高效延时消息设计与实现的场景
Posted chen_yong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高效延时消息设计与实现的场景相关的知识,希望对你有一定的参考价值。
背景
在自己接触到的业务系统中,很多地方会有定时任务的需求,比如支付的交易超时自动关闭、连接超时、支付异步通知等等。常见的做法有:
1.考虑使用JDK中的Timer定时任务来实现
2.通过封装quartz搭建专门的调度平台来管理
目前项目中运用的是第2种。
场景应用
看到netty中hashedwheeltimer原理,自己可以仿造一种数据结构,用来实现延时消息触发。
首先分析项目中哪些运用场景,通过延时的过程中数据的是否需要检测最终是否触发来划分静态的延时和动态的延时。
一、静态延时:不需要在延时的过程中判断是否触发定时任务,只是单纯地到指定时间触发任务即可,例如:交易成功通知业务系统。
二、动态延时:在延时的过程中并不是每个任务都需要执行,是有前提条件才能触发执行;例如:心跳检测,连接超时等。
场景一分析:支付成功异步通知
支付模块有一笔订单支付成功通知业务系统的定时任务,具体是支付流水交易如果支付成功了,那么由调度平台根据cron定义的时间来触发通知的任务。
假设支付流水表的结构为:t_jnl(jnl_no, pay_status,notify_status …),定时任务每一分钟执行一次:目前的场景可以简化为:
1.查询出支付成功的流水记录:select jnl_no from t_jnl where pay_status = 1 and notify_status =0;
2.调用业务系统接口,通知支付结果;
存在的问题:
①如果支付记录数很大,那么去查找满足条件的记录会造成数据库很大的压力。仅仅根据2个状态来查询的效率是很低的。
每次查询表数据,已经被执行过记录,仍然会被扫描(只是不会出现在结果集中),有重复计算的嫌疑。
②如果满足条件的支付流水足够多的话,至少每次不能一次性读取。需要分页查询,这将会是一个for循环。目前做法是定时任务触发时一次读取100条数据。
如果记录数超时定时任务中设定的数量(100),那么在后面的记录不会再本次中得到执行。
③假如一条记录恰好在刚执行任务后0.1s满足条件了(pay_status = 1),那么几乎要等待下一个周期被执行,时效性不好。误差时间有可能就是cron的设置时间t。
场景一改造:(静态延时)
为了解决上述场景存在的问题,引入下面的设计:右侧是通过一个数组进行封装的环形队列,类似一个时钟。根据cron来设置环形队列的segment,理解为一个独立的任务单元。左侧是每个任务单元的结构实现:set<Task>
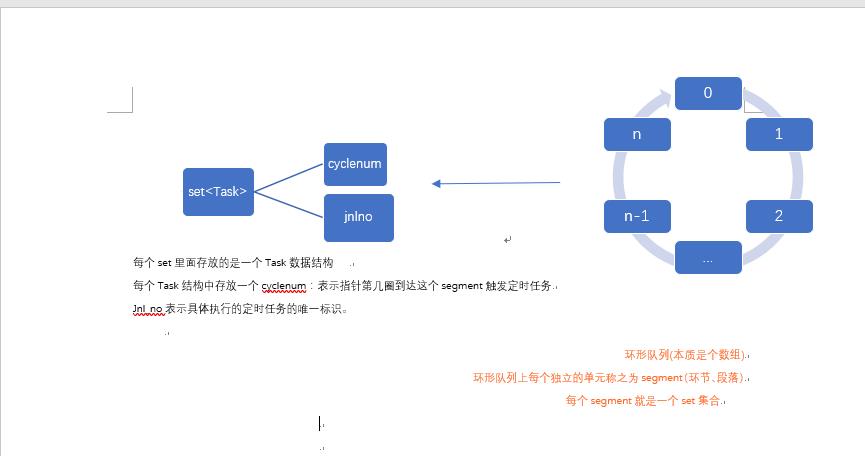
以当前场景为例,cron设置时间t=60s,n=60,后台启动一个timer,这个timer每隔1s,在上述环形队列中移动一格,有一个Current Index指针来标识正在检测的segment。
那么改造的场景变为:
1.在支付成功后根据current Index所在位置和cron设置周期确认在环形队列上的segment下标和cyclenum后将数据插入环形队列中。
假设 current Index = 3,想要在60s后执行,数据插入第3+60=63个节点,但是环形队列最大长度为60,所以cyclenum=63/60=1,segment=3
2.task function是具体执行延时任务的方法
假设异步通知业务系统的方法为syncOrder(jnl_no) ,通知业务系统这笔流水支付成功了。
3.后台一致启动一个Timer,每隔t/n时间段,current index移动一个segment,当移动到当前的segment时候,渠道set<Task>中的cyclenum,
判断是否为0,如果cyclenum=0,立即执行task function(jnlno)(可以用单独的线程来执行Task),并把这个Task从Set<Task>中删除,否则cyclenum -1。等待下个周期。
结论分析:
(1)无需与数据库进行交互,不用再轮询全部订单,效率高
(2)时效性好,精确到秒(设置timer的移动频率t和segment数量n可以控制精度)
