20145326 《Java程序设计》第5周学习总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20145326 《Java程序设计》第5周学习总结相关的知识,希望对你有一定的参考价值。
20145326 《Java程序设计》第5周学习总结
教材学习内容总结
第八章
一、语法与继承结构
1.使用try 、catch
我们编写程序时总有些由意想不到的状况而引发的错误,java中的错误以对象方式呈现为java.lang.Throwable的各种子类实例。只要能捕捉包装错误的对象,就可以针对该错误做一些处理。java中所有错误都会被打包为对象,如果愿意,可以尝试(try)捕捉(catch)代表错误的对象后做一些处理。以书上228页的代码为例,这里使用了try,catch语法,JVM会尝试执行try区块中的程序代码。如果发生错误,执行流程会跳离错误发生点,然后比较catch括号中声明的类型,是否符合被抛出的错误对象类型,如果是的话,就执行catch区块中的代码。执行完catch区块后,如果没有其他代码了,程序就结束了。书上229页的例子示范了如何运用try、catch,在错误发生时显示更友好的错误信息,而且错误可以在被捕捉后,尝试恢复程序正常执行流程。此外书上还提到了一点,就java在异常处理的设计上,并不鼓励捕捉InputMismatchException。
2.异常继承架构
在先前的Average范例中,没用到try、catch语句,照样可以编译执行。为什么在书上230页的范例会编译错误?要解决这个错误信息有两种方式,一是使用try、catch打包System.in.read(),二是在main()方法旁声明throws java.io.IOException。简单来说就是编译程序认为调用System.in.read()时有可能发生错误,要求你一定要在程序中明确处理信息。错误会被包装为对象,这些对象都是可抛出的,因此设计错误对象都继承自java.lang.Throwable类,Throwable定义了取得错误信息、堆栈追踪等方法,他有两个子类:java.lang.Error与java.lang.Exception。Error与其子类代表了严重系统错误,如硬件层面错误、JVM错误或内存不足等问题。虽然也可以使用try、catch来处理Error对象,但并不建议。发生严重系统错误时,java本身是无力恢复的。Error对象抛出时,基本上不用处理,任其传播至JVM为止,或者是最多留下日志信息。如果抛出了Throwable对象,而程序中没有任何catch捕捉到错误对象,最后由JVM捕捉到的话,那JVM基本处理就是显示错误对象打包的信息并中断程序。程序设计本身的错误,建议使用Exception或其子类实例来实现,所以通常称错误处理为异常处理。单就语法与继承结构上来说,如果某个方法声明会抛出Throwable或子类实例,只要不是属于Error、java.lang.RuntimeException或其子类实例,你就必须明确使用try、catch语法加以处理,或者用throws声明这个方法会抛出异常,否则编译失败。受检异常存在之目的,在于API设计者实现某方法时,某些条件成立时会引发错误,而且认为调用方法的客户端有能力处理错误,要求编译程序提醒客户端必须明确处理错误,不然不可通过编译,API客户端无权选择要不要处理。属于RuntimeException衍生出来的类实例,代表API设计者实现某方法时,某些条件成立时会引发错误,而且认为API客户端应该在调用方法前做好检查,以避免发生错误,之所以命名为执行时期异常,是因为编译程序不会强迫一定得在语法上加以处理,亦称为非受检异常。另外如果父类异常对象在子类异常对象前被捕捉,则catch子类异常对象的区块将永远不会被执行,编译程序会检查出这个错误。要完成程序编译的话,必须更改异常对象捕捉的顺序。当catch异常后的区块内容重复时,从JDK7开始可以使用多重捕捉,使用前提是区块里的内容必须相同,不过仍得注意异常的继承,catch括号中列出的异常不得有继承关系,否则发生错误。
3.要抓还是要抛
