pandas.DataFrame学习系列2——函数方法
Posted 修身齐家治国平天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas.DataFrame学习系列2——函数方法相关的知识,希望对你有一定的参考价值。
DataFrame类具有很多方法,下面做用法的介绍和举例。
pandas.DataFrame学习系列2——函数方法(1)
1.abs(),返回DataFrame每个数值的绝对值,前提是所有元素均为数值型
1 import pandas as pd 2 import numpy as np 3 4 df=pd.read_excel(\'南京银行.xlsx\',index_col=\'Date\') 5 df1=df[:5] 6 df1.iat[0,1]=-df1.iat[0,1] 7 df1 8 Open High Low Close Turnover Volume 9 Date 10 2017-09-15 8.06 -8.08 8.03 8.04 195.43 24272800 11 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 12 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 13 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 14 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600 15 16 df1.abs() 17 Open High Low Close Turnover Volume 18 Date 19 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800.0 20 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600.0 21 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100.0 22 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700.0 23 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600.0
2.add(other, axis=\'columns\', level=None, fill_value=None) 将某个序列或表中的元素与本表中的元素相加,默认匹配列元素
1 ar1=[8.1,8.2,8.0,8.15,200.00,32000000] 2 cl1=[\'Open\',\'High\',\'Low\',\'Close\',\'Turnover\',\'Volume\'] 3 se1=pd.Series(data=ar1,index=cl1) 4 se1 5 6 Open 8.10 7 High 8.20 8 Low 8.00 9 Close 8.15 10 Trunover 200.00 11 Volume 32000000.00 12 dtype: float64 13 14 df1.add(se1) 15 Open High Low Close Turnover Volume 16 Date 17 2017-09-15 16.16 0.12 16.03 16.19 395.43 56272800.0 18 2017-09-18 16.15 16.33 16.03 16.21 400.76 56867600.0 19 2017-09-19 16.13 16.26 15.94 16.15 633.76 86253100.0 20 2017-09-20 16.07 16.26 15.95 16.18 519.94 71909700.0 21 2017-09-21 16.12 16.30 15.99 16.19 441.94 62056600.0
1 df1.add(df1) 2 3 Open High Low Close Turnover Volume 4 Date 5 2017-09-15 16.12 -16.16 16.06 16.08 390.86 48545600 6 2017-09-18 16.10 16.26 16.06 16.12 401.52 49735200 7 2017-09-19 16.06 16.12 15.88 16.00 867.52 108506200 8 2017-09-20 15.94 16.12 15.90 16.06 639.88 79819400 9 2017-09-21 16.04 16.20 15.98 16.08 483.88 60113200
3.add_prefix()和add_suffix()为列名添加前缀或后缀
1 df1.add_prefix(\'list\') 2 3 listOpen listHigh listLow listClose listTurnover listVolume 4 Date 5 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800 6 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 7 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 8 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 9 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600 10 11 df1.add_suffix(\'list\') 12 13 Openlist Highlist Lowlist Closelist Turnoverlist Volumelist 14 Date 15 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800 16 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 17 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 18 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 19 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600
4.agg(func, axis=0, *args, **kwargs),合计运算,常用的函数有min,max,prod,mean,std,var,median等
