Scrapy基础01
Posted 青山应回首
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy基础01相关的知识,希望对你有一定的参考价值。
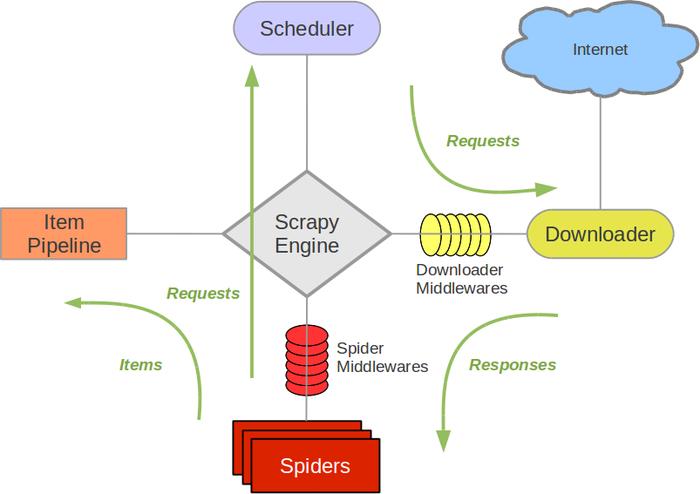
一、Scarpy简介
Scrapy基于事件驱动网络框架 Twisted 编写。(Event-driven networking)
因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
参考:武Sir笔记
参考:Scrapy架构概览
二、爬取chouti.com新闻示例
# chouti.py # -*- coding: utf-8 -*- import scrapy from scrapy.http import Request from scrapy.selector import htmlXPathSelector from ..items import Day24SpiderItem # For windows: import sys,io sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=\'gb18030\') class ChoutiSpider(scrapy.Spider): name = \'chouti\' allowed_domains = [\'chouti.com\'] start_urls = [\'http://chouti.com/\'] def parse(self, response): # print(response.body) # print(response.text) hxs = HtmlXPathSelector(response) item_list = hxs.xpath(\'//div[@id="content-list"]/div[@class="item"]\') # 找到首页所有消息的连接、标题、作业信息然后yield给pipeline进行持久化 for item in item_list: link = item.xpath(\'./div[@class="news-content"]/div[@class="part1"]/a/@href\').extract_first() title = item.xpath(\'./div[@class="news-content"]/div[@class="part2"]/@share-title\').extract_first() author = item.xpath(\'./div[@class="news-content"]/div[@class="part2"]/a[@class="user-a"]/b/text()\').extract_first() yield Day24SpiderItem(link=link,title=title,author=author) # 找到第二页、第三页、、、第十页的消息,全部爬取下来做持久化 # hxs.xpath(\'//div[@id="dig_lcpage"]//a/@href\').extract() \'\'\'或者用正则精确匹配\'\'\' page_url_list = hxs.xpath(\'//div[@id="dig_lcpage"]//a[re:test(@href,"/all/hot/recent/\\d+")]/@href\').extract() for url in page_url_list: url = "http://dig.chouti.com" + url print(url) yield Request(url, callback=self.parse, dont_filter=False)
# pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class Day24SpiderPipeline(object):
def __init__(self,file_path):
self.file_path = file_path # 文件路径
self.file_obj = None # 文件对象:用于读写操作
@classmethod
def from_crawler(cls, crawler):
"""
初始化时候,用于创建pipeline对象
:param crawler:
:return:
"""
val = crawler.settings.get(\'STORAGE_CONFIG\')
return cls(val)
def process_item(self, item, spider):
print(">>>> ",item)
if \'chouti\' == spider.name:
self.file_obj.write(item.get(\'link\') + "\\n" + item.get(\'title\') + "\\n" + item.get(\'author\') + "\\n\\n")
return item
def open_spider(self, spider):
"""
爬虫开始执行时,调用
:param spider:
:return:
"""
if \'chouti\' == spider.name:
# 如果不加:encoding=\'utf-8\' 会导致文件里中文乱码
self.file_obj = open(self.file_path,mode=\'a+\',encoding=\'utf-8\')
def close_spider(self, spider):
"""
爬虫关闭时,被调用
:param spider:
:return:
"""
if \'chouti\' == spider.name:
self.file_obj.close()
# items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class Day24SpiderItem(scrapy.Item):
link = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
# settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for day24spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = \'day24spider\'
SPIDER_MODULES = [\'day24spider.spiders\']
NEWSPIDER_MODULE = \'day24spider.spiders\'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = \'day24spider (+http://www.yourdomain.com)\'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# \'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\',
# \'Accept-Language\': \'en\',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# \'day24spider.middlewares.Day24SpiderSpiderMiddleware\': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# \'day24spider.middlewares.MyCustomDownloaderMiddleware\': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# \'scrapy.extensions.telnet.TelnetConsole\': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
\'day24spider.pipelines.Day24SpiderPipeline\': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = \'httpcache\'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = \'scrapy.extensions.httpcache.FilesystemCacheStorage\'
STORAGE_CONFIG = "chouti.json"
DEPTH_LIMIT = 1
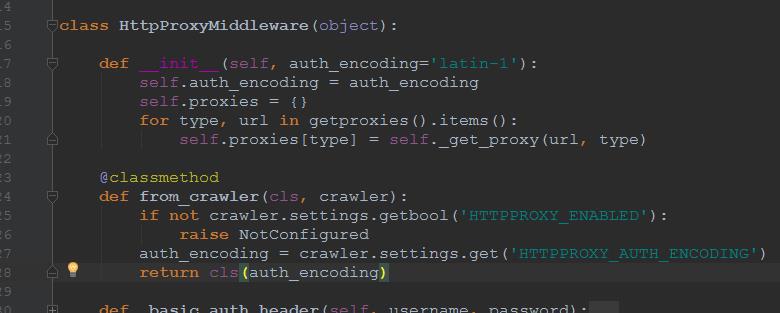
三、classmethod方法应用
from_crawler() --> __init__()
以上是关于Scrapy基础01的主要内容,如果未能解决你的问题,请参考以下文章