R中的数据重塑函数
Posted 一周一paper,一周一技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R中的数据重塑函数相关的知识,希望对你有一定的参考价值。
1.去除重复数据
函数:duplicated(x, incomparables = FALSE, MARGIN = 1,fromLast = FALSE, ...),返回一个布尔值向量,重复数据的第一个为FALSE,其他为TRUE。
x可以是vector或data.frame。为data.frame时,数据的基本单位是行。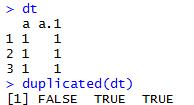
2.*apply系列
2.1以行或列为单位向函数传递参数:apply(X, MARGIN, FUN, ...),返回一个结果向量。
x是数据,可以是矩阵,数据框。margin是维度,在矩阵或数据框中,1表示行,2表示列。FUN是指定的函数。

2.2对vector,list的所有元素进行同样操作:lapply(X, FUN, ...,),返回一个等长度的list
x: vector 或list,其他对象会被转换为list(as.list)
fun:对每个元素进行操作的函数

2.3 对vector,matrix,data.frame内的元素进行同样处理,sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE),返回一个vector或matrix或list。
参数:
x是vector或matrix,返回vector。x是data.frame,返回matrix
simplify:结果是否简化为vector。TRUE,返回一个vector或matrix。FALSE,返回一个list。
USE.NAMES:T/F,输出的list是否需要colnames。

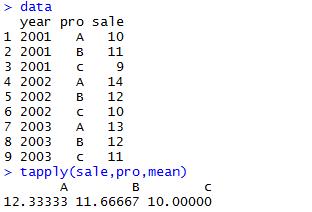
2.4 按列1分组,然后把列2作为参数传递给函数:tapply(x,index,fun,..,simplify)
x:要处理的数据列
index:要分组的数据列,要转换成factor
fun:对每组数据进行处理的函数
simplify:TRUE,返回array。FALSE,返回list
注意:tapply会自动把index的内容进行as.factor()
3.pylr包和dpylr包
4.把数据分组,然后用指定函数对每组进行统计操作。
函数:aggregate(x,by,fun),返回一个结果数据框。
x是数据框数据。by是按什么分类的list。fun是指定的函数,接受每类的列元素。

5.因子出现的频数
函数:table(...,exclude = if (useNA == "no") c(NA, NaN),useNA = c("no", "ifany", "always"),dnn = list.names(...), deparse.level = 1),返回一个table数据。
...:因子数据
exclude:不纳入统计的因子
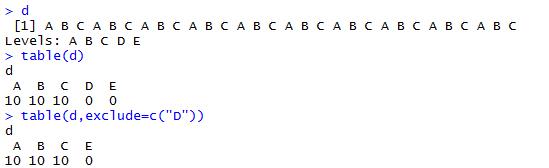
6.reshape2包
函数:melt(data, ..., na.rm = FALSE, value.name = "value")
data,要融合的数据。
by,要保留的数据列。一般说来是指能唯一确定每个测量所需的变量。
重铸melt数据,函数:dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL,subset = NULL, fill = NULL, drop = TRUE,value.var = guess_value(data))
data,融合数据
formula,想要的最后结果。
fun.aggregate,数据整合函数。
其他:一些有用的小函数
| 函数 | t() | replicate() | |||||||
| 用途 | 转置矩阵和数据框 | 重复调用多次函数 | |||||||
| 用法 | t(matrix or df) | replicate((n, expr, simplify = "array") | |||||||
| 返回 | 矩阵 | 向量 |
参考:
http://blog.sina.com.cn/s/blog_6caea8bf0100xkpg.html
以上是关于R中的数据重塑函数的主要内容,如果未能解决你的问题,请参考以下文章