kafka源码解析之九ReplicaManager
Posted 亮亮-AC米兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka源码解析之九ReplicaManager相关的知识,希望对你有一定的参考价值。
首先解释下2个名词:
AR(assignreplicas):分配副本 ISR(in-sync replicas):在同步中的副本,即下图:
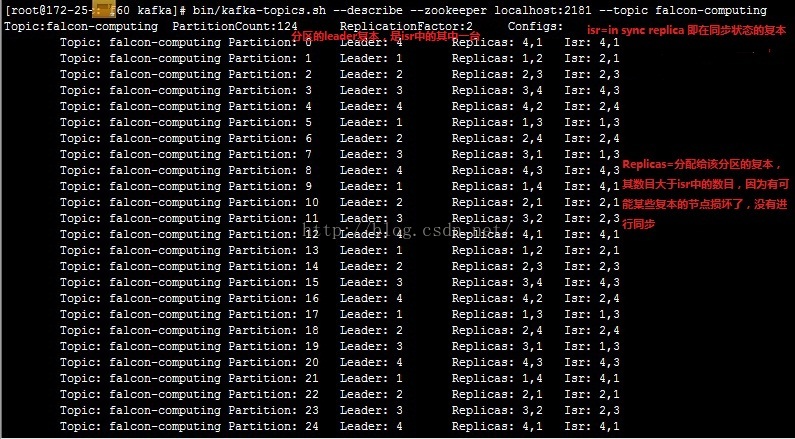
Partition {
topic : string //topic名称
partition_id : int //partition id
leader : Replica // 这个分区的leader副本,是isr中的其中一个
ISR : Set[Replica] // 正在同步中的副本集合
AR : Set[Replica] // 这个分区的所有副本分配集合,一个broker上有至多一个分区副本
LeaderAndISRVersionInZK : long // version id of the LeaderAndISR path; used for conditionally update the LeaderAndISR path in ZK
}
Replica { // 一个分区副本信息
broker_id : int
partition : Partition //分区信息
log : Log //本地日志与副本关联信息
hw : long //最后被commit的message的offset信息
leo : long // 日志结尾offset
isLeader : Boolean //是否为该副本的leader
}接下来来看ReplicaManager的主要作用,它的角色定位是负责接收controller的command以完成replica的管理工作,command主要有两种, LeaderAndISRCommand和StopReplicaCommand。因此主要完成三件事:
1)接受LeaderAndISRCommand命令 2)接受StopReplicaCommand命令 3)开启定时线程maybeShrinkIsr
,以便发现那些已经没有进行同步的复本
9.1 LeaderAndISRCommand处理流程
当KafkaServer接受到LeaderAndIsrRequest指令时,会调用ReplicaManager的becomeLeaderOrFollower函数
def becomeLeaderOrFollower(leaderAndISRRequest: LeaderAndIsrRequest,
offsetManager: OffsetManager): (collection.Map[(String, Int), Short], Short) = {
leaderAndISRRequest.partitionStateInfos.foreach { case ((topic, partition), stateInfo) =>
stateChangeLogger.trace("Broker %d received LeaderAndIsr request %s correlation id %d from controller %d epoch %d for partition [%s,%d]"
.format(localBrokerId, stateInfo, leaderAndISRRequest.correlationId,
leaderAndISRRequest.controllerId, leaderAndISRRequest.controllerEpoch, topic, partition))
}
replicaStateChangeLock synchronized {
val responseMap = new collection.mutable.HashMap[(String, Int), Short]
if(leaderAndISRRequest.controllerEpoch < controllerEpoch) { // 检查requset epoch
leaderAndISRRequest.partitionStateInfos.foreach { case ((topic, partition), stateInfo) =>
stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d since " +
"its controller epoch %d is old. Latest known controller epoch is %d").format(localBrokerId, leaderAndISRRequest.controllerId,
leaderAndISRRequest.correlationId, leaderAndISRRequest.controllerEpoch, controllerEpoch))
}
(responseMap, ErrorMapping.StaleControllerEpochCode)
} else {
val controllerId = leaderAndISRRequest.controllerId
val correlationId = leaderAndISRRequest.correlationId
controllerEpoch = leaderAndISRRequest.controllerEpoch
// First check partition's leader epoch
// 前面只是检查了request的epoch,但是还要检查其中的每个partitionStateInfo中的leader epoch
val partitionState = new HashMap[Partition, PartitionStateInfo]()
leaderAndISRRequest.partitionStateInfos.foreach{ case ((topic, partitionId), partitionStateInfo) =>
val partition = getOrCreatePartition(topic, partitionId)
val partitionLeaderEpoch = partition.getLeaderEpoch()
// If the leader epoch is valid record the epoch of the controller that made the leadership decision.
