外部排序归并排序 败者树
Posted 向前爬的蜗牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了外部排序归并排序 败者树相关的知识,希望对你有一定的参考价值。
一、定义问题
外部排序指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存,需要在内存和外部存储器之间进行多次数据交换,以达到排序整个文件的目的。外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装入内存的部分,分别把每一部分调入内存完成排序。然后,对已经排序的子文件进行多路归并排序。
二、处理过程
(1)按可用内存的大小,把外存上含有n个记录的文件分成若干个长度为L的子文件,把这些子文件依次读入内存,并利用有效的内部排序方法对它们进行排序,再将排序后得到的有序子文件重新写入外存;
(2)对这些有序子文件逐趟归并,使其逐渐由小到大,直至得到整个有序文件为止。
先从一个例子来看外排序中的归并是如何进行的?
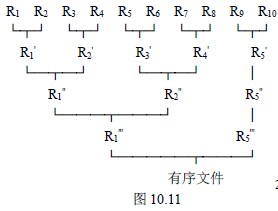
假设有一个含10000 个记录的文件,首先通过10 次内部排序得到10 个初始归并段R1~R10 ,其中每一段都含1000 个记录。然后对它们作如图10.11 所示的两两归并,直至得到一个有序文件为止 如下图
三 、多路归并排序算法以及败者树
多路归并排序算法在常见数据结构书中都有涉及。从2路到多路(k路),增大k可以减少外存信息读写时间,但k个归并段中选取最小的记录需要比较k-1次,为得到u个记录的一个有序段共需要(u-1)(k-1)次,若归并趟数为s次,那么对n个记录的文件进行外排时,内部归并过程中进行的总的比较次数为s(n-1)(k-1),也即(向上取整)(logkm)(k-1)(n-1)=(向上取整)(log2m/log2k)(k-1)(n-1),而(k-1)/log2k随k增而增因此内部归并时间随k增长而增长了,抵消了外存读写减少的时间,这样做不行,由此引出了“败者树”tree of loser的使用。在内部归并过程中利用败者树将k个归并段中选取最小记录比较的次数降为(向上取整)(log2k)次使总比较次数为(向上取整)(log2m)(n-1),与k无关。
败者树是完全二叉树,因此数据结构可以采用一维数组。其元素个数为k个叶子结点、k-1个比较结点、1个冠军结点共2k个。ls[0]为冠军结点,ls[1]--ls[k-1]为比较结点,ls[k]--ls[2k-1]为叶子结点(同时用另外一个指针索引b[0]--b[k-1]指向)。另外bk为一个附加的辅助空间,不属于败者树,初始化时存着MINKEY的值。
多路归并排序算法的过程大致为:
1):首先将k个归并段中的首元素关键字依次存入b[0]--b[k-1]的叶子结点空间里,然后调用CreateLoserTree创建败者树,创建完毕之后最小的关键字下标(即所在归并段的序号)便被存入ls[0]中。然后不断循环:
2)把ls[0]所存最小关键字来自于哪个归并段的序号得到为q,将该归并段的首元素输出到有序归并段里,然后把下一个元素关键字放入上一个元素本来所在的叶子结点b[q]中,调用Adjust顺着b[q]这个叶子结点往上调整败者树直到新的最小的关键字被选出来,其下标同样存在ls[0]中。循环这个操作过程直至所有元素被写到有序归并段里。
四、伪代码:
void Adjust(LoserTree &ls, int s)