如果方法设计流程中发生异常,而你设计时并没有充足的信息知道该如何处理(例如不知道链接库会用在什么环境),那么可以抛出异常,让调用方法的客户端来处理。操作对象的过程中如果会抛出受检异常,但目前环境信息不足以处理异常,无法使用try、catch处理时,可由方法的客户端依据当时调用的环境信息进行处理。为了告诉编译程序这个事实,必须使用throws声明此方法会抛出的异常类型或父类型,编译才能通过。抛出受检异常表示你认为调用方法的客户端有能力且应该处理异常。如果你认为客户端调用方法的时机不当引发了某个错误,希望客户端准备好前置条件,再来调用方法,这时可以抛出非受检异常让客户端得知此情况。,如果是非受检异常,编译程序不会明确要求使用try、catch或在方法上使用throws声明,因为java的设计上认为,非受检异常是程序设计不当引发的漏洞,异常应自动往外传播,不应使用try、catch来尝试处理。实际上在异常发生时,可以使用try、catch处理当时环境可进行的异常处理,当时环境无法决定如何处理的部分,可以抛出由调用方法的客户端处理。在catch区块进行完部分错误处理后,可以使用throw(注意不是throws)将异常再抛出。可以在任何流程中抛出异常,不一定要在catch区块中。如果使用继承时,父类某个方法声明throws某些异常,子类重新定义该方法时可以:1.不声明throws任何异常。 2.throws父类该方法中声明的某些异常。 3.throws父类该方法中声明异常的子类。4.throws父类方法中未声明的其他异常。 5.throws父类方法中声明异常的父类。
4.贴心还是造成麻烦
java是唯一采用受检异常的语言。这有两个目的:一是文件化,受检异常声明会是API操作接口的一部分,客户端只要查阅文件,就可以知道方法可能会引发哪些异常。二是提供编译程序信息,让编译程序能够在编译时期就检查出API客户端没有处理异常。受检异常本意良好,有助于程序设计人员注意到异常的可能性并加以处理,但在应用程序规模扩大时,会逐渐对维护造成困难,上述情况不一定是你自定义API 时发生,也可能是在底层引入了一个会抛出受检异常的API而发生类似情况。在某个SQLException发生时,最好的方法是将异常浮现至用户画面呈现,例如网页技术,将错误信息在网页上显示出来给管理人员。随着应用程序的演化,异常也可以考虑演化,也许一开始是设计为受检异常,但因为一系列因素,将受检异常演化为非受检异常也是很有必要的。
5.认识堆栈追踪
在多重方法调用下,异常发生点可能是在某个方法之中,若想得知异常发生的根源,以及多重方法调用下异常的堆栈传播,可以使用堆栈追踪来取得相关信息。使用方法是直接调用异常对象的printStackTrace()。堆栈追踪信息中显示了异常类型,最顶层是异常的根源,以下是调用方法的顺序,程序代码行数是对应于当初的程序原始码,如果想要取得个别的堆栈追踪元素进行处理,则可以使用getStackTrace(),在捕捉异常后什么都不做的话或者做了不适当的处理,这种程序代码会对应用程序维护造成严重伤害。在使用throws重抛异常时,异常的追踪堆栈起点,仍是异常的发生根源,而不是重抛异常的地方。如果想要让异常堆栈起点为重抛异常的地方,可以使用fillInStackTrace()方法,这个方法会重新装填异常堆栈,将起点设为重抛异常的地方,并返回Throwable对象。
6.关于assert
程序执行的某个时间点或者某个情况下,一定是处于或不处于某种状态,如果不是,则是个严重的错误!在JDK1.4之后,断言功能的关键字是assert,为了避免JDK1.3或者之前更早版本程序使用assert作为变量导致名称冲突问题,默认执行时,不启动断言检查,如果要在执行时启动断言检查,可以在执行java指令时,指定—enableassertions或者—ea自变量。断言是判定程序中的某个执行点必然是或者不是某个状态,所以不能当作像if之类的判断式来使用,assert不应当作程序执行流程的一部分。
二、异常与资源管理
1.使用finally
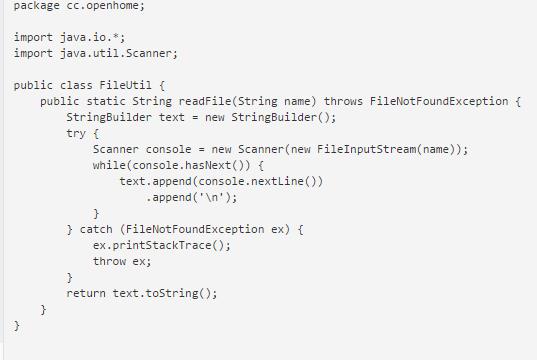
如果创建FileInputStream实例就会开启文档,不使用时,应当调用close()关闭文档。若想要的是无论如何,最后一定要执行关闭动作,try、catch语法还可以搭配finally使用,无论try区块中有无发生异常,若撰写有finally区块,则finally区块一定会被执行。如果程序撰写的流程中先return了,而且也有finally区块,那么finally区块会先执行完后,再将值返回。
