spark1.6.0集群安装
Posted yhao浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark1.6.0集群安装相关的知识,希望对你有一定的参考价值。
本文是对spark1.6.0分布式集群的安装的一个详细说明,旨在帮助相关人员按照本说明能够快速搭建并使用spark集群。
2. 安装环境
本安装说明的示例环境部署如下:
| IP | 外网IP | hostname | 备注 |
| 10.47.110.38 | 120.27.153.137 | iZ237654q6qZ | Master、Slaver |
| 10.24.35.51 | 114.55.56.190 | iZ23pd81xqaZ | Slaver |
| 10.45.53.136 | 114.55.11.55 | iZ23mr5ukpzZ | Slaver |
| 10.24.35.76 | 114.55.56.228 | iZ23v8c9mqpZ | Slaver |
各软件版本:
- Java:jdk-8u60-linux-x64.tar.gz
- Scala:2.10.4
- Spark:1.6.0
- Hadoop:CDH-5.4.5-1.cdh5.4.5.p0.7
3. 安装前准备
3.1 在每台机添加hosts(root用户)
修改文件/etc/hosts(或者/etc/sysconfig/network),添加以下内容:
10.47.110.38 iZ237654q6qZ
10.24.35.51 iZ23pd81xqaZ
10.45.53.136 iZ23mr5ukpzZ
10.24.35.76 iZ23v8c9mqpZ
注意:主机名必须和hosts文件中的名称保持一致!
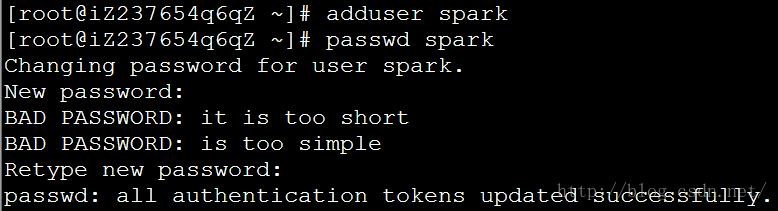
3.2 每个spark节点上创建一个用户(root用户)
# adduser spark
# passwd spark
密码统一设为:spark
3.3 每台机安装java(root用户)
3.3.1 下载java
3.3.2 解压到指定目录
# tar -zxvf jdk-8u60-linux-x64.tar.gz -C /usr/local/

建立软链接以方便以后更改java版本
# ln -sf/usr/local/jdk1.8.0_60/ /usr/local/jdk

3.3.3 配置环境变量
更改全局配置文件/etc/profile
# vim /etc/profile
在文件最后添加:
export JAVA_HOME=/usr/local/jdk //添加java home
export PATH=.:$JAVA_HOME/bin:$PATH //将scala路径添加进环境变量

注意:在修改完profile后,需要输入以下命令进行更新,否则不会立即生效:
# source /etc/profile
3.3.4 验证
输入java -version验证是否已配置成功
# java -version

3.4 每台机安装scala(root用户)
3.4.1 下载scala
下载地址:http://www.scala-lang.org/download/2.10.4.html
3.4.2 解压到指定目录
# tar -zxvf scala-2.10.4.tgz -C /usr/local/

建立软链接以方便以后更改scala版本
# ln -sf /usr/local/scala-2.10.4/ /usr/local/scala

3.4.3 配置环境变量
更改全局配置文件/etc/profile
# vim /etc/profile
在JAVA_HOME最后添加:
export SCALA_HOME=/usr/local/scala //添加scala home
更改path路径,添加scala环境
export PATH=.:$JAVA_HOME/bin: $SCALA_HOME/bin:$PATH //将scala路径添加进环境变量

注意:在修改完profile后,需要输入以下命令进行更新,否则不会立即生效:
# source /etc/profile
3.4.4 验证
输入scala -version验证是否已配置成功
# scala -version

3.5 每台机安装ssh并配置无密码连接(安装openssh使用root,其他使用spark)
3.5.1 安装openssh
# yum install -y openssh-server

