第十五篇:装饰器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十五篇:装饰器相关的知识,希望对你有一定的参考价值。
要想理解装饰器,先理解几个内容:作用域、函数即"对象"、嵌套函数和闭包
作用域
全局变量
1、在一个模块中最高级别的变量有全局作用域
2、全局变量的一个特征是除非被删除掉,否则它们的存活到脚本运行结束,且对于所有的函数,他们的值都是可以被访问的
例子1:

# 定义全局变量
a = 100
def test1():
print(a)
def test2():
print(a)
# 调用函数
test1()
test2()
执行结果:
100
100
局部变量
1、定义在函数内的变量有局部作用域
2、局部变量只时暂时地存在,仅仅只依赖于定义它们的函数现阶段是否处于活动
3、当一个函数调用出现时,其局部变量就进入声明它们的作用域。在那一刻,一个新的局部变量名为那个对象创建了
4、一旦函数完成,框架被释放,变量将会离开作用域
5、如果局部与全局有相同名称的变量,那么函数运行时,局部变量的名称将会把全局变量名称遮盖住
>>> x = 4
>>> def foo():
... x = 10
... print ‘in foo, x =‘, x
...
>>> foo()
in foo, x = 10
>>> print ‘in main, x =‘, x
in main, x = 4
核心笔记:搜索标识符
1、当搜索一个标识符的时候,python 先从局部作用域开始搜索
2、如果在局部作用域内没有找到那个名字,那么就一定会在全局域找到这个变量否则就会被抛出 NameError 异常
3、一个变量的作用域和它寄住的名字空间相关
global语句
1、因为全局变量的名字能被局部变量给遮盖掉,所以为了明确地引用一个已命名的全局变量,必须使用global语句
2、global 的语法如下 :global var1[, var2[, ... varN]]]
3、如果在函数中修改全局变量,那么就需要使用global进行声明,否则出错
>>> x = 4
>>> def foo():
... global x
... x = 10
... print ‘in foo, x =‘, x
...
>>> foo()
in foo, x = 10
>>> print ‘in main, x =‘, x
in main, x = 10
例子
>>> a = 1
>>> def f():
... a += 1
... print a
...
>>> f()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in f
UnboundLocalError: local variable ‘a‘ referenced before assignment
>>>
>>>
>>> li = [1,]
>>> def f2():
... li.append(1)
... print li
...
>>> f2()
[1, 1]
>>> li
[1, 1]
总结:
1.在函数中不使用global声明全局变量时不能修改全局变量的本质是不能修改全局变量的指向,即不能将全局变量指向新的数据。
2.对于不可变类型的全局变量来说,因其指向的数据不能修改,所以不使用global时无法修改全局变量。
3.对于可变类型的全局变量来说,因其指向的数据可以修改,所以不使用global时也可修改全局变量
名字空间
1、任何时候,总有一个到三个活动的作用域(内建、全局和局部)
2、标识符的搜索顺序依次是局部、全局和内建
3、提到名字空间,可以想像是否有这个标识符
4、提到变量作用域,可以想像是否可以“看见”这个标识符
函数即"对象"
在python的世界里,函数和我们之前的[1,2,3],‘abc‘,8等一样都是对象,而且函数是最高级的对象(对象是类的实例化,可以调用相应的方法,函数是包含变量对象的对象)
def foo():
print(‘i am the foo‘)
bar()
def bar():
print(‘i am the bar‘)
foo()
函数对象的调用仅仅比其它对象多了一个()而已!foo,bar与a,b一样都是个变量名。
那上面的问题也就解决了,只有函数加载到内存才可以被调用。
既然函数是对象,那么自然满足下面两个条件:
1. 其可以被赋给其他变量
def foo(): print(‘foo‘) bar=foo bar() foo() print(id(foo),id(bar)) #4321123592 4321123592
2. 其可以被定义在另外一个函数内(作为参数&作为返回值),类似于整形,字符串等对象。
#*******函数名作为参数********** def foo(func): print(‘foo‘) func() def bar(): print(‘bar‘) foo(bar) #*******函数名作为返回值********* def foo(): print(‘foo‘) return bar def bar(): print(‘bar‘) b=foo() b()
注意:这里说的函数都是指函数名,比如foo;而foo()已经执行函数了,foo()是什么类型取决于return的内容是什么类型!!!