// This is useful while updating the isr to maintain the decision maker controller's epoch in the zookeeper path
// local的partitionLeaderEpoch要小于request中的leaderEpoch,否则就是过时的request
if (partitionLeaderEpoch < partitionStateInfo.leaderIsrAndControllerEpoch.leaderAndIsr.leaderEpoch) {
// 判断该partition是否被assigned给当前的broker
if(partitionStateInfo.allReplicas.contains(config.brokerId))
// 只将被分配到当前broker的partition放入partitionState,其中partition是当前的状况,partitionStateInfo是request中最新的状况
partitionState.put(partition, partitionStateInfo)
else {
stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d " +
"epoch %d for partition [%s,%d] as itself is not in assigned replica list %s")
.format(localBrokerId, controllerId, correlationId, leaderAndISRRequest.controllerEpoch,
topic, partition.partitionId, partitionStateInfo.allReplicas.mkString(",")))
}
} else {
// Otherwise record the error code in response
stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d " +
"epoch %d for partition [%s,%d] since its associated leader epoch %d is old. Current leader epoch is %d")
.format(localBrokerId, controllerId, correlationId, leaderAndISRRequest.controllerEpoch,
topic, partition.partitionId, partitionStateInfo.leaderIsrAndControllerEpoch.leaderAndIsr.leaderEpoch, partitionLeaderEpoch))
responseMap.put((topic, partitionId), ErrorMapping.StaleLeaderEpochCode)
}
}
//核心逻辑,判断是否为leader或follower,分别调用makeLeaders和makeFollowers
//case (partition, partitionStateInfo)中,partition是replicaManager当前的情况,而partitionStateInfo中间放的是request的新的分配情况,
//筛选出partitionsTobeLeader
val partitionsTobeLeader = partitionState
.filter{ case (partition, partitionStateInfo) => partitionStateInfo.leaderIsrAndControllerEpoch.leaderAndIsr.leader == config.brokerId}
//筛选出partitionsToBeFollower
val partitionsToBeFollower = (partitionState -- partitionsTobeLeader.keys)
// 如果是leader,则调用leader的流程
if (!partitionsTobeLeader.isEmpty)
makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, leaderAndISRRequest.correlationId, responseMap, offsetManager)
// 如果是follower,则调用follower的流程
if (!partitionsToBeFollower.isEmpty)
makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, leaderAndISRRequest.leaders, leaderAndISRRequest.correlationId, responseMap, offsetManager)
// we initialize highwatermark thread after the first leaderisrrequest. This ensures that all the partitions
// have been completely populated before starting the checkpointing there by avoiding weird race conditions
if (!hwThreadInitialized) {
// 启动HighWaterMarksCheckPointThread,hw很重要,需要定期存到磁盘,这样failover的时候可以往后load
startHighWaterMarksCheckPointThread()
hwThreadInitialized = true
}
//关闭idle的fether,如果成为leader,就不需要fetch
replicaFetcherManager.shutdownIdleFetcherThreads()
(responseMap, ErrorMapping.NoError)
}
}
}
主要是筛选出分配给该broker的partition的副本,并且根据lead是否为该brokerId区分为leader和follower,然后分别进入不同的流程
进入makeLeaders:
private def makeLeaders(controllerId: Int, epoch: Int,
partitionState: Map[Partition, PartitionStateInfo],
correlationId: Int, responseMap: mutable.Map[(String, Int), Short],
offsetManager: OffsetManager) = {
partitionState.foreach(state =>
stateChangeLogger.trace(("Broker %d handling LeaderAndIsr request correlationId %d from controller %d epoch %d " +
"starting the become-leader transition for partition %s")
.format(localBrokerId, correlationId, controllerId, epoch, TopicAndPartition(state._1.topic, state._1.partitionId))))
for (partition <- partitionState.keys)
responseMap.put((partition.topic, partition.partitionId), ErrorMapping.NoError)
try {
// First stop fetchers for all the partitions
//暂停该fetch线程