注意:从这里开始使用spark用户,执行命令su - spark切换到spark用户
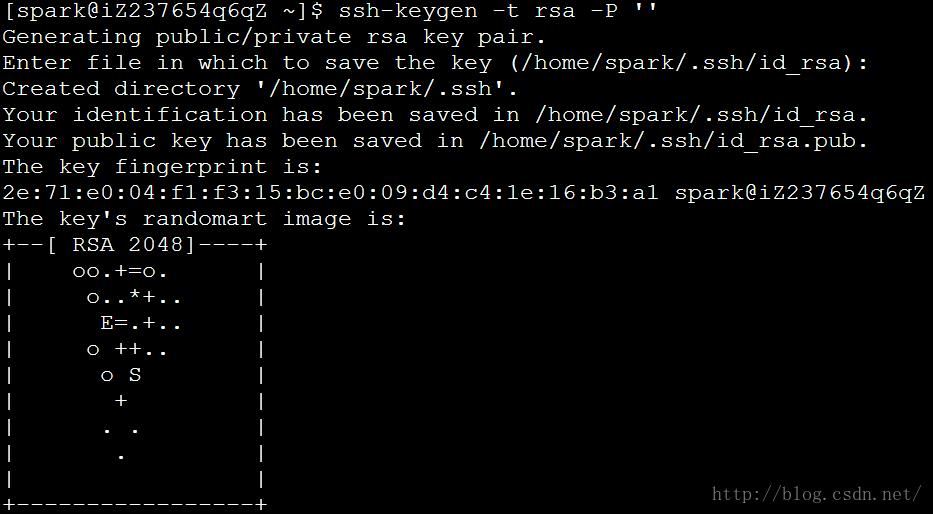
3.5.2 生成密钥
# ssh-keygen -t rsa -P ‘‘(然后回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
3.5.3 分享公钥到其他主机
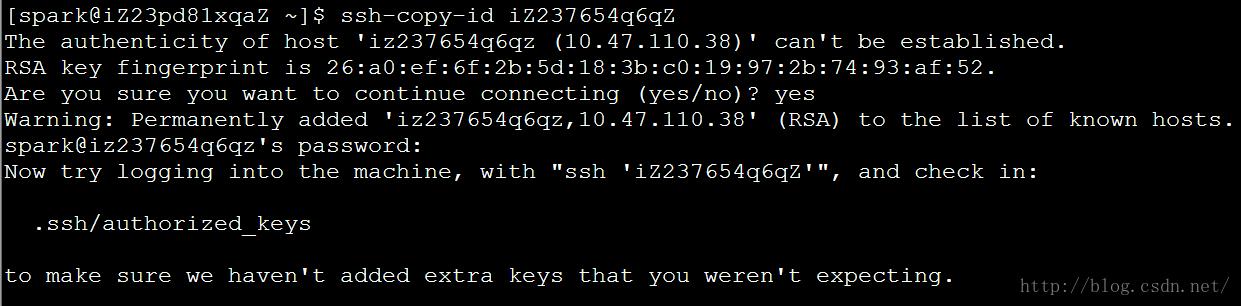
在每台机上将公钥拷贝到要免登陆的机器上
# ssh-copy-id iZ237654q6qZ
# ssh-copy-id iZ23pd81xqaZ
# ssh-copy-id iZ23mr5ukpzZ
# ssh-copy-id iZ23v8c9mqpZ
3.5.4 验证是否免密码
输入以下命令,如果没有提示输入密码就直接登入,则配置成功:
# ssh iZ23mr5ukpzZ

验证成功后退出登录:
# exit

3.6 每台机关闭防火墙等服务(root)
# service iptables stop
# chkconfig iptables off //关闭开机启动防火墙
4 spark部署(spark用户)
4.1 下载spark
下载地址:http://mirrors.hust.edu.cn/apache/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
4.2 配置spark环境变量
解压到/home/spark目录
$ tar -zxvfspark-1.6.0-bin-hadoop2.6.tgz
建立软链接
$ ln -sf spark-1.6.0-bin-hadoop2.6spark