1 所有列只做一种运算 2 df1.agg(sum) 3 Open 4.013000e+01 4 High 4.043000e+01 5 Low 3.994000e+01 6 Close 4.017000e+01 7 Turnover 1.391830e+03 8 Volume 1.733598e+08 9 dtype: float64 10 11 所有列做两种运算 12 df1.agg([\'sum\',\'min\']) 13 Open High Low Close Turnover Volume 14 sum 40.13 40.43 39.94 40.17 1391.83 173359800 15 min 7.97 8.06 7.94 8.00 195.43 24272800 16 17 不同列做不同运算 18 df1.agg({\'Open\':[\'sum\',\'min\'],\'Close\':[\'sum\',\'max\']}) 19 Close Open 20 max 8.06 NaN 21 min NaN 7.97 22 sum 40.17 40.13
5.align(),DataFrame与Series或DataFrame之间连接运算,常用的有内联,外联,左联,右联


1 df2=df[3:5] 2 df2 3 Out[68]: 4 Open High Low Close Turnover Volume 5 Date 6 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 7 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600 8 9 df1.align(df2,join=\'inner\') #返回的为元组类型对象 10 ( Open High Low Close Turnover Volume 11 Date 12 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 13 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600, 14 Open High Low Close Turnover Volume 15 Date 16 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 17 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600) 18 19 df1.align(df2,join=\'left\') 20 Out[69]: 21 ( Open High Low Close Turnover Volume 22 Date 23 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800 24 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 25 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 26 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 27 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600, 28 Open High Low Close Turnover Volume 29 Date 30 2017-09-15 NaN NaN NaN NaN NaN NaN 31 2017-09-18 NaN NaN NaN NaN NaN NaN 32 2017-09-19 NaN NaN NaN NaN NaN NaN 33 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700.0 34 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600.0) 35 36 df1.align(df2,join=\'left\')[0] 37 Out[70]: 38 Open High Low Close Turnover Volume 39 Date 40 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800 41 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 42 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 43 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 44 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600
6.all()和any(),判断选定的DataFrame中的元素是否全不为空或是否任意一个元素不为空,返回值为Boolean类型
1 df1.all(axis=0) 2 Out[72]: 3 Open True 4 High True 5 Low True 6 Close True 7 Turnover True 8 Volume True 9 dtype: bool 10 11 df1.all(axis=1) 12 Out[73]: 13 Date 14 2017-09-15 True 15 2017-09-18 True 16 2017-09-19 True 17 2017-09-20 True 18 2017-09-21 True 19 dtype: bool 20 21 df1.any() 22 Out[74]: 23 Open True 24 High True 25 Low True 26 Close True 27 Turnover True 28 Volume True 29 dtype: bool
7.append(),在此表格尾部添加其他对象的行,返回一个新的对象
1 df2=df[5:7] 2 df2 3 Out[93]: 4 Open High Low Close Turnover Volume 5 Date 6 2017-09-22 8.01 8.10 8.00 8.08 300.13 37212200 7 2017-09-25 8.06 8.07 7.97 7.99 262.30 32754500 8 9 df1.append(df2) 10 Out[94]: 11 Open High Low Close Turnover Volume 12 Date 13 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800 14 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 15 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 16 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 17 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600 18 2017-09-22 8.01 8.10 8.00 8.08 300.13 37212200 19 2017-09-25 8.06 8.07 7.97 7.99 262.30 32754500
这里介绍一个低效的和高效的建立一个DataFrame的方法
