关于栈帧。
Posted shy_BIU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于栈帧。相关的知识,希望对你有一定的参考价值。
今天我们来讲讲,关于C语言里栈帧的那些事。
栈帧可以说是C语言里比较难理解的一个点里,但是,难的东西,要是搞懂了,那么拿下这门语言,也不晚了。
首先要明白,C语言中内存分配方式有三种:
1.静态存储区域分配。
地址空间概念在程序运行生命周期之间都存在,就比如一些全局变量和一些static定义的局部变量。
2.在栈上创建(内存有限)
就比如一些临时变量,局部变量。(放在栈中效率高。)
3.在堆上创建。
亦称动态内存分配。
通常用malloc或者new申请相应的内存空间。
当然也要用face或delete来释放内存。
具体内存环境分布如下图所示:
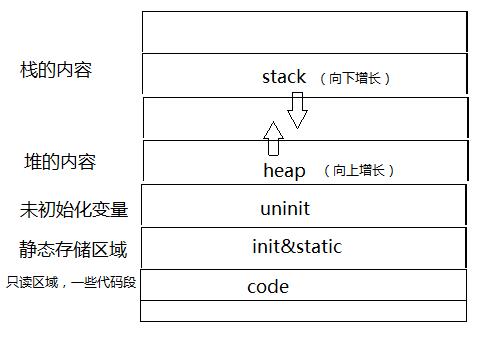
可以看到,栈里的内容,是从上往下增长的,堆里的内容,是从下往上增长的。栈和堆之间存在一定空间,那么也说明,如果栈或者堆的内容一多,就会出现栈溢出的情况。今天我们主要讲栈,所以这个实验就不做了。
栈的特点是:存放变量用来加快效率,而且变量从上到下增长,这些东西,我们马上开始证明。
首先,我们先编写一个基础的交换两个数数值的代码。
#define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> void swap(int *x, int *y) { int tmp = 0; tmp = *x; *x = *y; *y = tmp; } int main() { int a = 10; int b = 20; swap(&a, &b); printf("a=%d,b=%d\\n", a, b); return 0; }
我们知道,main函数是整个程序的入口,那么现在,我们按F10,开始调试我们的代码,从语句"int main()"开始。
程序跑起来,到swap函数调用前停下来,接下来我们来看我们刚刚定义的变量a和b的地址。
同时打开监视和内存界面。
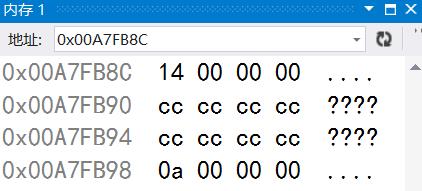
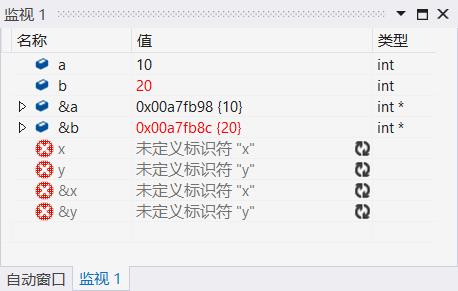
这里我们可以看到,变量b和a的量都放在一个固定的地址上,而且b的地址要比a的小,这也进一步证明了栈是从上往下增长的客观事实。
为了更好研究,我们把代码变成汇编代码。

这里在定义和初始化a,b变量的时候,分别把10 mov 给a所在的地址,20 mov 给b所在的地址。
然后准备开始调用swap函数,把b的地址先放到eax寄存器中,把eax压入栈,再把a的地址放到ecx寄存器中,把ecx压入栈中。
然后需要提到一个call命令,这里着重提一下,call命令的作用有两个:
1.默认将当前命令的下一条指令的地址压入栈中。
2.跳转至目标函数地址开始过程调用。
听不懂没关系,我们用图来理解,在用图解释前,我们需要提及几个特别的寄存器:
1.EBP:指向栈底。2.ESP:指向栈顶。3.EIP:指向当前指令所在位置。
进入swap函数,我们可以看到,EIP,ESP的位置都发生了变化。
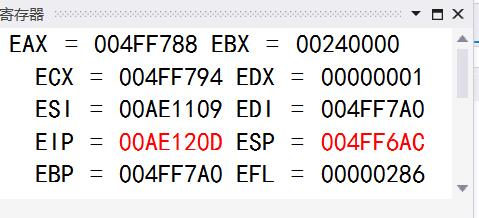
这里可能还不是很理解,用图解释一下,如下:
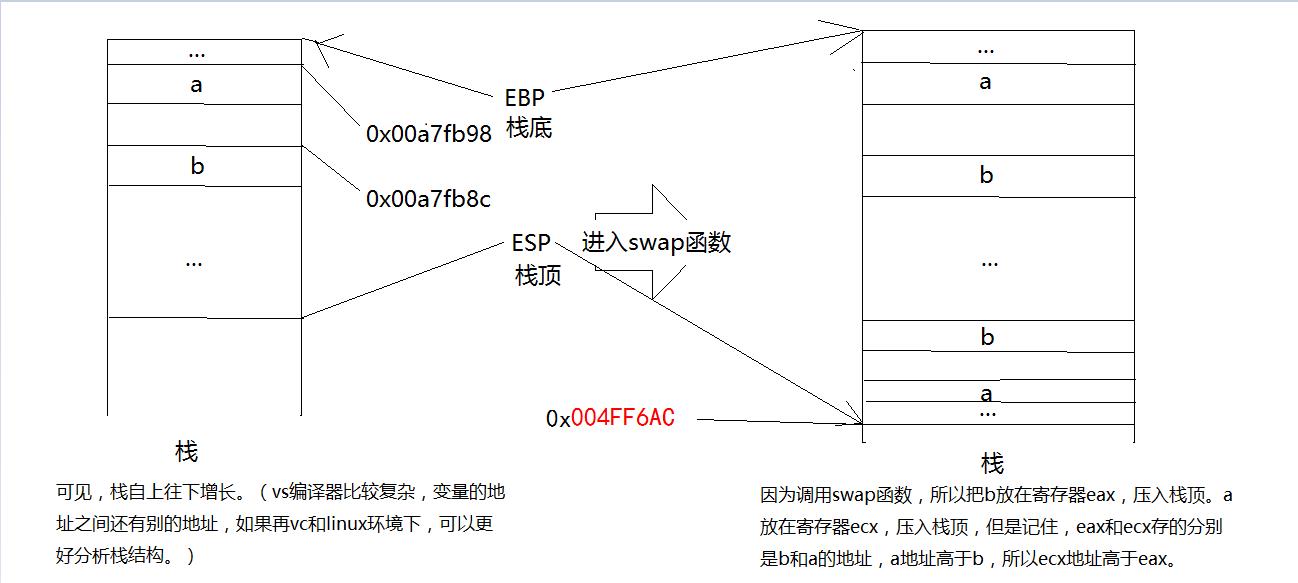
(这里出现了一个小失误,第一次调试的时候退出去了,和后来的汇编不是同一个进程里的。所以栈顶和栈底的地址和a,b的地址差距很大。)
(但是,最重要的是理解栈是从上到下增长的,而且!如果调用函数,是要把参数压入栈顶,重新调用的再返回的。)
感谢审阅。
以上是关于关于栈帧。的主要内容,如果未能解决你的问题,请参考以下文章