post登录趴一趴百度贴吧美女
Posted py小蟒蛇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了post登录趴一趴百度贴吧美女相关的知识,希望对你有一定的参考价值。
本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励
在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie
爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
#-*- coding:utf-8 -*-
import urllib2
import re
import requests
from lxml import etree
这些是要导入的库,代码并没有使用正则,使用的是xpath,正则困难的童鞋可以尝试使用下
推荐各位先使用基本库来写,这样可以学习到更多
links=[] #遍历url的地址
k=1
print u\'请输入最后的页数:\'
endPage=int(raw_input()) #最终的页数 (r\'\\d+(?=\\s*页) 这是一个比较通用的正则抓取总页数的代码,当然最后要group
#这里是手动输入页数,避免内容太多
for j in range(0,endPage):
url=\'http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=\'+str(j) #页数的url地址
html=urllib2.urlopen(url).read() #读取首页的内容
selector=etree.HTML(html) #转换为xml,用于在接下来识别
links=selector.xpath(\'//div/a[@class="j_th_tit"]/@href\') #抓取当前页面的所有帖子的url
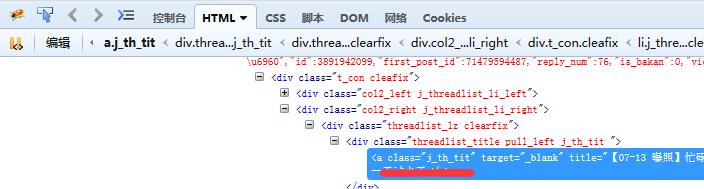
#大家可以使用浏览器自带的源码查看工具,在指定目标处查看元素,这样更快捷
for i in links:
url1="http://tieba.baidu.com"+i #因为爬取到的地址是相对地址,所以要加上百度的domain
html2=urllib2.urlopen(url1).read() #读取当前页面的内容
selector=etree.HTML(html2) #转换为xml用于识别
link=selector.xpath(\'//img[@class="BDE_Image"]/@src\') #抓取图片,各位也可以更换为正则,或者其他你想要的内容
#此处就是遍历下载
for each in link:
#print each
print u\'正在下载%d\'%k
fp=open(\'image/\'+str(k)+\'.bmp\',\'wb\') #下载在当前目录下 image文件夹内,图片格式为bmp
image1=urllib2.urlopen(each).read() #读取图片的内容
fp.write(image1) #写入图片
fp.close()
k+=1 #k就是文件的名字,每下载一个文件就加1
print u\'下载完成!\'
以上是关于post登录趴一趴百度贴吧美女的主要内容,如果未能解决你的问题,请参考以下文章
乐易贵宾VIP教程:百度贴吧 - QQ部落 - QQ空间 Post实战系列视频课程