replicaFetcherManager.removeFetcherForPartitions(partitionState.keySet.map(new TopicAndPartition(_)))
partitionState.foreach { state =>
stateChangeLogger.trace(("Broker %d stopped fetchers as part of become-leader request from controller " +
"%d epoch %d with correlation id %d for partition %s")
.format(localBrokerId, controllerId, epoch, correlationId, TopicAndPartition(state._1.topic, state._1.partitionId)))
}
// Update the partition information to be the leader
//更新Partition中的属性
partitionState.foreach{ case (partition, partitionStateInfo) =>
partition.makeLeader(controllerId, partitionStateInfo, correlationId, offsetManager)}
} catch {
case e: Throwable =>
partitionState.foreach { state =>
val errorMsg = ("Error on broker %d while processing LeaderAndIsr request correlationId %d received from controller %d" +
" epoch %d for partition %s").format(localBrokerId, correlationId, controllerId, epoch,
TopicAndPartition(state._1.topic, state._1.partitionId))
stateChangeLogger.error(errorMsg, e)
}
// Re-throw the exception for it to be caught in KafkaApis
throw e
}
partitionState.foreach { state =>
stateChangeLogger.trace(("Broker %d completed LeaderAndIsr request correlationId %d from controller %d epoch %d " +
"for the become-leader transition for partition %s")
.format(localBrokerId, correlationId, controllerId, epoch, TopicAndPartition(state._1.topic, state._1.partitionId)))
}
}
进入makeFollowers
private def makeFollowers(controllerId: Int, epoch: Int, partitionState: Map[Partition, PartitionStateInfo],
leaders: Set[Broker], correlationId: Int, responseMap: mutable.Map[(String, Int), Short],
offsetManager: OffsetManager) {
partitionState.foreach { state =>
stateChangeLogger.trace(("Broker %d handling LeaderAndIsr request correlationId %d from controller %d epoch %d " +
"starting the become-follower transition for partition %s")
.format(localBrokerId, correlationId, controllerId, epoch, TopicAndPartition(state._1.topic, state._1.partitionId)))
}
for (partition <- partitionState.keys)
responseMap.put((partition.topic, partition.partitionId), ErrorMapping.NoError)
try {
var partitionsToMakeFollower: Set[Partition] = Set()
// TODO: Delete leaders from LeaderAndIsrRequest in 0.8.1
partitionState.foreach{ case (partition, partitionStateInfo) =>
val leaderIsrAndControllerEpoch = partitionStateInfo.leaderIsrAndControllerEpoch
val newLeaderBrokerId = leaderIsrAndControllerEpoch.leaderAndIsr.leader
leaders.find(_.id == newLeaderBrokerId) match {//只改变那些leader是available broker的partition
// Only change partition state when the leader is available
case Some(leaderBroker) =>
// 仅仅当partition的leader发生变化时才返回true,因为如果不变,不需要做任何操作
if (partition.makeFollower(controllerId, partitionStateInfo, correlationId, offsetManager))
partitionsToMakeFollower += partition
else
stateChangeLogger.info(("Broker %d skipped the become-follower state change after marking its partition as follower with correlation id %d from " +
"controller %d epoch %d for partition [%s,%d] since the new leader %d is the same as the old leader")
.format(localBrokerId, correlationId, controllerId, leaderIsrAndControllerEpoch.controllerEpoch,
partition.topic, partition.partitionId, newLeaderBrokerId))
case None =>
// The leader broker should always be present in the leaderAndIsrRequest.
// If not, we should record the error message and abort the transition process for this partition
stateChangeLogger.error(("Broker %d received LeaderAndIsrRequest with correlation id %d from controller" +
" %d epoch %d for partition [%s,%d] but cannot become follower since the new leader %d is unavailable.")