2.自动尝试关闭资源
就如书上249页的代码所展现的一样,想要尝试自动关闭资源的对象,是撰写在try之后的括号中,如果无须catch处理任何异常,可以不用撰写,也不用撰写finally自行尝试关闭资源。当然使用自动尝试关闭资源语法时,也可以搭配catch(书上250)。使用自动尝试关闭资源语法时,并不影响你对特定异常的处理,实际上,自动尝试关闭资源语法也仅仅是协助你关闭资源,而不是用于处理异常。不要试图自行撰写程序代码关闭资源,这样会造成重复!!!
3.java.lang.AutoCloseable接口
JDK7的尝试关闭资源语法可套用的对象,必须操作java.lang.AutoCloseable接口!AutoCloseable是JDK7新增的接口,仅定义了close()方法。只要操作AutoCloseable接口,就可以套用至尝试关闭资源语法。尝试关闭资源语法也可以同时关闭两个以上的对象资源,只要中间以分号间隔。值得注意的是在try的括号中,越后面撰写的对象资源会越早被关闭!
第九章
一、使用Collection收集对象
1.认识Collection架构
程序中常有收集对象的需求,就目前为止,你学过可以收集对象的方式就是使用object数组,在javaSE中其实就提供了数个收集对象的类。你可以直接取用这些类,而不用重新打造类似的API。收集对象的行为,像是新增对象的add()方法,移除对象的remove()方法等,都是定义在java.util.Collection中。既然能收集对象,也能逐一取得对象,这就是java.lang.Iterable定义的行为,它定义了iterator()方法返回java.util.Iterator操作对象,可以让你逐一取得对象。然而收集对象会有不同的需求,如果希望收集时记录每个对象的索引顺序,并可依索引取回对象,这样的行为定义在java.util.List接口中。如果希望收集的对象不重复,具有集合的行为,则由java.util.Set定义。如果希望收集对象时,以队列排列。收集的对象加入至尾端,取得对象时从前端,则可以使用java.util.Queue。如果希望对Queue的两端进行加入、移除等动作,则可以使用java.util.Deque。
2.具有索引的List
List是一种Collection,作用是收集对象,并以索引方式保留收集的对象顺序,其操作类之一是java.util.ArrayList。查看API文件的时候发现,List接口定义了add()、remove()、set()等许多依索引操作的方法。java.util.LinkedList也操作了List接口,可以将书上264页范例中的ArrayList换为LinkedList,而结果不变,那么什么时候使用ArrayList,什么时候用LinkedList呢?简而言之就是,ArrayList适合排序的时候用,可得到较好的速度表现。而LinkedList采用了链接结构,当需要调整索引顺序时,比较适用。
3.内容不重复的Set
同样是收集对象,在收集过程中若有相同对象,则不再重复收集,若有这类需求,可以使用Set接口的操作对象,String的Split()方法,可以指定切割字符串的方式。一般用hashcode()与equals()来判断对象是否相同。
4.支持队列操作的Queue
Queue继承自Collection,所以也具有Collection的add()、remove()、element()等方法,然而Queue定义了自己的offer()、poll()与peek()等方法。最主要的差别在于,add()、remove()、element()等方法操作失败时会抛出异常,而offer()、poll()、peek()等方法操作失败时会返回特定值。同样的,Deque中定义addFirst()、removeFirst()、getFirst()、addLast()、removeLast()、getLast()等方法,操作失败时会抛出异常,而offerFirst()、pollFirst()、peekFirst()、offerLast()、pollLast()、peekLast()等方法,操作失败时会返回特定值。此外,要记住堆栈结构是先进后出!