另外,如果大家理解不了对象,那么就将函数理解成变量,因为函数对象总会由一个或多个变量引用,比如foo,bar。
函数的嵌套和闭包
嵌套
先看一个例子
def foo(): print(‘foo‘) def bar(): print(‘bar‘) # bar() bar()
是的,bar就是一个变量名,有自己的作用域的。
Python允许创建嵌套函数。嵌套函数的方法是在外部函数的定义体内定义函数(用 def 关键字)
嵌套函数一个有趣的方面在于整个函数体都在外部函数的作用域之内
一个函数里面又调用了另外一个函数,这就是所谓的函数嵌套调用
#想执行inner函数,两种方法 def outer(): x = 1 def inner(): print (x) # 1 # inner() # 2 return inner # outer() in_func=outer() in_func()
问题1:两种调用方式有区别吗,不都是在外面调用inner吗?
in_func=outer()
in_func()
###########
inner()(已经加载到内存啦)
原因:
def outer(): x = 1 def inner(): b=6 print (x) return inner #inner()#报错原因:找不到这个引用变量 in_func=outer()#这里其实就是一个变量赋值,将inner的引用对象赋值给in_func,类似于a=5,b=a一样 #有同学会想直接赋值不行吗:in_func=inner? 哥,inner不还是找不到吗,对吧 in_func()
问题2:函数调用后就被销毁
def outer(): x=1 #函数outer执行
完毕即被销毁 print(x)
既然这样,inner()执行的时候outer函数已经执行完了,为什么inner还可以调用outer里的变量x呢?
这就涉及到我们叫讲的闭包啦!
因为:outer里return的inner是一个闭包函数,有x这个环境变量。
闭包
1、如果在一个嵌套函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是closure ,即闭包
2、定义在外部函数内的但由嵌套函数引用或者使用的变量被称为自由变量
3、闭包将嵌套函数自己的代码和作用域以及外部函数的作用结合起来
4、闭包的词法变量不属于全局名字空间域或者局部的,而属于其他的名字空间,带着“流浪"的作用域
5、闭包对于安装计算,隐藏状态,以及在函数对象和作用域中随意地切换是很有用的
6、闭包也是函数,但是他们能携带一些额外的作用域
如上实例,inner就是内部函数,inner里引用了外部作用域的变量x(x在外部作用域outer里面,不是全局作用域),
则这个内部函数inner就是一个闭包。
再稍微讲究一点的解释是,闭包=函数块+定义函数时的环境,inner就是函数块,x就是环境,当然这个环境可以有很多,不止一个简单的x。
print(in_func.__closure__[0].cell_contents)
用途1:
# 用途1:当闭包执行完后,仍然能够保持住当前的运行环境。 # 比如说,如果你希望函数的每次执行结果,都是基于这个函数上次的运行结果。我以一个类似棋盘游戏的例子 # 来说明。假设棋盘大小为50*50,左上角为坐标系原点(0,0),我需要一个函数,接收2个参数,分别为方向 # (direction),步长(step),该函数控制棋子的运动。棋子运动的新的坐标除了依赖于方向和步长以外, # 当然还要根据原来所处的坐标点,用闭包就可以保持住这个棋子原来所处的坐标。 origin = [0, 0] # 坐标系统原点 legal_x = [0, 50] # x轴方向的合法坐标 legal_y = [0, 50] # y轴方向的合法坐标 def create(pos=origin): def player(direction,step): # 这里应该首先判断参数direction,step的合法性,比如direction不能斜着走,step不能为负等 # 然后还要对新生成的x,y坐标的合法性进行判断处理,这里主要是想介绍闭包,就不详细写了。 