抓取指定博客的内容
Posted 天行健,君子以自强不息
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了抓取指定博客的内容相关的知识,希望对你有一定的参考价值。
1.指定博客的地址
周国平的博客地址:http://blog.sina.com.cn/s/articlelist_1193111400_0_1.html
打开上述链接,然后按F12,找到<a title="" target="_blank" href="http://blog.sina.com.cn/s/blog_471d6f680102x7cu.html">太现实的爱情算不上爱情</a>
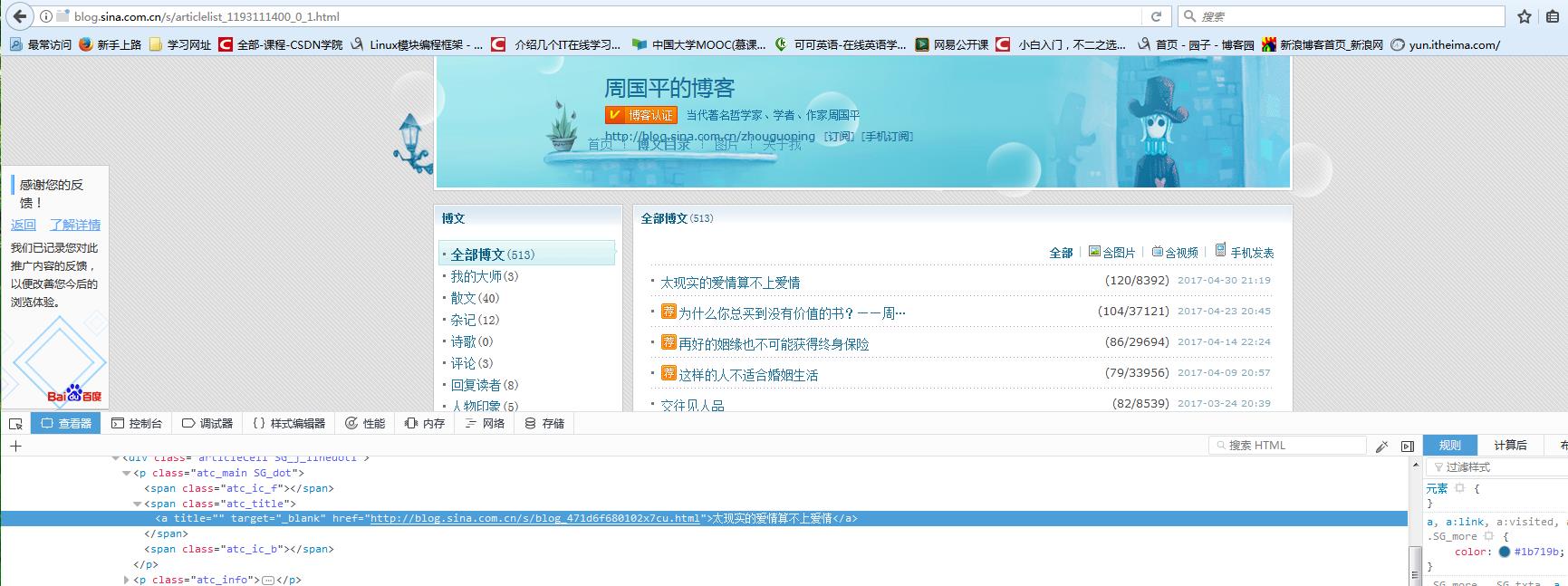
2.代码的实现
指定的网址为:http://blog.sina.com.cn/s/blog_471d6f680102x7cu.html
<a title="" target="_blank" href="http://blog.sina.com.cn/s/blog_471d6f680102x7cu.html">太现实的爱情算不上爱情</a>
在上述中我们已经将要指定网址的地址从总的html中找到了,不过这个指定网址还是在标签中
import urllib str = \'<a title="" target="_blank" href="http://blog.sina.com.cn/s/blog_471d6f680102x7cu.html">太现实的爱情算不上爱情</a>\' title = str.find(r\'<a title\') print title herf = str.find(r\'href=\') print herf html = str.find(r\'.html\') print html ##获取网址 url = str0[herf +6 :html+5] print url content = urllib.urlopen(url).read() ##访问地址并读取其内容 filename = url[-26:] print filename open(filename,\'w\').write(content)
3.抓取指定博客内容总结
- 获取网址
- 读取网址的内容
- 并将网址的内容写到一个文件中
4.python小只是扩展及说明
- find的用法
find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回第一次出现的索引值,否则返回-1。
- 网页的读取
urllib.urlopen(url).read()
- 文件的写入
open(filename,\'w\').write(content)
以上是关于抓取指定博客的内容的主要内容,如果未能解决你的问题,请参考以下文章