(3)但是需要考虑数据量大的时候内存吃紧的情况(可以通过t/n的频率来减少内存中缓存的数据)。
场景二分析:支付成功但通知失败后进行重复通知策略
在上面的"支付成功通知"场景中会去异步通知业务系统,根据业务系统响应后修改通知状态.有时候会出现业务系统宕机或者超时的情况,遇到此种问题需要再次发起通知。
1.系统目前的解决办法是:查询出支付成功但通知失败的流水记录:select jnl_no from t_jnl where pay_status = 1 and notify_status =2;
2.再次调用业务系统接口,通知支付结果;
3.修改对应的通知状态,如果通知成功后续不会再通知,失败还会发起通知。
存在的问题:
①如果“支付成功但通知失败”记录很少,那么去查找的时候已经通知成功的记录仍然会被扫描,只为查询少量数据但需要全盘扫描其实资源就被浪费了。
②假如一条记录恰好在刚执行任务后0.1s满足条件了,那么几乎要等待下一个周期t=5min被执行,时效性不好。误差时间有可能就是周期t。
场景二改造:(动态延时)
之所以是动态延迟是因为并不是每次通知的结果都需要延迟执行任务,只有通知失败才会有后续的延时任务。
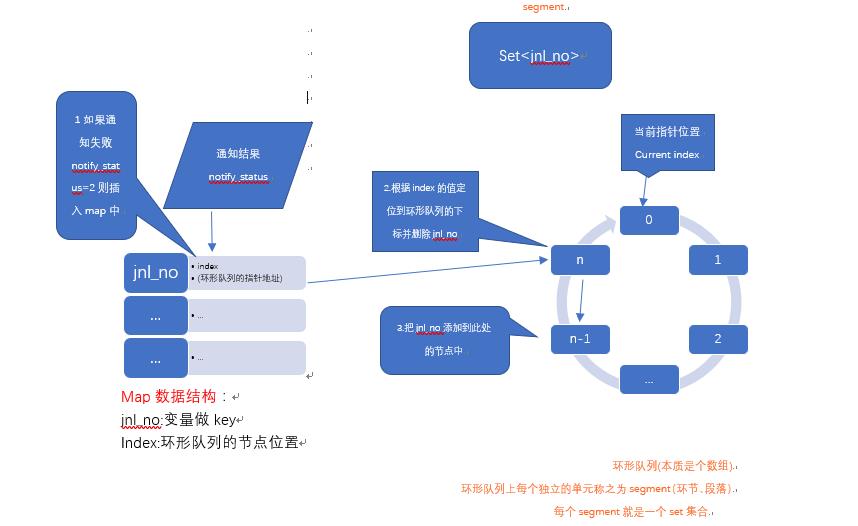
以当前场景为例,首先在场景一中调用定时任务中的异步通知方法,如果通知失败后将syncOrder(jnl_no)的流水号jnl_no存入Map数据中,将对应的环形队列的下标存入Map的值。
cron设置时间t=300s,n=60,后台启动一个timer,这个timer每隔5s,在上述环形队列中移动一格,有一个Current Index指针来标识正在检测的segment。
那么改造的场景变为:
1.假设current index指向segment=3的时候,执行通知但结果失败,先确认该流水下次在队列上的index = current index -1 = 2 ,到下一次被执行刚好300s.
所以map.put(jnl_no,2),同时把curent index指向的节点从数据删除。
2.隔了300s后上一步的segment会被current index读取,执行通知任务,如果执行成功,把map中的数据删除掉,执行失败继续按照上一步步骤进行。
哪些元素是通知失败的呢?
Current Index每秒种移动一个segment,这个segment对应的Set<jnl_no>中所有jnl_no都应该被执行!如果最近500s有通知失败的,一定被放到Current Index的前一个segment了,Current Index所在的segment对应Set中所有元素,都是通知失败的。所以,当没有通知失败时,Current Index扫到的每一个segment的Set中应该都没有元素。
结论分析:
相对项目中目前的优势:
(1)只需要1个timer即可,无需数据库交互,全局搜索。
(2)批量通知,Current Index扫到的segment,Set中所有元素都应该被重新发起通知。
除开上面目前项目中运用的方法,还有其他的一些办法,来进行比较下。
“轮询扫描法”
1)用一个Map<jnl_no, last_notify_time>来记录每一个jnl_no最近一次通知时间last_notify_time
2)当某个用户jnl_no通知失败时,实时更新这个last_notify_time
3)启动一个timer,当Map中不为空时,轮询扫描这个Map,看每个jnl_no的last_notify_time是否超过500s,如果超过500s进行超时再次通知。
“多timer触发法”
1)用一个Map<jnl_no, last_notify_time>来记录每一个jnl_no最近一次请求时间last_notify_time
2)当某个jnl_no有通知失败,实时更新这个Map,并同时对这个jnl_no启动一个timer,500s之后触发
3)每个jnl_no对应的timer触发后,看Map中,查看这个jnl_no的last_notify_time是否超过500s,如果超过则进行通知处理
方案一:只启动一个timer,但需要轮询,效率较低
方案二:不需要轮询,但每个请求包要启动一个timer,比较耗资源
以上是关于高效延时消息设计与实现的场景的主要内容,如果未能解决你的问题,请参考以下文章