new_x = pos[0] + direction[0]*step new_y = pos[1] + direction[1]*step pos[0] = new_x pos[1] = new_y #注意!此处不能写成 pos = [new_x, new_y],原因在上文有说过 return pos return player player = create() # 创建棋子player,起点为原点 print (player([1,0],10)) # 向x轴正方向移动10步 print (player([0,1],20)) # 向y轴正方向移动20步 print (player([-1,0],10)) # 向x轴负方向移动10步
用途2:
# 用途2:闭包可以根据外部作用域的局部变量来得到不同的结果,这有点像一种类似配置功能的作用,我们可以 # 修改外部的变量,闭包根据这个变量展现出不同的功能。比如有时我们需要对某些文件的特殊行进行分析,先 # 要提取出这些特殊行。 def make_filter(keep): def the_filter(file_name): file = open(file_name) lines = file.readlines() file.close() filter_doc = [i for i in lines if keep in i] return filter_doc return the_filter # 如果我们需要取得文件"result.txt"中含有"pass"关键字的行,则可以这样使用例子程序 filter = make_filter("pass") filter_result = filter("result.txt")
装饰器
装饰器本质上是一个函数,该函数用来处理其他函数,它可以让其他函数在不需要修改代码的前提下增加额外的功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等应用场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
装饰器概念
1、装饰器是在函数调用之上的修饰。这些修饰仅是当声明一个函数或者方法的时候,才会应用的额外调用
2、装饰器的语法以@开头,接着是装饰器函数的名字和可选的参数。紧跟着装饰器声明的是被修饰的函数,和装饰函数的可选参数
3、装饰器看起来会是这样
@deco(dec_opt_args)
def func(func_opt_args):
4、装饰器还可以堆叠,实现多装饰器
@deco2
@deco1
def func(arg1, arg2, ...): pass
这等同于:
def func(arg1, arg2, ...): pass
func = deco2(deco1(func))
没有参数的装饰器:
@deco
def foo(): pass
等同于:
foo = deco(foo)
带参数的装饰器
@decomaker(deco_args)
def foo(): pass
要自己返回以函数作为参数的装饰器。换句话说,decomaker()用 deco_args 做了些事并返回函数对象,而该函数对象正是以 foo 作为其参数的装饰器。
简单的说来:
foo = decomaker(deco_args)(foo)
多装饰器例子:
@deco1(deco_arg)
@deco2
def func(): pass
等同于:
func = deco1(deco_arg)(deco2(func))
简单装饰器
业务生产中大量调用的函数
def foo(): print(‘hello foo‘) foo()
现在有一个新的需求,希望可以记录下函数的执行时间,于是在代码中添加日志代码:
