models之查询
Posted xiesibo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了models之查询相关的知识,希望对你有一定的参考价值。
普同查询:
双下划线的使用
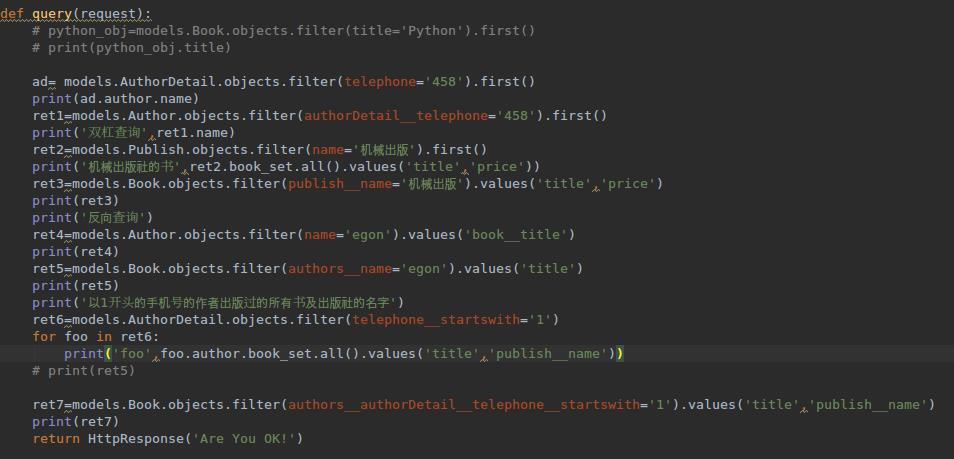


1 from django.shortcuts import render,HttpResponse 2 3 # Create your views here. 4 from app01 import models 5 6 def query(request): 7 # python_obj=models.Book.objects.filter(title=\'Python\').first() 8 # print(python_obj.title) 9 10 ad= models.AuthorDetail.objects.filter(telephone=\'458\').first() 11 print(ad.author.name) 12 ret1=models.Author.objects.filter(authorDetail__telephone=\'458\').first() 13 print(\'双杠查询\',ret1.name) 14 ret2=models.Publish.objects.filter(name=\'机械出版\').first() 15 print(\'机械出版社的书\',ret2.book_set.all().values(\'title\',\'price\')) 16 ret3=models.Book.objects.filter(publish__name=\'机械出版\').values(\'title\',\'price\') 17 print(ret3) 18 print(\'反向查询\') 19 ret4=models.Author.objects.filter(name=\'egon\').values(\'book__title\') 20 print(ret4) 21 ret5=models.Book.objects.filter(authors__name=\'egon\').values(\'title\') 22 print(ret5) 23 print(\'以1开头的手机号的作者出版过的所有书及出版社的名字\') 24 ret6=models.AuthorDetail.objects.filter(telephone__startswith=\'1\') 25 for foo in ret6: 26 print(\'foo\',foo.author.book_set.all().values(\'title\',\'publish__name\')) 27 # print(ret5) 28 29 ret7=models.Book.objects.filter(authors__authorDetail__telephone__startswith=\'1\').values(\'title\',\'publish__name\') 30 print(ret7) 31 return HttpResponse(\'Are You OK!\')
聚合查询与分组查询
什么是聚合查询?什么是分组查询?
1 聚合查询就是把具有某一个相同属性的记录将其看为一个整体并对其进行计算 2 常见的有sum avg max min 3 常见的问法是 每个XX所XX的XX的最大值,最小,平均值,和*******
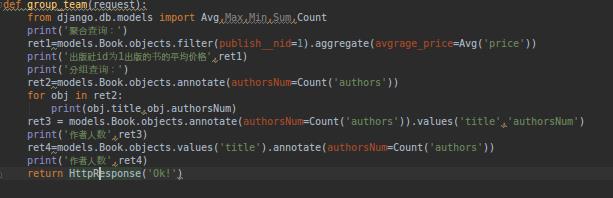
聚合:aggregate(*args, **kwargs)
|
1
2
3
4
|
# 计算所有图书的平均价格 >>> from django.db.models import Avg >>> Book.objects.all().aggregate(Avg(\'price\')) {\'price__avg\': 34.35} |
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
|
1
2
|
>>> Book.objects.aggregate(average_price=Avg(\'price\')){\'average_price\': 34.35} |
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
|
1
2
3
|
>>> from django.db.models import Avg, Max, Min>>> Book.objects.aggregate(Avg(\'price\'), Max(\'price\'), Min(\'price\')){\'price__avg\': 34.35, \'price__max\': Decimal(\'81.20\'), \'price__min\': Decimal(\'12.99\')} |
分组:annotate()
为QuerySet中每一个对象都生成一个独立的汇总值。
(1) 练习:统计每一本书的作者个数
|
1
2
3
|
bookList=Book.objects.annotate(authorsNum=Count(\'authors\'))for book_obj in bookList: print(book_obj.title,book_obj.authorsNum) |
sql(2) 如果想对所查询对象的关联对象进行聚合:
练习:统计每一个出版社的最便宜的书
|
1
2
3
4
|
publishList=Publish.objects.annotate(MinPrice=Min("book__price"))for publish_obj in publishList: print(publish_obj.name,publish_obj.MinPrice) |
annotate的返回值是querySet,如果不想遍历对象,可以用上valuelist:
queryResult= Publish.objects
.annotate(MinPrice=Min("book__price"))
.values_list("name","MinPrice")
print(queryResult)
方式2:
|
1
|
queryResult=Book.objects.values("publish__name").annotate(MinPrice=Min(\'price\')) |
注意:values内的字段即group by的字段
(3) 统计每一本以py开头的书籍的作者个数:
queryResult=Book.objects .filter(title__startswith="Py") .annotate(num_authors=Count(\'authors\'))
(4) 统计不止一个作者的图书:
queryResult=Book.objects .annotate(num_authors=Count(\'authors\')) .filter(num_authors__gt=1)
(5) 根据一本图书作者数量的多少对查询集 QuerySet进行排序:
|
1
|
Book.objects.annotate(num_authors=Count(\'authors\')).order_by(\'num_authors\') |
(6) 查询各个作者出的书的总价格:

# 按author表的所有字段 group by
queryResult=Author.objects
.annotate(SumPrice=Sum("book__price"))
.values_list("name","SumPrice")
print(queryResult)
#按authors__name group by
queryResult2=Book.objects.values("authors__name")
.annotate(SumPrice=Sum("price"))
.values_list("authors__name","SumPrice")
print(queryResult2)
F查询与Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
|
1
2
3
4
|
# 查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commnetNum__lt=F(\'keepNum\')) |
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
|
1
2
|
# 查询评论数大于收藏数2倍的书籍 Book.objects.filter(commnetNum__lt=F(\'keepNum\')*2) |
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
|
1
|
Book.objects.all().update(price=F("price")+30) |
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
|
1
2
|
from django.db.models import QQ(title__startswith=\'Py\') |
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
|
1
|
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon")) |
等同于下面的SQL WHERE 子句:
|
1
|
WHERE name ="yuan" OR name ="egon" |
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
|
1
|
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title") |
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python"
)
以上是关于models之查询的主要内容,如果未能解决你的问题,请参考以下文章