磁盘IO高和线程切换过高性能压测案例分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了磁盘IO高和线程切换过高性能压测案例分析相关的知识,希望对你有一定的参考价值。
案例现象:
压力测试的时候,发现A请求压力80tps后,cpu占用就非常高了(24核的机器,每个cpu占用率全面飙到80%以上),且设置的检查点没有任何报错。
1、top命令如下:
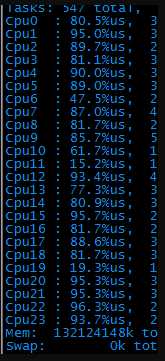
2、 了解了一下后台实现逻辑:大体是这样的:服务器接到请求后,会再到另一台kv服务器请求数据,拿回来数据后,根据用户的机器码做个性化运算,最后将结果返回给客户端,期间会输出一些调试log。
查了下,kv服务器正常,说明是本机服务服务器的问题。具体用vmstat命令看一下异常的地方。
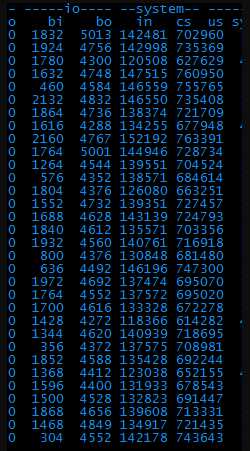
3、 从图中可以直观的看出,bi、bo、in、cs这四项的值都很高,根据经验,bi和bo代表磁盘io相关、in和cs代表系统进程相关。一个一个解决吧,先看io。
4、 用iostat –x命令看了下磁盘读写,果然,磁盘慢慢给堵死了。

5、 看了下过程,只有写log操作才能导致频繁读写磁盘。果断关闭log。重新打压试下。
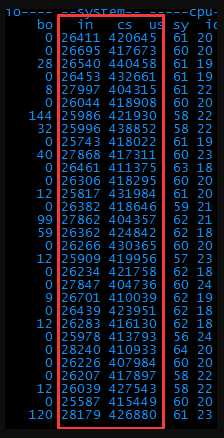
6、 Bi和bo降到正常值了,说明磁盘的问题解决了。但是上下文切换数竟然达到了每秒40万次!好可怕~
7、 只知道上下文切换数很大,怎么知道是在哪些进程间切换呢?
到网上搜了一个脚本,这个脚本用来统计特定时间内进程切换的top20并打印出来。
#! /usr/bin/env stap # # global csw_count global idle_count probe scheduler.cpu_off { csw_count[task_prev, task_next]++ idle_count+=idle } function fmt_task(task_prev, task_next) { return sprintf("%s(%d)->%s(%d)", task_execname(task_prev), task_pid(task_prev), task_execname(task_next), task_pid(task_next)) } function print_cswtop () { printf ("%45s %10s\\n", "Context switch", "COUNT") foreach ([task_prev, task_next] in csw_count- limit 20) { printf("%45s %10d\\n", fmt_task(task_prev, task_next), csw_count[task_prev, task_next]) } printf("%45s %10d\\n", "idle", idle_count) delete csw_count delete idle_count } probe timer.s($1) { print_cswtop () printf("--------------------------------------------------------------\\n") }
保存成cs.stp后,用stap cswmon.stp 5命令执行下。
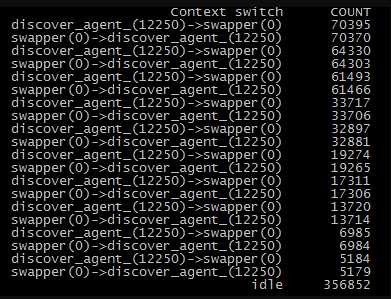
8、发现是discover进程在反复和系统进程进行切换。从此消耗了大量资源。
9、从网上查了下减少切换进程的一些方法:

开发随后改了下:将线程数开大了一倍,控制在一个进程中。
重新打压了一下。发现上下文切换数降低到25万次左右。
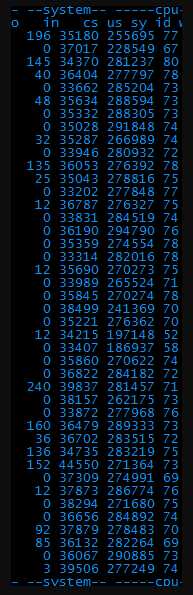
此时的性能数据可以达到每秒260次左右,远远高于之前的80次。已经达到可以上线的需求。
但是由于页面中断书和上下文切换数还是很高,后续还是需要优化
以上是关于磁盘IO高和线程切换过高性能压测案例分析的主要内容,如果未能解决你的问题,请参考以下文章