import time def foo(): start_time=time.time() print(‘hello foo‘) time.sleep(3) end_time=time.time() print(‘spend %s‘%(end_time-start_time)) foo()
bar()、bar2()也有类似的需求,怎么做?再在bar函数里调用时间函数?这样就造成大量雷同的代码,为了减少重复写代码,我们可以这样做,重新定义一个函数:专门设定时间:
import time def show_time(func): start_time=time.time() func() end_time=time.time() print(‘spend %s‘%(end_time-start_time)) def foo(): print(‘hello foo‘) time.sleep(3) show_time(foo)
逻辑上不难理解,而且运行正常。 但是这样的话,你基础平台的函数修改了名字,容易被业务线的人投诉的,因为我们每次都要将一个函数作为参数传递给show_time函数。而且这种方式已经破坏了原有的代码逻辑结构,之前执行业务逻辑时,执行运行foo(),但是现在不得不改成show_time(foo)。那么有没有更好的方式的呢?当然有,答案就是装饰器。
如果能够做到:
foo()==show_time(foo) :问题就解决了!
所以,我们需要show_time(foo)返回一个函数对象,而这个函数对象内则是核心业务函数:执行func()与装饰函数时间计算,修改如下:
import time def show_time(func): def wrapper(): start_time=time.time() func() end_time=time.time() print(‘spend %s‘%(end_time-start_time)) return wrapper def foo(): print(‘hello foo‘) time.sleep(3) foo=show_time(foo) foo()
函数show_time就是装饰器,它把真正的业务方法func包裹在函数里面,看起来像foo被上下时间函数装饰了。在这个例子中,函数进入和退出时 ,被称为一个横切面(Aspect),这种编程方式被称为面向切面的编程(Aspect-Oriented Programming)。
@符号是装饰器的语法糖,在定义函数的时候使用,避免再一次赋值操作
import time def show_time(func): def wrapper(): start_time=time.time() func() end_time=time.time() print(‘spend %s‘%(end_time-start_time)) return wrapper @show_time #foo=show_time(foo) def foo(): print(‘hello foo‘) time.sleep(3) @show_time #bar=show_time(bar) def bar(): print(‘in the bar‘) time.sleep(2) foo() print(‘***********‘) bar()
如上所示,这样我们就可以省去bar = show_time(bar)这一句了,直接调用bar()即可得到想要的结果。如果我们有其他的类似函数,我们可以继续调用装饰器来修饰函数,而不用重复修改函数或者增加新的封装。这样,我们就提高了程序的可重复利用性,并增加了程序的可读性。
这里需要注意的问题: foo=show_time(foo)其实是把wrapper引用的对象引用给了foo,而wrapper里的变量func之所以可以用,就是因为wrapper是一个闭包函数。
这个要留意一下:
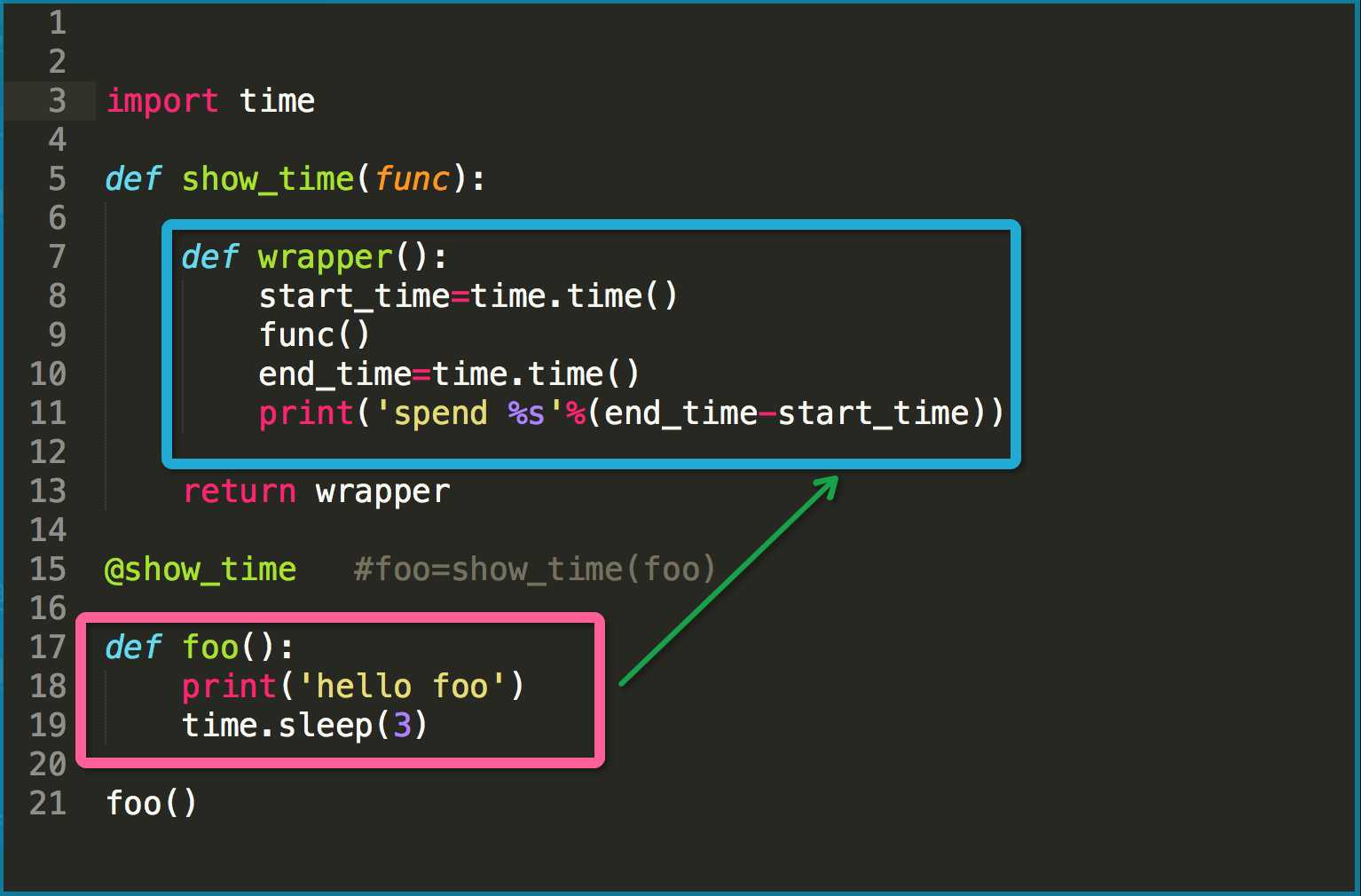
@show_time帮我们做的事情就是当我们执行业务逻辑foo()时,执行的代码由粉框部分转到蓝框部分,仅此而已!
