爬虫基本结构
Posted Michael2397
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫基本结构相关的知识,希望对你有一定的参考价值。
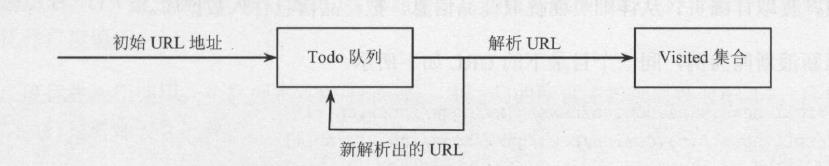
爬虫程序的工作是从一个种子链接的集合开始。把种子URL集合作为参数传递给网络爬
虫。爬虫先把这些初始的URL放入URL工作队列(Todo队列,又叫作Frontier),然后遍历
所有工作队列中的URL,下载网页并把其中新发现的URL再次放入工作队列。为了判断一个
URL是否已经遍历过,把所有遍历过的URL放入历史表。
while (todo.size () > 0) { //如果 Todo队列不是空的 //从Todo队列里面提取URL String strUrl = todo.iterator().next(); //下载URL对应的网页内容 String content = downloadPageContent(strUrl); //把网页内容存储到本地 //提取网页内容中新发现的URL链接 HashSet<String> newLinks = retrieveLinks(content, new URL(strUrl)); //把新发现的链接加入Todo队列 todo.addAll(newLinks);
//从Todo队列里删除已经爬过的URL
todo.remove(strUrl);
//把从Todo队列里删除的URL添加到Visited集合中
visited.add(strUrl);
}
整个互联网是一个大的有向有环图,其中的每个URL相当于图的一个节点,因此,网页遍
历就可以釆用图遍历的算法进行。通常,网络爬虫的遍历策略有三种,广度优先遍历、深度优先
遍历和最佳优先遍历。其中,深度优先遍历由于极有可能使爬虫陷入黑洞,因此,广度优先遍历
和最佳优先遍历就成为了常用的爬虫策略。垂直搜索往往采用定制的遍历方法抓取特定的网站。
一般的爬虫软件,通常都包含以下几个模块。 (1) 保存种子URL和待抓取的URL的数据结构,把网页中发现的新链接放入Frontier中。 (2) 保存已经抓取的URL的数据结构,防止重复抓取。需要快速知道一个URL是否已经 抓取过。
(3) 页面获取模块。
(4) 对已经获取的页面内容的各个部分进行抽取的模块。例如抽取html、javascript等。
其他可选的模块包括下面5个。
(1) 负责连接前处理模块。
(2) 负责连接后处理模块。
(3) 过滤器模块。HTML中并没有描述链接资源的类型。如果要访问某些类型的资源,往
往通过后缀判断资源的类型。例如,htm往往代表静态网页类型,img往往代表图片。
(4) 负责多线程的模块。多线程同时下载网页。
(5)负责分布式的模块。
1.保存种子和爬取出来的URL的数据结构

2.保存已经抓取过的URL的数据结构
己经抓取过的URL的规模和待抓取的URL的规模是一个相当的量级。正如我们前面介绍
的TODO表和Visited表。它们唯一的不同是,Visited表会经常被查询,以便确定发现的URL
是否已经处理过。因此,如果Visited表数据结构是一个内存数据结构,可以釆用HashCHashMap
或者HashSet)来存储,如果保存在数据库中,可以对URL列建立索引。
以上是关于爬虫基本结构的主要内容,如果未能解决你的问题,请参考以下文章