5.使用泛型
在使用Collection收集对象时,由于事先不知道被收集对象的形态,因此内部操作时,都是使用object来参考被收集的对象,取回对象时也是以object类型返回。所以若想针对某类定义的行为操作,必须告诉编译程序,让对象重新扮演该类型。JDK5之后增加了泛型语法。若接口支持泛型,在操作时也会比较方便,只要声明参考时有指定类型,那么创建对象时就不用再写类型了,泛型也可以仅定义在方法上,最常见的是在静态方法上定义泛型。
6.简介Lambda表达式
如书上279页的范例,你会看到信息重复了,声明request变量时已经告知是Request类型,而建立Request实例的匿名类语法又写了一次,实际上Request接口只有一个方法必须实现,当这种情况发生时,在JDK8中可以使用Lambda来简化程序,Lambda表达式的语法省略了接口类型和方法名称。—>左边是参数列,右边是方法本体。编译程序可以由Request request的声明中得知语法上被省略的信息。虽然不鼓励使用Lambda表达式来写复杂的演算,不过若流程较为复杂,无法在一行的Lambda表达式中写完,可以使用区块{}符号包括演算流程。如果方法必须返回值,在区块中就必须使用return。
7.Interable与Iterator
事实上,无论是List、Set还是Queue,都会有个iterator()方法,这个方法在JDK5出现之前,是定义在Collection接口中,而List、Set、Queue继承自Collection,所以也都拥有iterator()的行为。iterator()会返回java.util.Iterator接口的操作对象,这个对象包括了Collection收集的所有对象,你可以使用Iterator的hasNext()看看有无下一个对象,若有的话,再使用next()取得下一个对象,因此无论List、Set、Queue还是任何Collection,都可以使用forEach()来显示所收集的对象。在JDK5之后有了增强式for循环,前面看到它运用在数组上,实际上,增强式for循环还可以运用在操作Iterable接口的对象上。JDK8之前的接口一旦新增了语法,所有实现接口的类都得操作该方法,现存各种API中实现Iterable接口的类太多了,这样不会造成这些类因为没有操作forEach()而在JDK8上编译错误吗?不会!因为JDK8演进了interface语法。允许接口定义默认方法。
8.Comparable与Comparator
在收集对象之后,对对象进行排序是常有的动作,不过不用亲自动手,java.util.Collection提供有sort()方法,由于必须要有索引才能进行排序,因此Collection的sort()方法接受List操作对象。Collection的sort()方法要求被排序的对象必须操作java.lang.Comparable接口!Collection的sort()方法在取得a对象与b对象进行比较时,会先将a对象扮演为Comparable,然后调用a.compareTo(b),如果a对象顺序上小于b对象则返回小于0的值,若顺序上相等则返回0,若顺序上a大于b则返回大于0的值。查看API文件得知,Integer有操作Comparable的接口。Collections的sort()方法有另一个重载版本,可接受java.util.Comparator接口的操作对象,如果使用这个版本,排序方式将根据Comparator的compare()定义来决定。