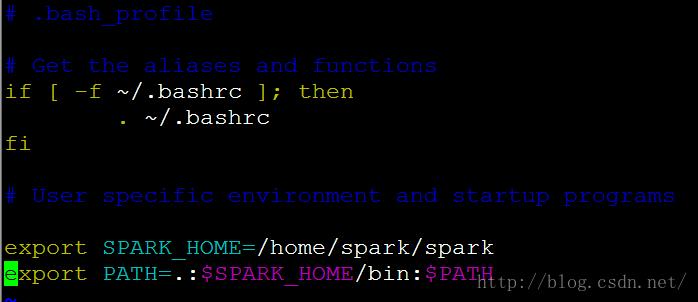
配置环境变量,编辑/home/spark目录下的bash_profile
$ vim ~/.bash_profile
添加以下两行(如果原来里面最后有path相关的两行,先删掉):
export SPARK_HOME=/home/spark/spark
export PATH=.:$SPARK_HOME/bin:$PATH
配置完成后同样的source以下,使之生效
$ source ~/.bash_profile
4.3 配置spark
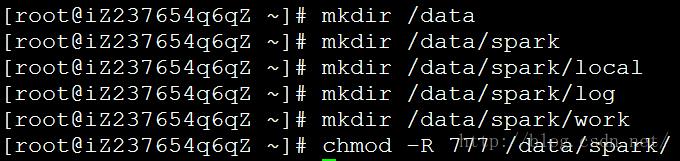
首先新建好spark用到的目录(使用root用户,只有这里使用root用户,每台机):
$ mkdir /data //存储数据的总目录
$ mkdir /data/spark //spark数据存储主目录
$ mkdir /data/spark/local //spark存储本地数据的目录
$ mkdir /data/spark/log //spark存储日志的目录
$ mkdir /data/spark/work //spark存储worker日志等信息的目录
$ chmod -R 777 /data/ //将/data目录权限设置为最大
4.3.1 配置spark-env.sh
Spark-env.sh文件中配置了spark运行时的一些环境、依赖项以及master和slaver的资源配置。
$ cd spark //进入spark目录
$ cp conf/spark-env.sh.template conf/spark-env.sh //将spark-env.sh.template复制一份为spark-env.sh

因为我们是部署standalone模式,可以参考配置文件中注释项的提示:



添加以下内容:
|
配置项 |
说明 |
|
SPARK_LOCAL_IP= 10.47.110.38 |
本机ip或hostname(不同主机配置不同) |
|
SPARK_LOCAL_DIRS=/data/spark/local |
配置spark的local目录 |
|
|
|
|
SPARK_MASTER_IP= 10.47.110.38 |
master节点ip或hostname |
|
SPARK_MASTER_WEBUI_PORT=8080 |
web页面端口 |
|
SPARK_WORKER_CORES=2 |
Worker的cpu核数 |
|
SPARK_WORKER_MEMORY=8g |
worker内存大小 |
|
SPARK_WORKER_DIR=/data/spark/work |
worker目录 |
|
|
|
|
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=4" |
spark-shell启动使用核数 |
|
export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.appDataTtl=604800" |
worker自动清理及清理时间间隔 |
|
|
|
|
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://systex/user/spark/applicationHistory" |
history server页面端口、备份数、log日志在HDFS的位置(注意,需要在HDFS上新建对应的路径) |
|
|
|
|
SPARK_LOG_DIR=/data/spark/log |
配置Spark的log日志目录 |
|
|
|
|
export JAVA_HOME=/usr/local/jdk/ |
配置java路径 |
|
export SCALA_HOME=/usr/local/scala/ |
配置scala路径 |
|
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop |
配置hadoop的lib路径 |
|
export HADOOP_CONF_DIR=/etc/hadoop/conf |
配置hadoop的配置路径 |
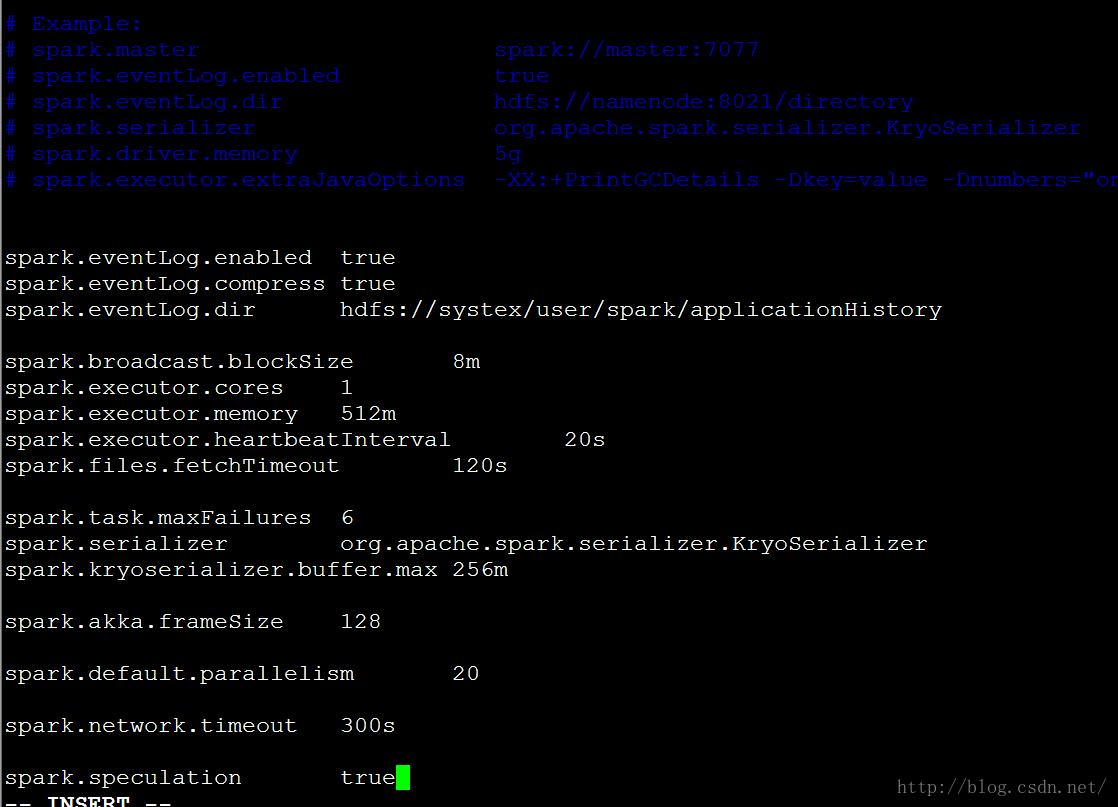
4.3.2 配置spark-defaults.conf
Spark-default.conf文件中主要配置的是与在spark上运行任务有关的一些参数,以及对executor等的配置。

