URL编码
Posted alifpga
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了URL编码相关的知识,希望对你有一定的参考价值。
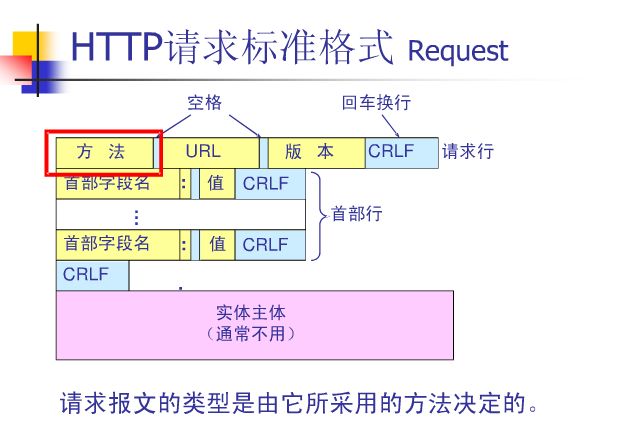
预备知识

URI是统一资源标识的意思,通常我们所说的Url只是URI的一种。典型Url的格式如上面所示。下面提到的Url编码,实际上应该指的是URI编码。
为什么需要Url编码
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。
例如Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc& ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和= 符号进行转义,也就是对其进行编码。
又如,Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
哪些字符需要编码
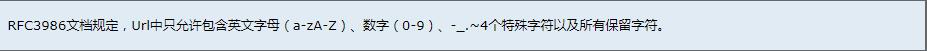

RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。
US-ASCII字符集中没有对应的可打印字符
Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。
保留字符
Url可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔 主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&\'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中 的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符:

不安全字符
还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
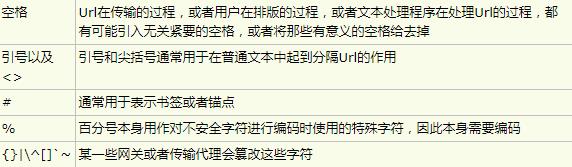
需要注意的是,对于Url中的合法字符,编码和不编码是等价的,但是对于上面提到的 这些字符,如果不经过编码,那么它们有可能会造成Url语义的不同。因此对于Url而言,只有普通英文字符和数字,特殊字符$-_.+!*\'()还有保留 字符,才能出现在未经编码的Url之中。其他字符均需要经过编码之后才能出现在Url中。
但是由于历史原因,目前尚存在一些不标准的编码实现。例如对于~符号,虽然RFC3986文档规定,对于波浪符号~,不需要进行Url编码,但是还是有很多老的网关或者传输代理会。
如何对Url中的非法字符进行编码
Url编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的 十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就 是%61,我们在地址栏上输入http://g.cn/search?q=%61%62%63,实际上就等同于在google上搜索abc了。又如@符号 在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。
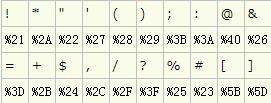
常见字符的Url编码列表:
保留字符的Url编码
对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。 对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如“中文”使用UTF-8字符集得到 的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到“%E4%B8%AD%E6%96%87”。
如果某个字节对应着ASCII字符集中的某个非保留字符,则此字节无需使用百分号表示。 例如“Url编码”,使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着ASCII中的非保留字符“Url”,因此这三个字节可以用非保留字符“Url”表示。最终的Url编码可以简化成 “Url%E7%BC%96%E7%A0%81” ,当然,如果你用"%55%72%6C%E7%BC%96%E7%A0%81”也是可以的。
由于历史的原因,有一些Url编码实现并不完全遵循这样的原则,下面会提到。
文档字符集会影响encodeURI吗?
之前在使用Aptana(为什么专指aptana下面会提到)遇到一个很迷惑的问题,就是在使用encodeURI的时候,发现它编码得到的结果和我想的很不一样。下面是我的示例代码:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/
DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml">
<head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
</head> <body> <script type="text/javascript">
document.write(encodeURI("中文")); </script>
</body> </html>
运行结果输出%E6%B6%93%EE%85%9F%E6%9E%83。显然这并不是使用UTF-8字符集进行Url编码得到的结果(在Google上搜索“中文”,Url中显示的是%E4%B8%AD%E6%96%87)。
所以很质疑,难道encodeURI还跟页面编码有关,但是发现,正常情况下,如果你使用gb2312进行Url编码也不会得到这个结果的才是。后来终于发现,原来是页面文件存储使用的字符集和Meta标签中指定的字符集不一致导致的问题。 Aptana的编辑器默认情况下使用UTF-8字符集。也就是说这个文件实际存储的时候使用的是UTF-8字符集。但是由于Meta标签中指定了 gb2312,这个时候,浏览器就会按照gb2312去解析这个文档,那么自然在“中文”这个字符串这里就会出错,因为“中文”字符串用UTF-8编码过 后得到的字节是0xE4 0xB8 0xAD 0xE6 0x96 0x87,这6个字节又被浏览器拿gb2312去解码,那么就会得到另外三个汉字“涓枃”(GBK中一个汉字占两个字节),这三个汉字在传入 encodeURI函数之后得到的结果就是%E6%B6%93%EE%85%9F%E6%9E%83。因此,encodeURI使用的还是UTF-8,并 不会受到页面字符集的影响。
其他和Url编码相关的问题
对于包含中文的Url的处理问题,不同浏览器有不同的表现。例如对于IE,如果你勾选了高级设置“总是以UTF-8发送Url”,那么Url中的路 径部分的中文会使用UTF-8进行Url编码之后发送给服务端,而查询参数中的中文部分使用系统默认字符集进行Url编码。为了保证最大互操作性,建议所 有放到Url中的组件全部显式指定某个字符集进行Url编码,而不依赖于浏览器的默认实现。
另外,很多HTTP监视工具或者浏览器地址栏等在显示Url的时候会自动将Url进行一次解码(使用UTF-8字符集),这就是为什么当你在 Firefox中访问Google搜索中文的时候,地址栏显示的Url包含中文的缘故。但实际上发送给服务端的原始Url还是经过编码的。你可以在地址栏 上使用Javascript访问location.href就可以看出来了。在研究Url编解码的时候千万别被这些假象给迷惑了。
版权所有权归卿萃科技 杭州FPGA事业部,转载请注明出处
作者:杭州卿萃科技ALIFPGA
原文地址:杭州卿萃科技FPGA极客空间 微信公众号

扫描二维码关注杭州卿萃科技FPGA极客空间
以上是关于URL编码的主要内容,如果未能解决你的问题,请参考以下文章
markdown 打字稿...编码说明,提示,作弊,指南,代码片段和教程文章
结合两个代码片段?将用户输入的 Youtube url 转换为嵌入 url,然后将 iframe src 替换为转换后的 url