReader(); 35 output.closeWriter(); 36 } catch (IOException e) { 37 e.printStackTrace(); 38 } 39 } 40 41 private void sort(List<String> lines) { //堆排序 42 int size = lines.size(); 43 44 for (int i = (size / 2 - 1); i >= 0; i--) 45 siftDown(lines, i, size); 46 47 for (int i = (size - 1); i >= 1; i--) { 48 Object tmp = lines.get(0); 49 lines.set(0, lines.get(i)); 50 lines.set(i, (String) tmp); 51 siftDown(lines, 0, i); 52 } 53 } 54 55 private void siftDown(List<String> lines, int root, int bottom) { 56 int max_child = root * 2 + 1; 57 58 while (max_child < bottom) { 59 if ((max_child + 1) < bottom) 60 if (((String) lines.get(max_child + 1)) 61 .compareTo((String) lines.get(max_child)) > 0) 62 max_child++; 63 64 if (((String) lines.get(root)).compareTo((String) lines 65 .get(max_child)) < 0) { 66 Object tmp = lines.get(root); 67 lines.set(root, lines.get(max_child)); 68 lines.set(max_child, (String) tmp); 69 root = max_child; 70 max_child = root * 2 + 1; 71 } else 72 break; 73 } 74 } 75 76 }
4. 显示结果
(这是input.txt的内容,作为输入)

这是输出结果,(每一行一共是三组字母,共三种可能的排列情况)可以发现很明显是先看到输入数据,输出数据出来的比较慢。

二、主程序/子程序风格
1、体系结构图
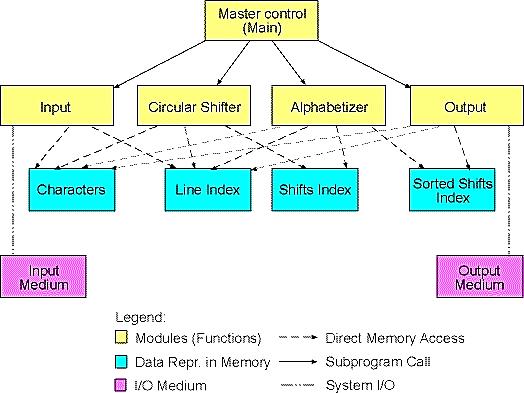
2.简述体系结构各部件的主要功能,实现思想。
上述的主程序/子程序的方法,将问题分解为输入(Input)、移动(Shifter)、按字母表排序(Alphabetizer)、输出(Output)这几个步骤,每一个步骤由一个对应的子程序来完成,由主程序来调度各个子程序,多个子程序共同完成计算。
在这种体系结构中,构件就是各种子程序,连接件就是子程序直接的协同关系和主程序对它们的调用。
Input: 将读取到的每行的数据保存到实现LineStorage接口的数据结构中去
shifter:主函数调用该方法,该方法对characters中的每行的数据进行循环移位,并将移位得到的新行保存到实现LineStorage的数据结构中去
alphabetizer: 对circularShift中得到的行数据进行按字母顺序排序
Output:output方法迭代调用alphabetizer里面的方法得到按字母顺序排好序的行数据,并输出
Characters:实现字符的处理。读取一行就用Characters抽象数据类型将该行存放,直到文件读完为止
3、写出主要的代码
1 public static void alphabetizer(List<String []> characters, List<Pair> index, List<Pair> alphabetedIndex) { 2 alphabetedIndex.addAll(index); 3 4 //下面是利用插入排序算法进行排序 5 for(int i = 1; i < alphabetedIndex.size(); i++) { 6 Pair temp = alphabetedIndex.get(i); 7 int wordIndex1 = temp.getWordIndex(); 8 int lineIndex1 = temp.getLineIndex(); 9 String str1 = characters.get(lineIndex1)[wordIndex1]; 10 int j; 11 for(j = i - 1; j >= 0; j--) { 12 13 int wordIndex2 = alphabetedIndex.get(j).getWordIndex(); 14 int lineIndex2 = alphabetedIndex.get(j).getLineIndex(); 15 16 String str2 = characters.get(lineIndex2)[wordIndex2]; 17 if(str1.compareToIgnoreCase(str2) < 0) { 18 alphabetedIndex.set(j + 1, alphabetedIndex.get(j)); 19 } else break; 20 } 21 alphabetedIndex.set(j + 1, temp); 22 } 23 } 24 //循环移位的代码 25 protected void transform() { 26 try { 27 CharArrayWriter writer= new CharArrayWriter(); //缓冲当前行 28 int c = -1; 29 while((c = input.read()) != -1) { 30 if(c == 10) { //回车,表示writer中取得了一行数据 31 String curLine = writer.toString();//存储从输入管道中取得的当前行 32 String[] words = curLine.split(" +|\\t+"); //将当前行分解成多个单词 33 for(int i = 0; i < words.length; i++) { 34 if(ignore.indexOf((words[i] + "#$").toLowerCase()) != -1)//去掉噪音词汇打头的行 35 continue; 36 String shift = ""; 37 for(int j = i; j < (words.length + i); j++) { 38 shift += words[j % words.length]; 39 if (j < (words.length + i - 1)) 40 shift += " "; 41 } 42 shift += "\\r\\n"; 43 output.write(shift); 44 writer.reset(); 45 } 46 } else 47 writer.write(c); 48 } 49 input.closeReader(); 50 output.closeWriter(); 51 52 } catch (IOException e) { 53 e.printStackTrace(); 54 } 55 }
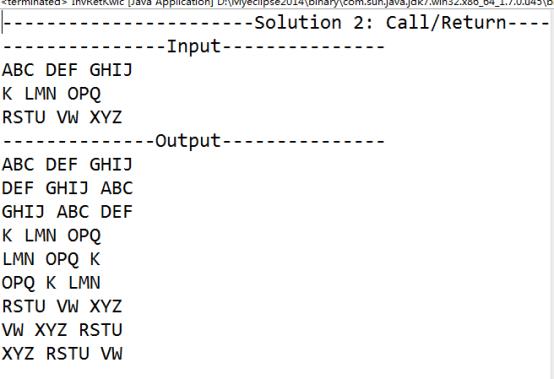
4. 显示结果
(这是input.txt的内容,作为输入)
这是输出结果,(每一行一共是三组字母,共三种可能的排列情况)可以发现运行的时候输入的数据与输出的数据是几乎同时出现的,该风格性能较好。
五、实验总结
通过这次实验,认识到了KWIC这个经典的例子,可以让不同的体系机构风格从多种角度来实现它。由于每种风格的构件、连接件、思想都不相同,所以不同风格之间的结构、过程和性能也不同。
管道/过滤器风格的构件是过滤器,连接件是管道,各个管道之间通过数据传输进行通信,结构很灵活,系统的耦合度较低,所以性能也弱。
主程序/子程序风格的构件是各个子程序,连接件是主程序对子程序的调用以及子程序之间的通信,靠多个子程序协同完成运算。整个系统可以说是紧密相连,耦合度很高,所以性能也很高。
以上是关于130242014023+李甘露美+第3次实验的主要内容,如果未能解决你的问题,请参考以下文章