添加以下内容:
|
配置项 |
说明 |
|
spark.eventLog.enabled true |
eventLog是否生效(建议开启,可以对已完成的任务记录其详细日志) |
|
spark.eventLog.compress true |
eventLog是否启用压缩(cpu性能好的情况下建议开启,以减少内存等的占用) |
|
spark.eventLog.dir hdfs://systex/user/spark/applicationHistory |
eventLog的文件存放位置,与spark-env.sh中的history server配置位置一致 |
|
|
|
|
spark.broadcast.blockSize 8m |
广播块大小 |
|
spark.executor.cores 1 |
Executor的cpu核数 |
|
spark.executor.memory 512m |
Executor的内存大小 |
|
spark.executor.heartbeatInterval 20s |
Executor心跳交换时间间隔 |
|
spark.files.fetchTimeout 120s |
文件抓取的timeout |
|
|
|
|
spark.task.maxFailures 6 |
作业最大失败次数(达到此次数后,该作业不再继续执行,运行失败) |
|
spark.serializer org.apache.spark.serializer.KryoSerializer |
设置序列化机制(默认使用java的序列化,但是速度很慢,建议使用Kryo) |
|
spark.kryoserializer.buffer.max 256m |
序列化缓冲大小 |
|
|
|
|
spark.akka.frameSize 128 |
Akka调度帧大小 |
|
|
|
|
spark.default.parallelism 20 |
默认并行数 |
|
|
|
|
spark.network.timeout 300s |
最大网络延时 |
|
|
|
|
spark.speculation true |
Spark推测机制(建议开启) |
4.3 配置slaves
在conf目录下有slaves文件,在其中配置slaves的hostname
$ cp conf/slaves.template conf/slaves
$ vim conf/slaves
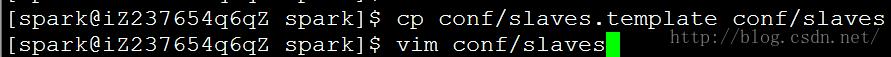
添加各个slave节点的hostname:

至此,我们就将spark需要配置的东西全部配置完成,将spark整个目录复制到其他主机:
$scp -r /home/spark/spark-1.6.0-bin-hadoop2.6 [email protected]:/home/spark/
$scp -r /home/spark/spark-1.6.0-bin-hadoop2.6 [email protected]:/home/spark/
$ scp -r/home/spark/spark-1.6.0-bin-hadoop2.6 [email protected]:/home/spark/
在相应的主机创建对应的spark软链接,并将spark-env.sh中SPARK_LOCAL_IP改为对应的ip即可。
5. 启动spark并测试(spark用户)
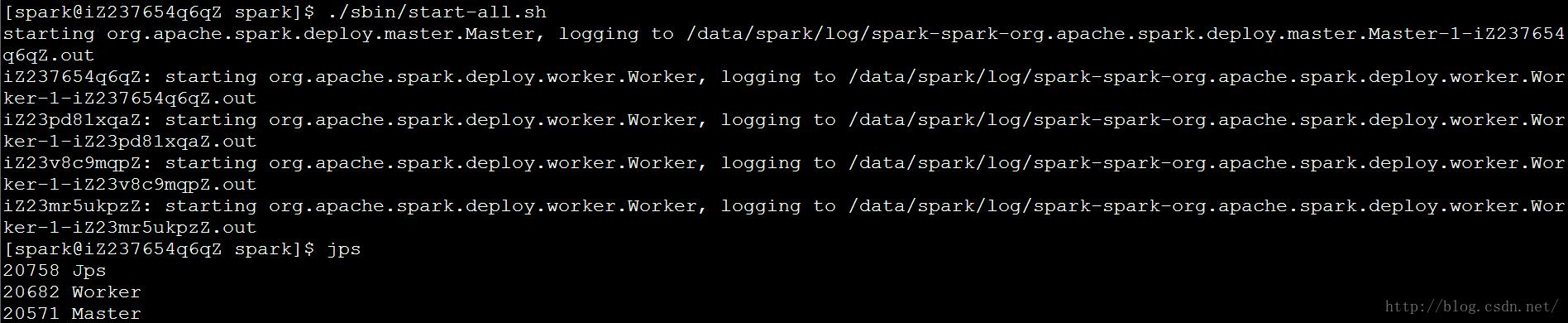
现在我们启动spark,在master节点执行以下命令:
$ cd /home/spark/spark
$ ./sbin/start-all.sh //启动master和slaves
$ ./sbin/start-history-server.sh //启动history server
使用jps命令查看是否成功启动:
检查进程是否启动【在master节点上出现“Master”,在slave节点上出现“Worker”】