/*从叶子结点b[s]到根结点的父结点ls[0]调整败者树*/
{ int t, temp;
t=(s+K)/2; /*t为b[s]的父结点在败者树中的下标,K是归并段的个数*/
while(t>0) /*若没有到达树根,则继续*/
{ if(b[s]>b[ls[t]]) /*与父结点指示的数据进行比较*/
{ /*ls[t]记录败者所在的段号,s指示新的胜者,胜者将去参加更上一层的比较*/
temp=s;
s=ls[t];
ls[t]=temp;
}
t=t/2; /*向树根退一层,找到父结点*/
}
ls[0]=s; /*ls[0]记录本趟最小关键字所在的段号*/
}
void K_merge( int ls[K])
/*ls[0]~ls[k-1]是败者树的内部比较结点。b[0]~b[k-1]分别存储k个初始归并段的当前记录*/
/*函数Get_next(i)用于从第i个归并段读取并返回当前记录*/
{ int b[K+1),i,q;
for(i=0; i<K;i++)
{ b[i]=Get_next(i); /*分别读取K个归并段的第一个关键字*/ }
b[K]=MINKEY; /*创建败者树*/
for(i=0; i<K ; i++) /*设置ls中的败者初值*/
ls[i]=K;
for(i=K-1 ; i>=0 ; i--) /*依次从b[K-1]……b[0]出发调整败者*/
Adjust(ls , i); /*败者树创建完毕,最小关键字序号存入ls[0]
while(b[ls[0]] !=MAXKEY )
{ q=ls[0]; /*q为当前最小关键字所在的归并段*/
prinftf("%d",b[q]);
b[q]=Get_next(q);
Adjust(ls,q); /*q为调整败者树后,选择新的最小关键字*/
}
}
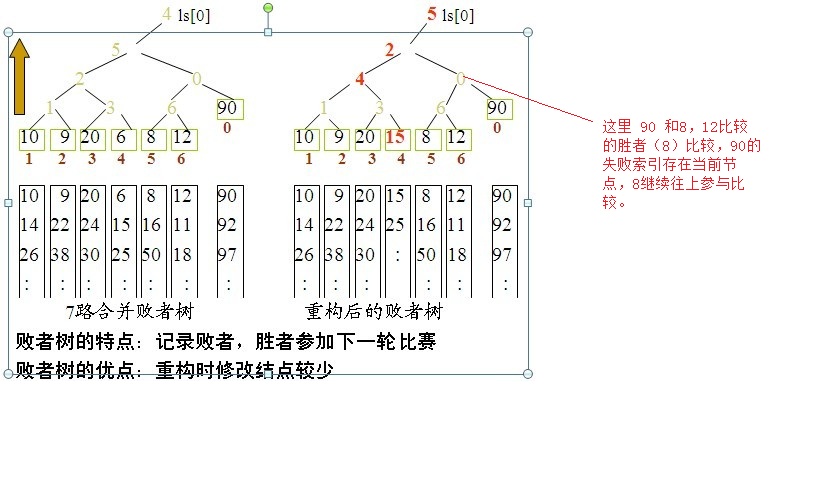
如下图,一个详细的过程。2个子结点比较后的败者放入它们的父结点,而胜者送到它们父结点的父节点去再作比较,这才是败者树。b[0]放的是最终的胜者。
五、 小结
最后,对使用多路归并排序来进行外部排序的过程大致描述一下:根据有限的内存资源将大文件分为L个段,然后依次将这L个段读入内存并利用高效的内部排序算法对每个段进行排序,排序后的结果即为初始有序归并段直接写入外存文件。内部排序时要选择合适的排序算法,并且要考虑到内部排序需要的辅助空间以及有限的内存空间来决定究竟要把大文件分为几个段。接下来选择合适的路数k对这L个归并段进行多路归并排序,每一趟归并使k个归并段变为1个较大归并段写入文件,反复几趟归并后得到整个有序的文件。在多路归并过程中,内存空间只需要维护一个大小为2k的败者树,数据取、放都是对应外存的读写,这样的话一次把一大块数据读入内存、把内存中排好的一大块数据写入文件比较省时,不知这个需要程序员编程安排还是OS能通过虚拟页面文件直接帮忙做到。找出计算机组成原理的课本回顾下发现,自认为用虚拟页面文件管理解决这个问题完全是风马牛不相及的。段页式虚拟存储是将程序的逻辑空间以段页式来管理,而要排序的文件不属于程序本身的逻辑空间。实际上,这个问题应该从磁盘本身提供的高速缓存方面来考虑。现在磁盘一般都有几M到十几M的高速缓存,利用数据访问的空间局部性和时间局部性规则,使用预读策略,一次性将一块数据读入高速缓存,再次读写时则先检查cache中是否能够命中,如能命中则不需去盘片上读。若cache空间不足以提高读写速率,则需要程序员编写程序将大块数据读入写出。
以上是关于外部排序归并排序 败者树的主要内容,如果未能解决你的问题,请参考以下文章