装饰器在Python使用如此方便都要归因于Python的函数能像普通的对象一样能作为参数传递给其他函数,可以被赋值给其他变量,可以作为返回值,可以被定义在另外一个函数内。
带参数的被装饰函数
import time def show_time(func): def wrapper(a,b): start_time=time.time() func(a,b) end_time=time.time() print(‘spend %s‘%(end_time-start_time)) return wrapper @show_time #add=show_time(add) def add(a,b): time.sleep(1) print(a+b) add(2,4)
注意点:
import time def show_time(func): def wrapper(a,b): start_time=time.time() ret=func(a,b) end_time=time.time() print(‘spend %s‘%(end_time-start_time)) return ret return wrapper @show_time #add=show_time(add) def add(a,b): time.sleep(1) return a+b print(add(2,5))
不定长参数
#***********************************不定长参数 import time def show_time(func): def wrapper(*args,**kwargs): start_time=time.time() func(*args,**kwargs) end_time=time.time() print(‘spend %s‘%(end_time-start_time)) return wrapper @show_time #add=show_time(add) def add(*args,**kwargs): time.sleep(1) sum=0 for i in args: sum+=i print(sum) add(2,4,8,9)
带参数的装饰器
装饰器还有更大的灵活性,例如带参数的装饰器:在上面的装饰器调用中,比如@show_time,该装饰器唯一的参数就是执行业务的函数。装饰器的语法允许我们在调用时,提供其它参数,比如@decorator(a)。这样,就为装饰器的编写和使用提供了更大的灵活性。
import time def time_logger(flag=0): def show_time(func): def wrapper(*args,**kwargs): start_time=time.time() func(*args,**kwargs) end_time=time.time() print(‘spend %s‘%(end_time-start_time)) if flag: print(‘将这个操作的时间记录到日志中‘) return wrapper return show_time @time_logger(3) def add(*args,**kwargs): time.sleep(1) sum=0 for i in args: sum+=i print(sum) add(2,7,5)
@time_logger(3) 做了两件事:
(1)time_logger(3):得到闭包函数show_time,里面保存环境变量flag
(2)@show_time :add=show_time(add)
上面的time_logger是允许带参数的装饰器。它实际上是对原有装饰器的一个函数封装,并返回一个装饰器(一个含有参数的闭包函数)。当我 们使用@time_logger(3)调用的时候,Python能够发现这一层的封装,并把参数传递到装饰器的环境中。
多层装饰器
def makebold(fn): def wrapper(): return "<b>" + fn() + "</b>" return wrapper def makeitalic(fn): def wrapper(): return "<i>" + fn() + "</i>" return wrapper @makebold @makeitalic def hello(): return "hello alvin" hello()
过程如下:
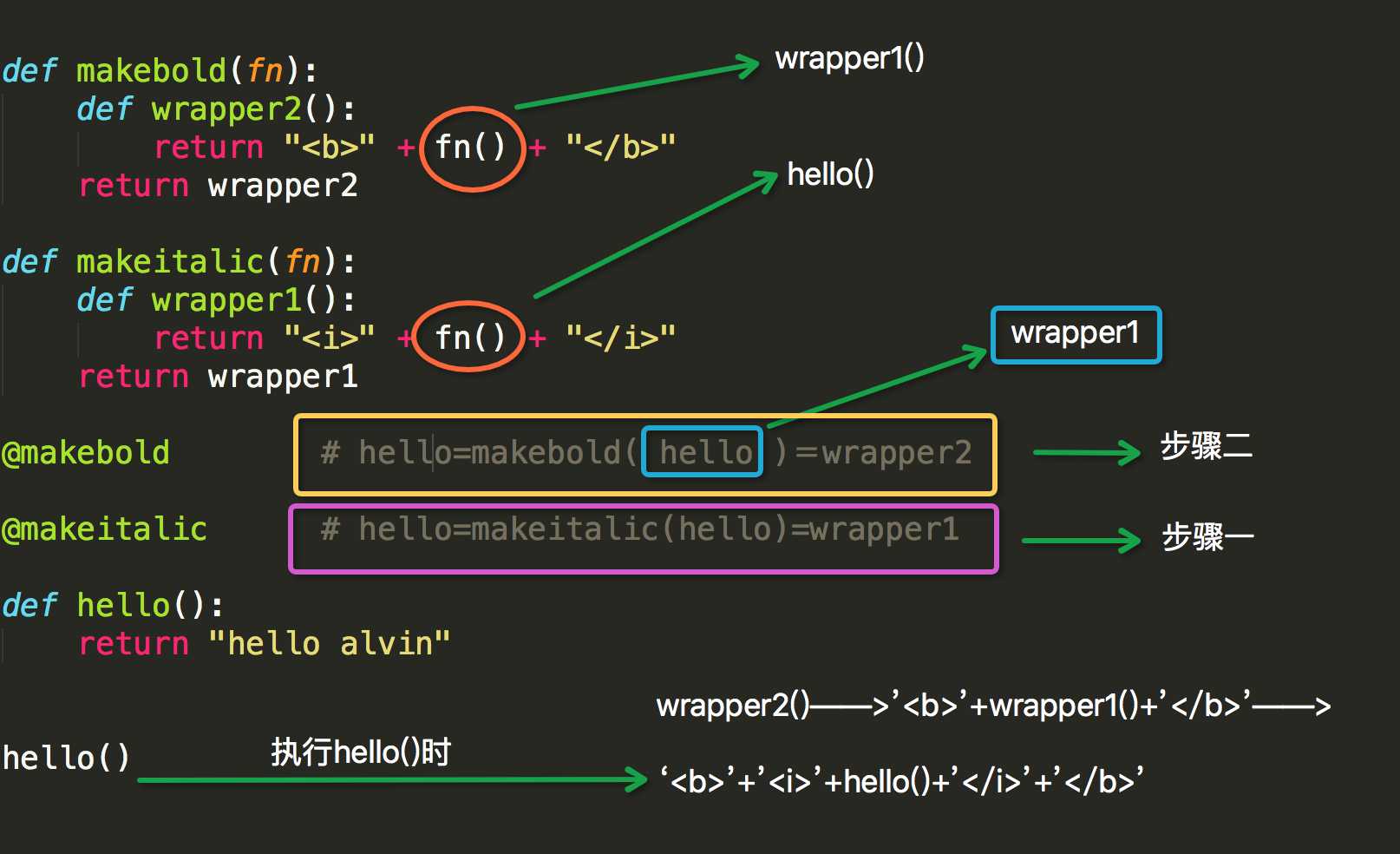
类装饰器