## 监控页面URL http:// 120.27.153.137:8080/
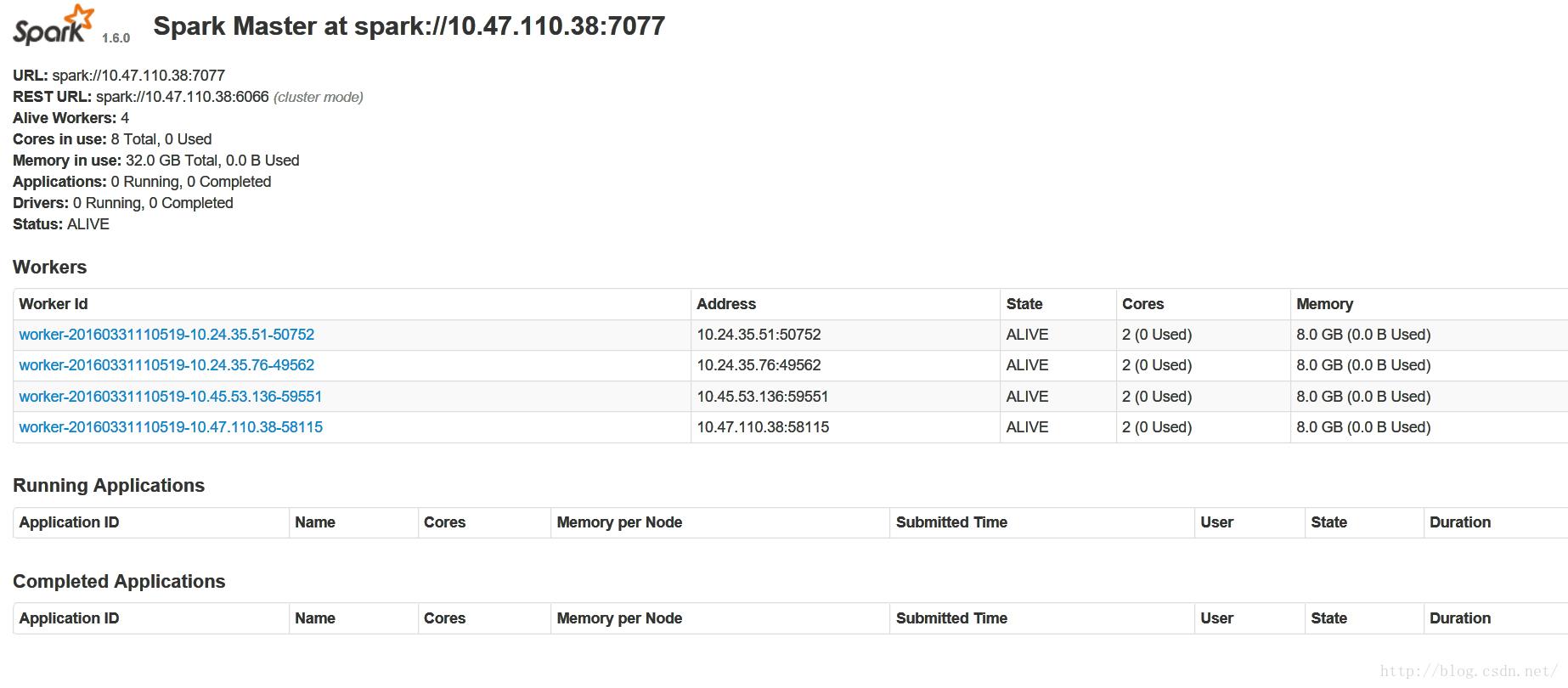
运行spark-pi:
spark-submit --master spark://10.47.110.38:7077 --classorg.apache.spark.examples.SparkPi --name Spark-Pi /home/spark/spark/lib/spark-examples-1.6.0-hadoop2.6.0.jar
能看到如下结果:


成功!
以上是关于spark1.6.0集群安装的主要内容,如果未能解决你的问题,请参考以下文章
Java Web提交任务到Spark Standalone集群并监控