1 #略低效的方法 2 >>> df = pd.DataFrame(columns=[\'A\']) 3 >>> for i in range(5): 4 ... df = df.append({\'A\'}: i}, ignore_index=True) 5 >>> df 6 A 7 0 0 8 1 1 9 2 2 10 3 3 11 4 4 12 13 #更高效的方法 14 >>> pd.concat([pd.DataFrame([i], columns=[\'A\']) for i in range(5)], 15 ... ignore_index=True) 16 A 17 0 0 18 1 1 19 2 2 20 3 3 21 4 4
8.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds) 对于DataFrame的行或列应用某个函数
1 df1.apply(np.mean,axis=0) 2 Out[96]: 3 Open 8.026000e+00 4 High 8.086000e+00 5 Low 7.988000e+00 6 Close 8.034000e+00 7 Turnover 2.783660e+02 8 Volume 3.467196e+07 9 dtype: float64 10 11 df1.apply(np.max,axis=1) 12 Out[97]: 13 Date 14 2017-09-15 24272800.0 15 2017-09-18 24867600.0 16 2017-09-19 54253100.0 17 2017-09-20 39909700.0 18 2017-09-21 30056600.0 19 dtype: float64
9.applymap(func) 对DataFrame的元素应用某个函数
1 df1.applymap(lambda x:\'%.3f\' %x) 2 Out[100]: 3 Open High Low Close Turnover Volume 4 Date 5 2017-09-15 8.060 8.080 8.030 8.040 195.430 24272800.000 6 2017-09-18 8.050 8.130 8.030 8.060 200.760 24867600.000 7 2017-09-19 8.030 8.060 7.940 8.000 433.760 54253100.000 8 2017-09-20 7.970 8.060 7.950 8.030 319.940 39909700.000 9 2017-09-21 8.020 8.100 7.990 8.040 241.940 30056600.000
10.as_blocks()和as_matrix(),分别用于将DataFrame转化为以数据类型为键值的字典和将DataFrame转化为二维数组
1 df1.as_blocks() 2 Out[105]: 3 {\'float64\': Open High Low Close Turnover 4 Date 5 2017-09-15 8.06 8.08 8.03 8.04 195.43 6 2017-09-18 8.05 8.13 8.03 8.06 200.76 7 2017-09-19 8.03 8.06 7.94 8.00 433.76 8 2017-09-20 7.97 8.06 7.95 8.03 319.94 9 2017-09-21 8.02 8.10 7.99 8.04 241.94, \'int64\': Volume 10 Date 11 2017-09-15 24272800 12 2017-09-18 24867600 13 2017-09-19 54253100 14 2017-09-20 39909700 15 2017-09-21 30056600} 16 17 df1.as_matrix() 18 Out[106]: 19 array([[ 8.06000000e+00, 8.08000000e+00, 8.03000000e+00, 20 8.04000000e+00, 1.95430000e+02, 2.42728000e+07], 21 [ 8.05000000e+00, 8.13000000e+00, 8.03000000e+00, 22 8.06000000e+00, 2.00760000e+02, 2.48676000e+07], 23 [ 8.03000000e+00, 8.06000000e+00, 7.94000000e+00, 24 8.00000000e+00, 4.33760000e+02, 5.42531000e+07], 25 [ 7.97000000e+00, 8.06000000e+00, 7.95000000e+00, 26 8.03000000e+00, 3.19940000e+02, 3.99097000e+07], 27 [ 8.02000000e+00, 8.10000000e+00, 7.99000000e+00, 28 8.04000000e+00, 2.41940000e+02, 3.00566000e+07]])
11.asfreq(freq, method=None, how=None, normalize=False, fill_value=None),将时间序列转化为特定的频度
1 #创建一个具有4个分钟时间戳的序列 2 >>> index=pd.date_range(\'1/1/2017\',periods=4,freq=\'T\') 3 >>> series=pd.Series([0.0,None,2.0,3.0],index=index) 4 >>> df=pd.DataFrame({\'S\':series}) 5 >>> df 6 S 7 2017-01-01 00:00:00 0.0 8 2017-01-01 00:01:00 NaN 9 2017-01-01 00:02:00 2.0 10 2017-01-01 00:03:00 3.0 11 12 #将序列升采样以30秒为间隔的时间序列 13 >>> df.asfreq(freq=\'30S\') 14 S 15 2017-01-01 00:00:00 0.0 16 2017-01-01 00:00:30 NaN 17 2017-01-01 00:01:00 NaN 18 2017-01-01 00:01:30 NaN 19 2017-01-01 00:02:00 2.0 20 2017-01-01 00:02:30 NaN 21 2017-01-01 00:03:00 3.0 22 23 #再次升采样,并将填充值设为5.0,可以发现并不改变升采样之前的数值 24 >>> df.asfreq(freq=\'30S\',fill_value=5.0) 25 S 26 2017-01-01 00:00:00 0.0 27 2017-01-01 00:00:30 5.0 28 2017-01-01 00:01:00 NaN 29 2017-01-01 00:01:30 5.0 30 2017-01-01 00:02:00 2.0 31 2017-01-01 00:02:30 5.0 32 2017-01-01 00:03:00 3.0 33 34 #再次升采样,提供一个方法,对于空值,用后面的一个值填充 35 >>> df.asfreq(freq=\'30S\',method=\'bfill\') 36 S 37 2017-01-01 00:00:00 0.0 38 2017-01-01 00:00:30 NaN 39 2017-01-01 00:01:00 NaN 40 2017-01-01 00:01:30 2.0 41 2017-01-01 00:02:00 2.0 42 2017-01-01 00:02:30 3.0 43 2017-01-01 00:03:00 3.0