.format(localBrokerId, correlationId, controllerId, leaderIsrAndControllerEpoch.controllerEpoch,
partition.topic, partition.partitionId, newLeaderBrokerId))
// Create the local replica even if the leader is unavailable. This is required to ensure that we include
// the partition's high watermark in the checkpoint file (see KAFKA-1647)
partition.getOrCreateReplica()
}
}
//由于leader已发生变化,需要把旧的fetcher删除 ,因为它指向了旧的leader,从旧的leader fetch数据
replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(new TopicAndPartition(_)))
partitionsToMakeFollower.foreach { partition =>
stateChangeLogger.trace(("Broker %d stopped fetchers as part of become-follower request from controller " +
"%d epoch %d with correlation id %d for partition %s")
.format(localBrokerId, controllerId, epoch, correlationId, TopicAndPartition(partition.topic, partition.partitionId)))
}
//由于leader已发生变化,所以之前和旧leader同步的数据可能和新的leader是不一致的,但hw以下的数据,大家都是一致的,所以就把hw以上的数据truncate掉,防止不一致
logManager.truncateTo(partitionsToMakeFollower.map(partition => (new TopicAndPartition(partition), partition.getOrCreateReplica().highWatermark.messageOffset)).toMap)
partitionsToMakeFollower.foreach { partition =>
stateChangeLogger.trace(("Broker %d truncated logs and checkpointed recovery boundaries for partition [%s,%d] as part of " +
"become-follower request with correlation id %d from controller %d epoch %d").format(localBrokerId,
partition.topic, partition.partitionId, correlationId, controllerId, epoch))
}
if (isShuttingDown.get()) { //真正shuttingDown,就不要再加fetcher
partitionsToMakeFollower.foreach { partition =>
stateChangeLogger.trace(("Broker %d skipped the adding-fetcher step of the become-follower state change with correlation id %d from " +
"controller %d epoch %d for partition [%s,%d] since it is shutting down").format(localBrokerId, correlationId,
controllerId, epoch, partition.topic, partition.partitionId))
}
}
else {
// we do not need to check if the leader exists again since this has been done at the beginning of this process
val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map(partition =>
new TopicAndPartition(partition) -> BrokerAndInitialOffset(
leaders.find(_.id == partition.leaderReplicaIdOpt.get).get,
partition.getReplica().get.logEndOffset.messageOffset)).toMap
//增加新的fetcher,指向新的leader
replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)
partitionsToMakeFollower.foreach { partition =>
stateChangeLogger.trace(("Broker %d started fetcher to new leader as part of become-follower request from controller " +
"%d epoch %d with correlation id %d for partition [%s,%d]")
.format(localBrokerId, controllerId, epoch, correlationId, partition.topic, partition.partitionId))
}
}
} catch {
case e: Throwable =>
val errorMsg = ("Error on broker %d while processing LeaderAndIsr request with correlationId %d received from controller %d " +
"epoch %d").format(localBrokerId, correlationId, controllerId, epoch)
stateChangeLogger.error(errorMsg, e)
// Re-throw the exception for it to be caught in KafkaApis
throw e
}
partitionState.foreach { state =>
stateChangeLogger.trace(("Broker %d completed LeaderAndIsr request correlationId %d from controller %d epoch %d " +
"for the become-follower transition for partition %s")
.format(localBrokerId, correlationId, controllerId, epoch, TopicAndPartition(state._1.topic, state._1.partitionId)))
}
}9.2 StopReplicaCommand处理流程
当broker stop或用户删除某replica时,KafkaServer会接受到StopReplicaRequest指令,此时会调用ReplicaManager的stopReplicas函数:
def stopReplicas(stopReplicaRequest: StopReplicaRequest): (mutable.Map[TopicAndPartition, Short], Short) = {
replicaStateChangeLock synchronized {
val responseMap = new collection.mutable.HashMap[TopicAndPartition, Short]
if(stopReplicaRequest.controllerEpoch < controllerEpoch) {
stateChangeLogger.warn("Broker %d received stop replica request from an old controller epoch %d."
.format(localBrokerId, stopReplicaRequest.controllerEpoch) +
" Latest known controller epoch is %d " + controllerEpoch)
(responseMap, ErrorMapping.StaleControllerEpochCode)
} else {
controllerEpoch = stopReplicaRequest.controllerEpoch
// First stop fetchers for all partitions, then stop the corresponding replicas
// 先通过FetcherManager停止相关partition的Fetcher线程
replicaFetcherManager.removeFetcherForPartitions(stopReplicaRequest.partitions.map(r => TopicAndPartition(r.topic, r.partition)))
for(topicAndPartition <- stopReplicaRequest.partitions){
// 然后针对不同的 topicAndPartition stop 副本
val errorCode = stopReplica(topicAndPartition.topic, topicAndPartition.partition, stopReplicaRequest.deletePartitions)
responseMap.put(topicAndPartition, errorCode)
}
(responseMap, ErrorMapping.NoError)
}
}
}
stopReplica在很多情况下是不需要真正删除replica的,比如宕机
def stopReplica(topic: String, partitionId: Int, deletePartition: Boolean): Short = {
stateChangeLogger.trace("Broker %d handling stop replica (delete=%s) for partition [%s,%d]".format(localBrokerId,
deletePartition.toString, topic, partitionId))
val errorCode = ErrorMapping.NoError
getPartition(topic, partitionId) match {
case Some(partition) =>
if(deletePartition) { // 仅仅在deletePartition=true时,才会真正删除该partition
val removedPartition = allPartitions.remove((topic, partitionId))
if (removedPartition != null)
removedPartition.delete() // this will delete the local log
}
case None =>
// Delete log and corresponding folders in case replica manager doesn't hold them anymore.