来看看类装饰器,相比函数装饰器,类装饰器具有灵活度大、高内聚、封装性等优点。使用类装饰器还可以依靠类内部的__call__方法,当使用 @ 形式将装饰器附加到函数上时,就会调用此方法。
import time class Foo(object): def __init__(self, func): self._func = func def __call__(self): start_time=time.time() self._func() end_time=time.time() print(‘spend %s‘%(end_time-start_time)) @Foo #bar=Foo(bar) def bar(): print (‘bar‘) time.sleep(2) bar() #bar=Foo(bar)()>>>>>>>没有嵌套关系了,直接active Foo的 __call__方法
functools.wraps
使用装饰器极大地复用了代码,但是他有一个缺点就是原函数的元信息不见了,比如函数的docstring、__name__、参数列表,先看例子:
def foo(): print("hello foo") print(foo.__name__) ##################### def logged(func): def wrapper(*args, **kwargs): print (func.__name__ + " was called") return func(*args, **kwargs) return wrapper @logged def cal(x): return x + x * x print(cal.__name__) ######## # foo # wrapper
解释:
@logged def f(x): return x + x * x
等价于:
ef f(x): return x + x * x f = logged(f)
不难发现,函数f被wrapper取代了,当然它的docstring,__name__就是变成了wrapper函数的信息了。
print f.__name__ # prints ‘wrapper‘ print f.__doc__ # prints None
这个问题就比较严重的,好在我们有functools.wraps,wraps本身也是一个装饰器,它能把原函数的元信息拷贝到装饰器函数中,
这使得装饰器函数也有和原函数一样的元信息了。
from functools import wraps def logged(func): @wraps(func) def wrapper(*args, **kwargs): print (func.__name__ + " was called") return func(*args, **kwargs) return wrapper @logged def cal(x): return x + x * x print(cal.__name__) #cal
内置装饰器
@staticmathod
@classmethod
@property
补充
##----------------------------------------foo函数先加载到内存,然后foo变量指向新的引用,所以递归里的foo是wrapper函数对象 # def show_time(func): # # def wrapper(n): # ret=func(n) # print("hello,world") # return ret # return wrapper # # @show_time# foo=show_time(foo) # def foo(n): # if n==1: # return 1 # return n*foo(n-1) # print(foo(6)) ######################## def show_time(func): def wrapper(n): ret=func(n) print("hello,world") return ret return wrapper @show_time# foo=show_time(foo) def foo(n): def _foo(n): if n==1: return 1 return n*_foo(n-1) return _foo(n) print(foo(6))
参考:http://www.cnblogs.com/yuanchenqi/articles/5830025.html
以上是关于第十五篇:装饰器的主要内容,如果未能解决你的问题,请参考以下文章