在java的规范中,与顺序有关的行为,通常要不对象本身是Comparable,要不就是另行指定Comparator对象告知如何排序。set的操作类之一java.util.TreeSet,不仅拥有收集不重复对象的能力,还可用红黑树方式排序收集的对象,条件就是收集的对象必须是Comparable或者在创建TreeSet时指定Comparator对象。Queue的操作类之一java.util.PriorityQueue也是,收集至PriorityQueue的对象,会根据你指定的优先权来决定对象在队列中的顺序,优先权的告知,要不就是对象必须是Comparable,或者是建立PriorityQueue时指定Comparator对象。
二、键值对应的Map
1.常用Map操作类
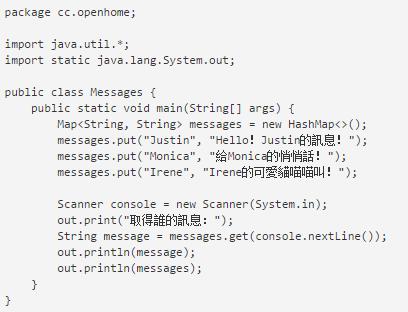
在使用Map相关API前,先了解Map设计架构,对正确使用API会有帮助。常用的Map操作类为java.util.HashMap与java.util.TreeMap,其继承自抽象类java.util.AbstractMap。建立Map操作对象时,可以使用泛型语法指定键与值的类型。要建立键值对应,可以使用put()方法,第一个自变量是键,第二个自变量是值,对于Map而言,键不会重复,判断键是否重复是根据hashCode()与equals(),所以作为键的对象必须操作hashCode()与equals()。若要指定键取回对应的值,则使用get()方法,在hashMap中建立键值对应后,键是无序的,这可以在执行结果中看到。如果想让键是有序的,则可以使用TreeMap。如果使用TreeMap建立键值对应,则键的部分将会排序,条件是作为键的对象必须操作Comparable接口,或者是在建立TreeMap时指定操作Comparator接口的对象。一般常用Properties的setProperty()指定字符串类型的键值,getProperty指定字符串类型的键,取回字符串类型的值,通常称为属性名称和属性值。.properties的=左边设定属性名称,右边设定属性值。可以使用Properties的load()方法指定InputStream的实例。
2.访问Map键值
Map虽然与Collection没有继承上的关系,但它们却是彼此的API。如果想取得Map中所有的键,可以调用Map的keySet() 返回Set对象,由于键是不重复的,所以用Set操作返回是理所当然的做法。如果想取得Map中所有的值,则可以使用values()返回Collection对象。作者一直在强调面向对象基础以及认识API架构的重要性,面对庞大的API,只有稳固的面向对象基础以及了解API构架,才能够以简驭繁,活用API!Map没有继承Iterable,有个forEach()方法是定义在Map接口上,可使用这个方法结合Lambda表达式,在迭代键与值时可以获得不错的可读性!





教材学习中的问题和解决过程
其实感觉还好,就像娄老师所说的,第四五六七章的内容才是java核心内容,比较抽象难懂。之后的内容都是介绍各种API的应用,都是活生生的例子,比较具体,如果觉得难那是因为对这部分知识感到陌生,不熟悉。自己首先理清头绪,然后多看几遍书,多敲几遍代码。感觉立马就上来了!要讲究科学的学习方法~不要盲目!