// This could happen when topic is being deleted while broker is down and recovers.
if(deletePartition) {
val topicAndPartition = TopicAndPartition(topic, partitionId)
if(logManager.getLog(topicAndPartition).isDefined) {
logManager.deleteLog(topicAndPartition)
}
}
stateChangeLogger.trace("Broker %d ignoring stop replica (delete=%s) for partition [%s,%d] as replica doesn't exist on broker"
.format(localBrokerId, deletePartition, topic, partitionId))
}
stateChangeLogger.trace("Broker %d finished handling stop replica (delete=%s) for partition [%s,%d]"
.format(localBrokerId, deletePartition, topic, partitionId))
errorCode
}
9.3 maybeShrinkIsr处理流程
在启动的时候会开启maybeShrinkIsr任务供调度器调度,其主要作用是周期性检查isr中的SyncTime和SyncMessages来判断某些副本是否已经不在同步状态了。
def startup() { // start ISR expiration thread scheduler.schedule("isr-expiration", maybeShrinkIsr, period = config.replicaLagTimeMaxMs, unit = TimeUnit.MILLISECONDS) } private def maybeShrinkIsr(): Unit = { trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR") allPartitions.values.foreach(partition => partition.maybeShrinkIsr(config.replicaLagTimeMaxMs, config.replicaLagMaxMessages)) } def maybeShrinkIsr(replicaMaxLagTimeMs: Long, replicaMaxLagMessages: Long) { inWriteLock(leaderIsrUpdateLock) { leaderReplicaIfLocal() match { case Some(leaderReplica) => // getOutOfSyncReplicas获取不在同步状态的副本 val outOfSyncReplicas = getOutOfSyncReplicas(leaderReplica, replicaMaxLagTimeMs, replicaMaxLagMessages) if(outOfSyncReplicas.size > 0) { val newInSyncReplicas = inSyncReplicas -- outOfSyncReplicas assert(newInSyncReplicas.size > 0) info("Shrinking ISR for partition [%s,%d] from %s to %s".format(topic, partitionId, inSyncReplicas.map(_.brokerId).mkString(","), newInSyncReplicas.map(_.brokerId).mkString(","))) // update ISR in zk and in cache updateIsr(newInSyncReplicas) //把isr上传到zk // we may need to increment high watermark since ISR could be down to 1 maybeIncrementLeaderHW(leaderReplica) replicaManager.isrShrinkRate.mark() } case None => // do nothing if no longer leader } } }def getOutOfSyncReplicas(leaderReplica: Replica, keepInSyncTimeMs: Long, keepInSyncMessages: Long): Set[Replica] = { /** * there are two cases that need to be handled here - * 1. Stuck followers: If the leo of the replica hasn't been updated for keepInSyncTimeMs ms, * the follower is stuck and should be removed from the ISR * 2. Slow followers: If the leo of the slowest follower is behind the leo of the leader by keepInSyncMessages, the * follower is not catching up and should be removed from the ISR **/ val leaderLogEndOffset = leaderReplica.logEndOffset val candidateReplicas = inSyncReplicas - leaderReplica // Case 1 above // fetch的时候会更新logEndOffsetUpdateTimeMs val stuckReplicas = candidateReplicas.filter(r => (time.milliseconds - r.logEndOffsetUpdateTimeMs) > keepInSyncTimeMs) if(stuckReplicas.size > 0) debug("Stuck replicas for partition [%s,%d] are %s".format(topic, partitionId, stuckReplicas.map(_.brokerId).mkString(","))) // Case 2 above // 判断落后的messages数目 val slowReplicas = candidateReplicas.filter(r => r.logEndOffset.messageOffset >= 0 && leaderLogEndOffset.messageOffset - r.logEndOffset.messageOffset > keepInSyncMessages) if(slowReplicas.size > 0) debug("Slow replicas for partition [%s,%d] are %s".format(topic, partitionId, slowReplicas.map(_.brokerId).mkString(","))) stuckReplicas ++ slowReplicas }
以上是关于kafka源码解析之九ReplicaManager的主要内容,如果未能解决你的问题,请参考以下文章