12.asof(where, subset=None),返回非空的行
1 >>> df.asof(index[0]) 2 S 0.0 3 Name: 2017-01-01 00:00:00, dtype: float64 4 5 >>> df.asof(index) 6 S 7 2017-01-01 00:00:00 0.0 8 2017-01-01 00:01:00 0.0 9 2017-01-01 00:02:00 2.0 10 2017-01-01 00:03:00 3.0
13.assign(**kwargs),向DataFrame添加新的列,返回一个新的对象包括了原来的列和新增加的列
1 >>> df=pd.DataFrame({\'A\':range(1,11),\'B\':np.random.randn(10)}) 2 >>> df 3 A B 4 0 1 0.540750 5 1 2 0.099605 6 2 3 0.165043 7 3 4 -1.379514 8 4 5 0.357865 9 5 6 -0.060789 10 6 7 -0.544788 11 7 8 -0.347995 12 8 9 0.372269 13 9 10 -0.212716 14 15 >>> df.assign(ln_A=lambda x:np.log(x.A)) 16 A B ln_A 17 0 1 0.540750 0.000000 18 1 2 0.099605 0.693147 19 2 3 0.165043 1.098612 20 3 4 -1.379514 1.386294 21 4 5 0.357865 1.609438 22 5 6 -0.060789 1.791759 23 6 7 -0.544788 1.945910 24 7 8 -0.347995 2.079442 25 8 9 0.372269 2.197225 26 9 10 -0.212716 2.302585 27 28 #每次只能添加一列,之前添加的列会被覆盖 29 >>> df.assign(abs_B=lambda x:np.abs(x.B)) 30 A B abs_B 31 0 1 0.540750 0.540750 32 1 2 0.099605 0.099605 33 2 3 0.165043 0.165043 34 3 4 -1.379514 1.379514 35 4 5 0.357865 0.357865 36 5 6 -0.060789 0.060789 37 6 7 -0.544788 0.544788 38 7 8 -0.347995 0.347995 39 8 9 0.372269 0.372269 40 9 10 -0.212716 0.212716
14.astype(dtype, copy=True, errors=\'raise\', **kwargs) 将pandas对象数据类型设置为指定类型
1 >>> ser=pd.Series([5,6],dtype=\'int32\') 2 >>> ser 3 0 5 4 1 6 5 dtype: int32 6 >>> ser.astype(\'int64\') 7 0 5 8 1 6 9 dtype: int64 10 11 #转换为类目类型 12 >>> ser.astype(\'category\') 13 0 5 14 1 6 15 dtype: category 16 Categories (2, int64): [5, 6] 17 >>> 18 19 #转换为定制化排序的类目类型 20 >>> ser.astype(\'category\',ordered=True,categories=[1,2]) 21 0 NaN 22 1 NaN 23 dtype: category 24 Categories (2, int64): [1 < 2]
15. at_time()和between_time() 取某一时刻或某段时间相应的数据
1 df1.at_time(\'9:00AM\') 2 Out[115]: 3 Empty DataFrame 4 Columns: [Open, High, Low, Close, Turnover, Volume] 5 Index: [] 6 7 df1.between_time(\'9:00AM\',\'9:30AM\') 8 Out[114]: 9 Empty DataFrame 10 Columns: [Open, High, Low, Close, Turnover, Volume] 11 Index: [] 12 13 df1.at_time(\'00:00AM\') 14 Out[116]: 15 Open High Low Close Turnover Volume 16 Date 17 2017-09-15 8.06 8.08 8.03 8.04 195.43 24272800 18 2017-09-18 8.05 8.13 8.03 8.06 200.76 24867600 19 2017-09-19 8.03 8.06 7.94 8.00 433.76 54253100 20 2017-09-20 7.97 8.06 7.95 8.03 319.94 39909700 21 2017-09-21 8.02 8.10 7.99 8.04 241.94 30056600
16.bfill(axis=None, inplace=False, limit=None, downcast=None)和fillna(method=\'bfill\')效用等同
1 >>> df.bfill() 2 S 3 2017-01-01 00:00:00 0.0 4 2017-01-01 00:01:00 2.0 5 2017-01-01 00:02:00 2.0 6 2017-01-01 00:03:00 3.0 7 >>> df.fillna(method=\'bfill\') 8 S 9 2017-01-01 00:00:00 0.0 10 2017-01-01 00:01:00 2.0 11 2017-01-01 00:02:00 2.0 12 2017-01-01 00:03:00 3.0
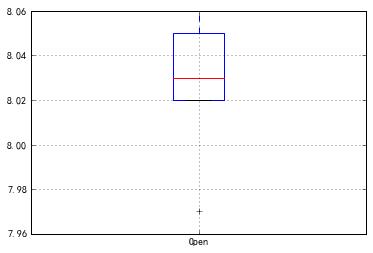
17.boxplot(column=None, by=None, ax=None, fontsize=None, rot=0, grid=True, figsize=None, layout=None, return_type=None, **kwds)
根据DataFrame的列元素或者可选分组绘制箱线图
1 df1.boxplot(\'Open\') 2 Out[117]: <matplotlib.axes._subplots.AxesSubplot at 0x20374716860>
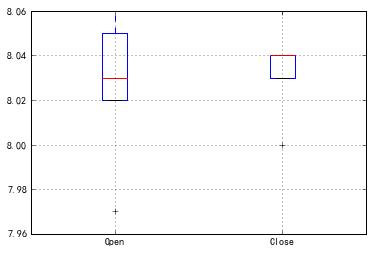
1 df1.boxplot([\'Open\',\'Close\']) 2 Out[118]: <matplotlib.axes._subplots.AxesSubplot at 0x2037477da20>
以上是关于pandas.DataFrame学习系列2——函数方法的主要内容,如果未能解决你的问题,请参考以下文章