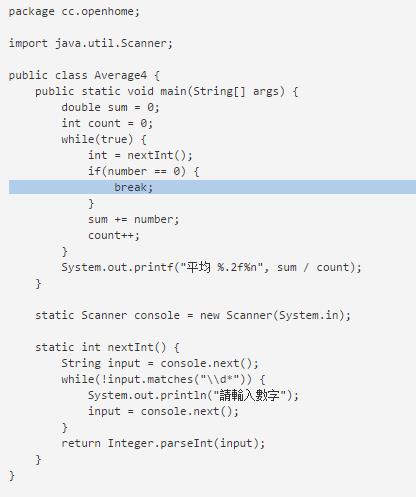
代码调试中的问题和解决过程
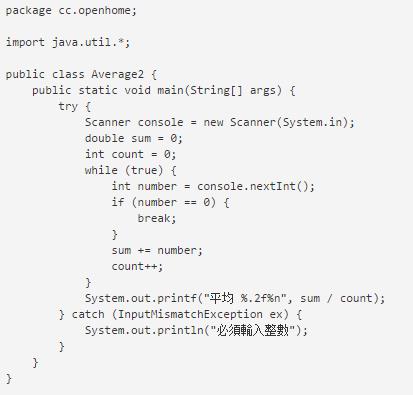
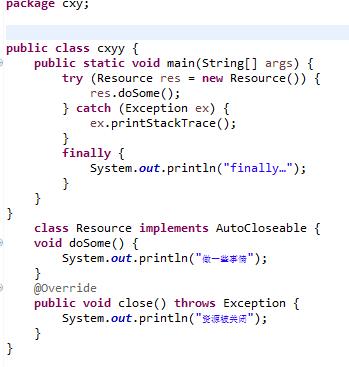
很好奇finally块中的代码一定会被执行吗? 想要验证finally块中的代码是不是一定会被执行,我的思路是在finally块前加一些终止类型的代码来看看能不能阻止它执行。
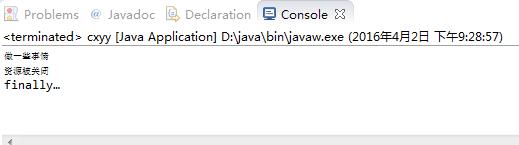
输出结果如下:
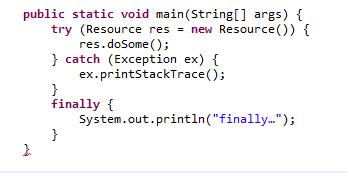
在该代码段加上return:
目前来看finally块应该是都会被执行的。 但是同学告诉我有一种情况可以让finally块不执行,就是加上System.exit(),这段代码的意义是终止JVM。
其他(感悟、思考等,可选)
这周又是自学两章,不得不承认从第五周开始就有点疲倦了。上周有一个同学在自己的博客里给娄老师提了意见,说学习量太大,没什么效率。娄老师解释说,之所以会有这种体会,那是因为没有找到一个适合自己的良好的学习方法! 在写这篇博客前,我脑子里不断回想着娄老师上课时说的那些话。要学会抓住重点,把力量用在刀刃上,寻找乐趣,保持激情,提高学习效率! 娄老师上周就说了,学完了四五六七章,其实java的核心知识也就学完了,后面全都是讲的一些类的应用。于是我是带着目的去看教材的,不是盲目的。我后来发现这点尤其重要!我知道第八章和第九章就是介绍一些类的应用,于是我一边看书,一边总结,看书上总共介绍了多少种API,每一种API的架构是什么,每一种API的作用与注意事项是什么。就这样有系统的看了一遍教材,感觉效率十分高!而且头脑思绪清晰。其实这些知识不是难,我们只是感到陌生而已。同学们有了畏难情绪和厌学情绪,当然就学不进去了,还谈什么效率!第八章和第九章的知识不像之前对象、封装、继承那些基本概念那么抽象难懂,都是活生生的具体的例子,接受起来其实也挺快的。我就系统的看了一遍,就感觉已经掌握了70%了吧~ 所以娄老师说的很对,重要的不是要你学多少java知识,而是通过不断的学习过程,来总结出一套适合自己的良好的学习方法,这将受用一生。当然不同的人肯定情况不一样,适合自己的才是最好的。我这周最大的收获就是真正体会到,学习也要讲科学,不要盲目。时间用得多,不一定就学得好。找到属于自己的学习方法,提高效率!这比一切都重要! 调整一下自己的心态吧,任何事情不要有畏难情绪,万事开头难,只要是对的,就坚持!最终一定会受益匪浅!!!
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
| 目标 | 3500行 | 20篇 | 300小时 | |
| 第一周 | 120/120 | 1/1 | 14/14 | |
| 第二周 | 340/460 | 1/2 | 14/28 | |
| 第三周 | 200/660 | 1/3 | 14/42 | |
| 第四周 | 320/980 | 1/4 | 14/56 | |
| 第五周 | 280/1260 | 1/5 | 14/70 |
以上是关于20145326 《Java程序设计》第5周学习总结的主要内容,如果未能解决你的问题,请参考以下文章
20145326蔡馨熠《信息安全系统设计基础》第12周学习总结